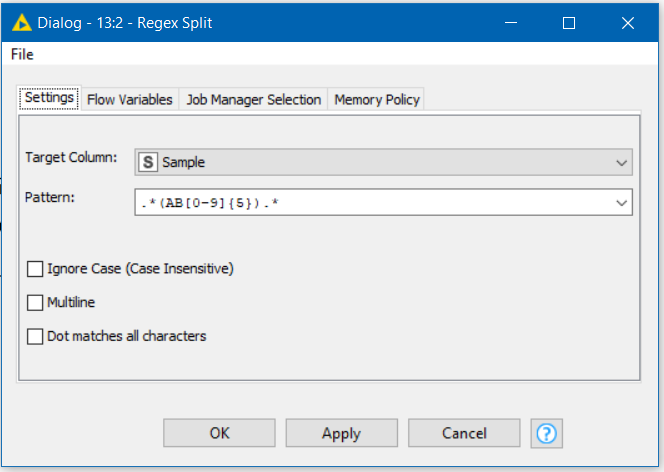
I am trying to extract the number of some documents that resides in a ununiform cell. I would need to extract from AB till the end of the five digit number. I wrote three examples of the cells in the table below. I have tried with the cell splitter but I can’t seem to work out how to do it. Do you have any suggestions of the nodes I need to use.
Workflow started - AB55555-request
Workflow started change to AB51613 - request
Workflow started -AB65243 request