@janszky_nav I would suggest you toy around with the workflow read the comments and the links. I was not able to extract the PDF from the word file but used the file you posted earlier (Text mining from PDF documents and results places - #6 by janszky_nav).
I placed your PDF file in the /data/ folder of the node and searched for it in order to create the paths. If you have more than one PDF they would all be processed. The paths are also fed to R so no need to enter them manually. You also do not need much R knowledge just set it up (Data separate and melting - #9 by mlauber71, How to read multiple lines from PDF File - #12 by mlauber71). If you want to use some advanced tools a little setup efforts will help you a great deal and give you further skills and options ![]() - I may add an environment propagation later.
- I may add an environment propagation later.

the top loop would simply extract all text from the PDF mark the pages where it is from and save the content in a CSV file and a KNIME table so you could later do some extractions.
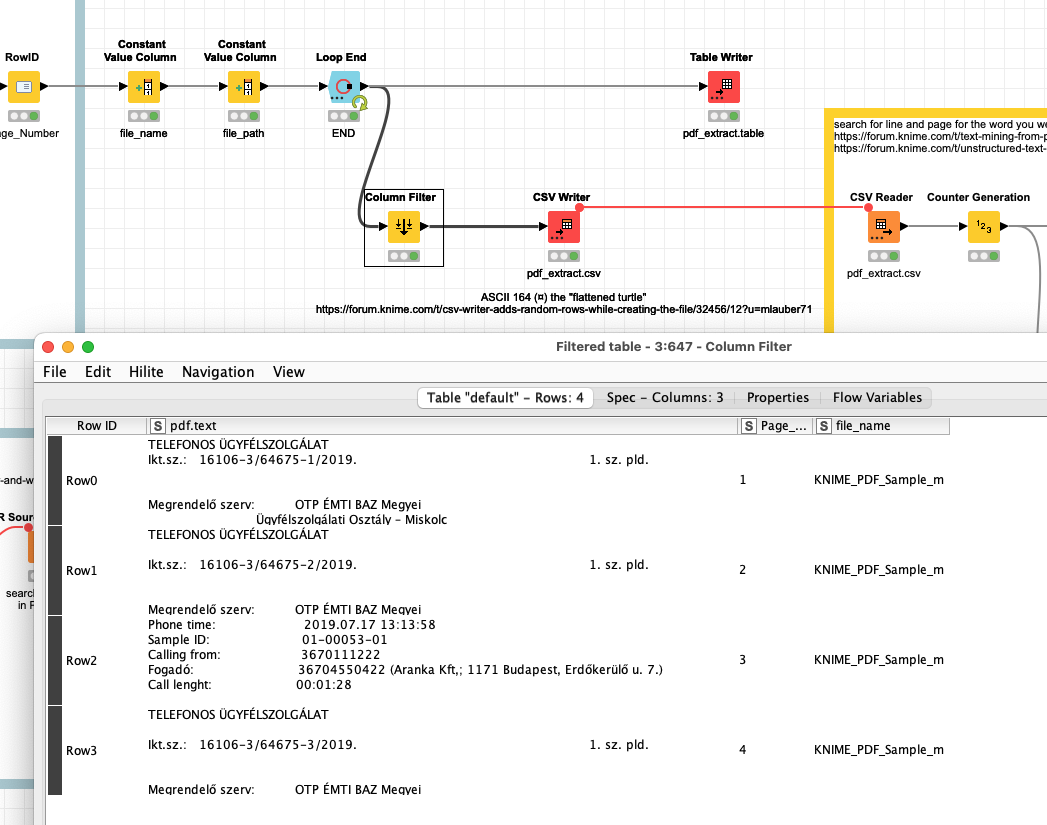
The part on the left would take a search word (“A jogosult ügy”) and list all the pages and lines where you could find the word and keep the lines. If you then want to extract further information from this key word (behind etc.) you will also be able to do that - I think there have been other threads handling this.

You can download the workflow here (I might add some things later):
That is it for know. I have to go. Maybe you check it out and we can continue this later ![]()