I’ve ran through the different options of binning nodes in Knime and could not find a workaround on my challenge. Hopefully someone can help with this.
I have a table of 3 columns as such:
INPUT A:
quantity
group name
cumulative aggregate
2
A
2
333
B
335
100
B
435
5555
D
5990
11
X
6001
0
B
6001
80
A
6081
1000
R
7081
1111
Y
8192
I want to create an equal-width bin groups in 1000’s, except for the remaining values which will be the last row, as such:
OUTPUT A:
bins
initial group
ending group
1000
A
A
1000
A
A
1000
A
A
1000
A
A
1000
A
A
1000
A
D
1000
D
R
1000
R
Y
192
Y
Y
Here’s some context:
There are no missing values in any cell.
The initial group name comes from the first group name each time we first started counting from 0 to 1000.
The last group name is simply the last group we ended up with on the 1000th count (or the remainder).
Here’s another scenario of an input and output table, following similar rules as above:
INPUT B:
quantity
group name
cumulative aggregate
5000
C
5000
0
X
5000
0
H
5000
100
V
5100
500
C
5500
20
D
5520
10000
X
15520
OUTPUT B:
bins
initial group
ending group
1000
C
C
1000
C
C
1000
C
C
1000
C
C
1000
C
H
1000
H
X
1000
X
X
1000
X
X
1000
X
X
1000
X
X
1000
X
X
1000
X
X
1000
X
X
1000
X
X
1000
X
X
520
X
X
Let me know if you need anything else, thanks a lot!
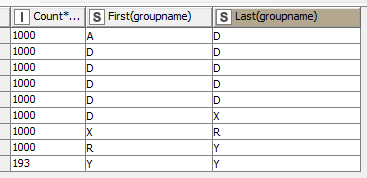
Hi @ActionAndi , basically one bin contains 1000. So, for input A, the first 1000 is from Row 1-Row 4 (looking at the cumulative aggregate as reference). Since Row 4 has a cumulative aggregate of 5990 and ends at Group Name D, it produces the first 5 rows of the output table. So the remaining 990 from that 5990 is carried forward to the next row, so that explains Row 6’s ending group being D, and Row 1-Row 5 ending group being A.
So first row of output A is quantity 0-1000, starting with A and should end with D, as the ■■■ sum of A/B is below 1000. So some items of D must be used.
But why it ends on A?
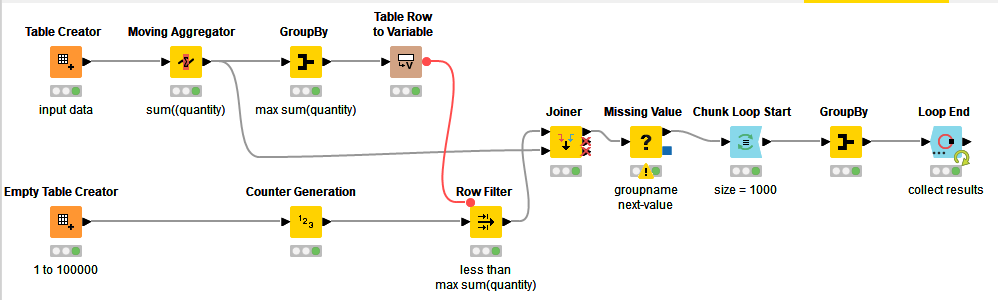
First I did something with the Recursive Loop, but that ended up in een wf way to complex. So my suggestion is to create a dummy dataset with e.g. 100000 rows (you never know in advance how many you need). And join your dataset with the dummy dataset. Input the missing, and process chuncks of a 1000 records.
Update: So I’ve run a diagnostic inspection on why @HansS output tables differ slightly from the 2 expected outcomes I wanted. The issue with that proposed solution surfaces whenever the chunk iteration encounters duplicating rows of cumulative aggregate.
It’s a super elegant solution due to its closeness to the expected outcome, and I’m sure it works well for cases where the quantity rows have no zero values (so as not to produce duplicate rows in the cumulative aggregate column). If that’s the case I would have used it as solution.
Unfortunately its concept design does not suit the nature of my dataset
Hi @badger101 , are you absolutely sure that your latest expected output is correct?
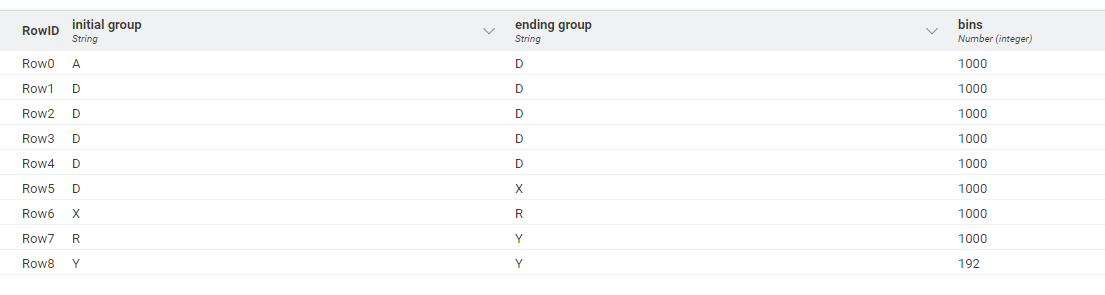
I have a workflow that attempts to calculate this without using any loops or scripting nodes, but the output I get is very similar to @HansS , in terms of group start and end. The difference is that my final bin is 192 items.
I believe the bin on “Row6” should end with “X” and not “R”. In your original table the cumulative aggregate at the end of group D is 5990, so the first 5000 will have been allocated to 5 bins, leaving 990 items. The following group is Group X which has 11 items. So the next bin will be filled with 990 D plus 11 X which means the group ends at X.
Row5... Start: D End: X
I believe that the fact that there are 0 B is irrelevant in this case, since there is 1 X remaining, so the following group starts with X, and when the cumul aggr gets to 7000 we are in group R so it will begin at X and end with R.
Row6... Start: X End: R
If I do this manually, this is how I see the allocation of groups to bins
when I corrected the Output Table A, I did it manually simply by replacing the “incorrect” values with the “correct values”, without consulting with the after-effects on the initial group.
So here’s the final correction of the Output Table A:
Comparing my new table to @HansS now, it seems that his table did everything correct except for the final row. Apologies @HansS .
That’s true, so after reading that comment, I came up with the final revised table as shown above.
So, comparing your table to mine, your workflow should be valid, at least for Input A. Can you test your workflow on Input B for me? I’ve double checked on Output B and there should be no ammendment for that one.
P/S: I’m also working on my own solution as we speak.
Your table B has an incorrect cumulative aggregation as it has only added 400 from V to C instead of 500, but apart from that my results match. The last bin should be 620 and not 520.
My workflow doesn’t use any loops or scripting nodes and is suitable as long as your quantities don’t get excessively large, because it actually does it by generating a table with a row for every item, then simply grouping them into 1000s. So this will work easily provided you don’t have huge quantities.
If you do have a much larger data set where the total quantity across all rows becomes excessive (in terms of memory requirements) for this approach, it can potentially still be used, in a recursive loop where it would process only so many rows at a time, or maybe every time the cumulative aggregation exceeds say 50,000 it would process those rows and then carry the “remaining bin” over into the next group of rows. If you need further ideas on that (if it is necessary) I can have a further play with it.
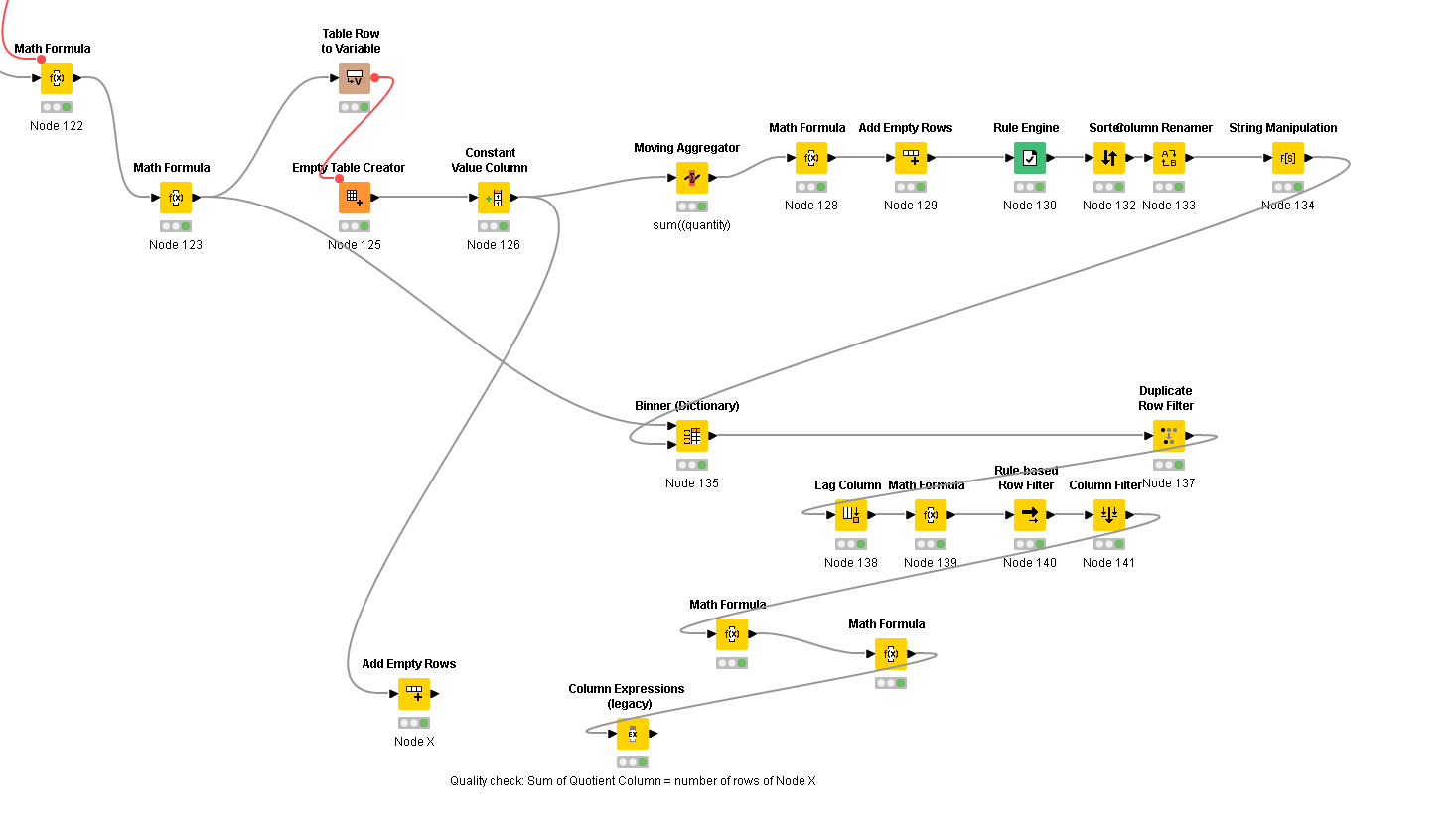
Anyway, for the current “simple” scenario, please see this demo workflow on the hub:
(KNIME 5.3.2)
edit: I just tested the theory with a total cumulative quantity of 16 million, and whilst it slowed a bit (especially on the final groupby), it didn’t particularly have issues, and still got there relatively quickly.
Yes the cumulative aggregate has a small mistake in calculation - thanks for letting me know.
I have just checked the proposed solution. Our output A tables match to one another perfectly. I also noticed one minor mismatch for Output B, since my Row 5 started with Group H and yours with Group V. And I was about to point that out, but upon second contemplation, it should start with V since the previous bin capacity has been exhausted.
So, I think there should be no issue if I use your solution. Thank you very much @takbb !!
Great glad it helps @badger101 . I hadn’t spotted the H/V difference in the outputs myself, so good that you were able to verify it was ok, and thanks for marking the solution!
@takbb Oh by the way, by any chance is there an alternative Node (doesn’t matter if it’s a programming snippet node or a standard no-code node) to the One Row to Many? It seems to need an integer column, and my real dataset needs to be forced to Double type, so I can’t feed it into the node.
I don’t know of one @badger101 . There aren’t actually that many nodes that can generate new rows,and from memory the scripting nodes (with exception of python) cannot increase the row count.
One row to many is a very fast node too and whilst looping could potentially be used to increase the row count it would be vastly less performant.
In my workflow I think I use the rule engine to create a new int column called expandedrows, or something like that. Can you not also create a new int column for the purpose? Then it shouldn’t matter that the original qty column was a double.
That was really tricky and @takbb solution is so smart.
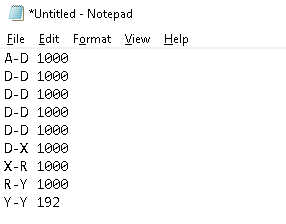
But anyways as I created my own solution I share it too. Maybe this helps as well.
I was hoping that I can avoid looping, but I didnt know how to create a list with start/end like in Python (range(1:5))
Thanks @ActionAndi ! Both yours and @HansS did well on Output A, but for Output B they were far off. But I really appreciate it! I’m currently working on my own workaround, since I just realized that my quantity column could take a value of more than 1 billion, something I should’ve pointed out very early on.