As I am new to KNIME, I am experimenting a lot.
I am trying to implement a group by step and I would like to count the unique values of a column. My data set is quit huge (51m rows). I get the following message:
"warn group by 3:177:78 skipped groups): “group contains too many unique values”
What exactly I need to configure in the “Group by” node to get the number of unique values and not missing?
Thanks
C.
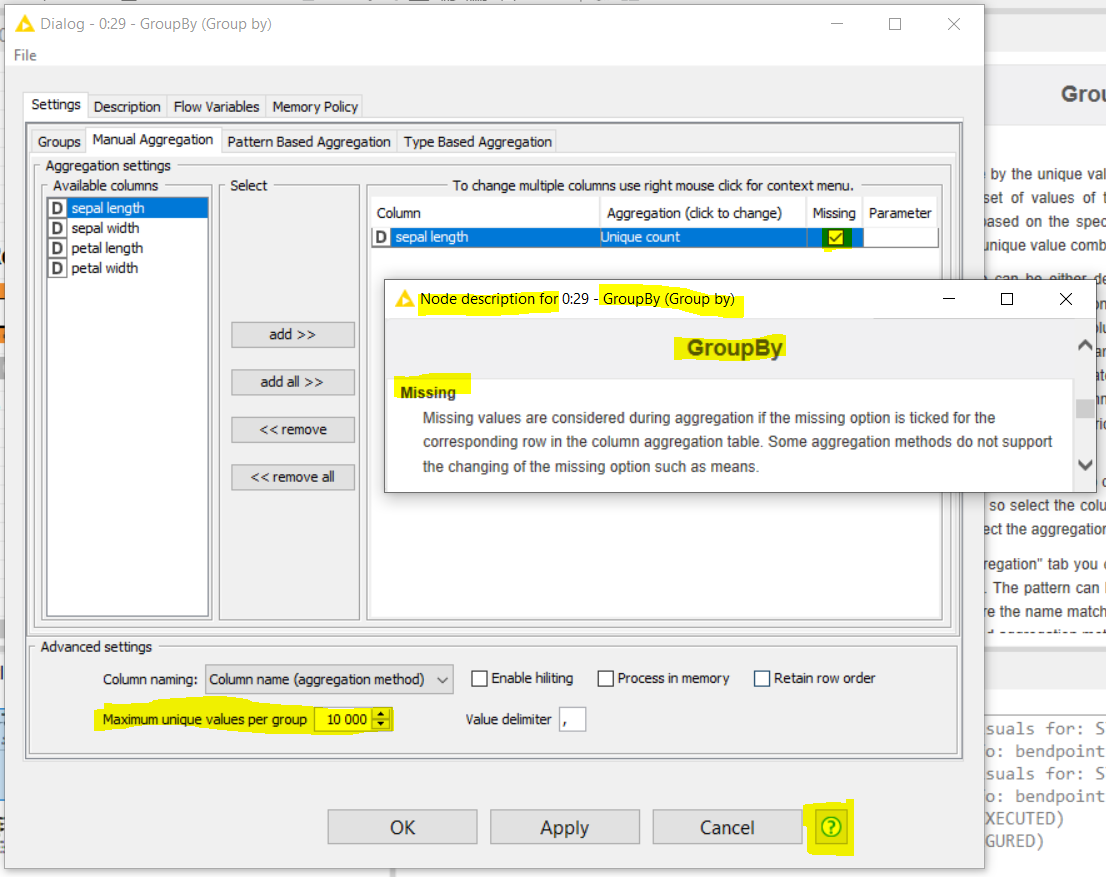
There is an option in most of the aggregation functions in the -GroubBy- node which allows the selected aggregation function to take into account (or not) the missing values.
The -GroupBy- aggregation should not take into account missing values when this option is not ticked, as explained in the help of the node configuration:
Maybe you would need too to set a higher number of “maximum unique values per group” in your node configuration to adapt it to the huge amount of rows of your input table. By default, this maximum is set to “10000”. You could here set it to millions if needed.