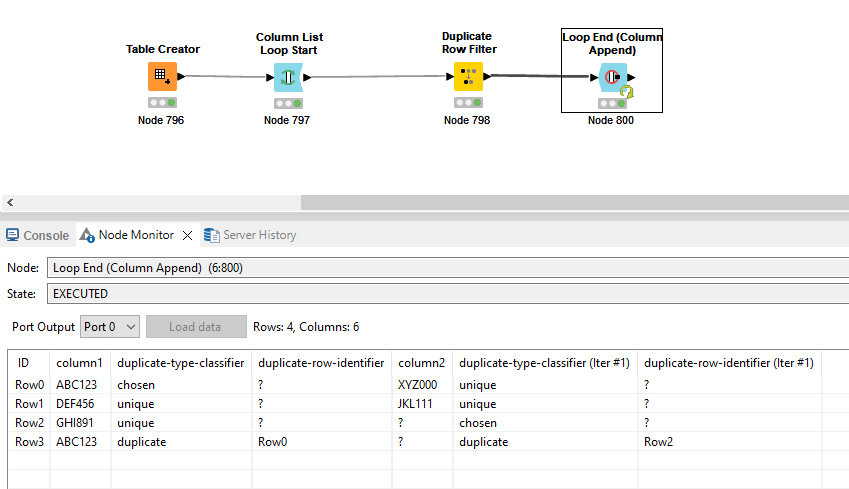
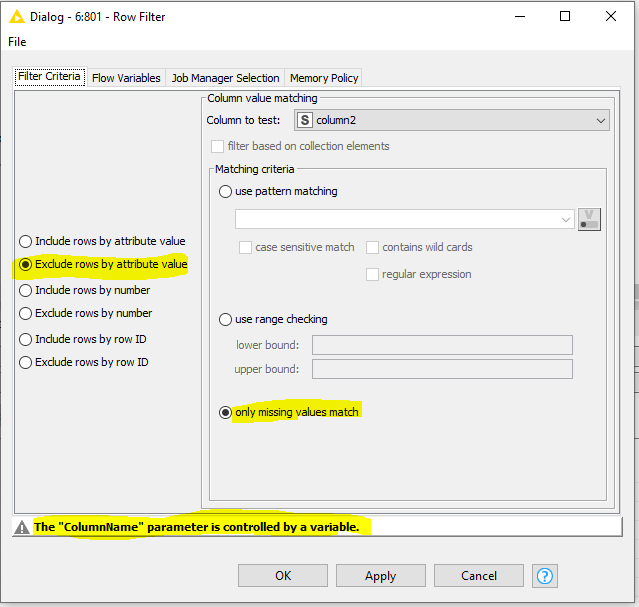
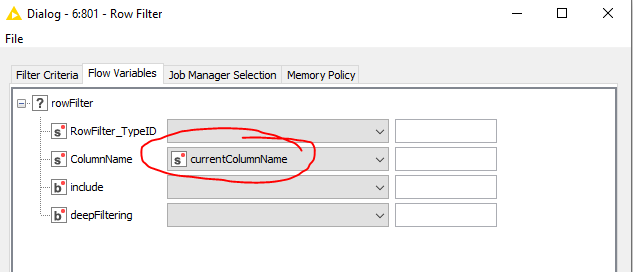
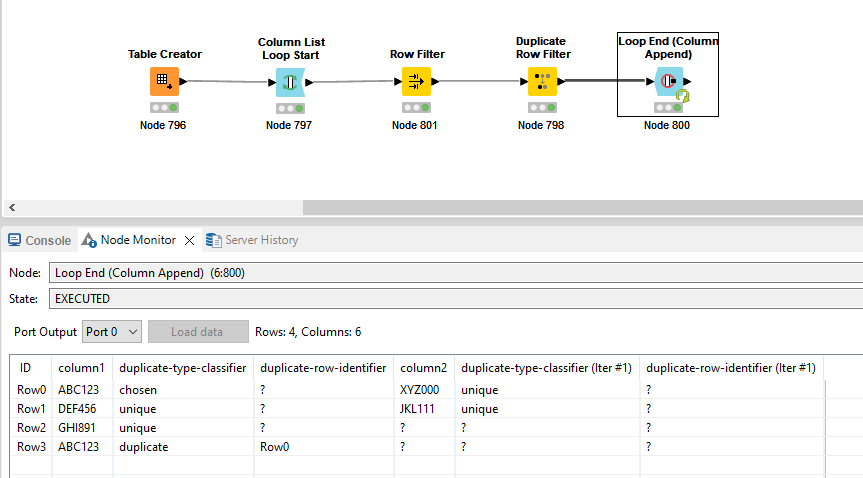
I have multiple columns of string data that I need to check for duplicates occurring within each column (i.e., not across the row or in a different row/column).
I used the Duplicate Row Filter in a Column List Loop Start and got the desired output, i.e. each data column has a “duplicate-type-classifier” and “duplicate-type-identifier” column next to it showing the unique, chosen, and duplicate values for each row.
The issue I’m running into is that null values are also identified as duplicate values. I didn’t see a way to do prevent that in the Duplicate Row Filter, so I have been looking for a workaround to remove them.
I have multiple columns so I am picturing the final solution would use a loop (and possibly a variable?) to check all of them (e.g. if the data_col is null , set the duplicate-row-identifier to null, else use its existing value) but I wasn’t sure how to string the tools together to check and replace all of the columns.
Here’s the result I have:
data_col
duplicate-type-classifier
duplicate-row-identifier
data_col (#01)
duplicate-type-classifier (Iter #1)
duplicate-row-identifier (Iter #1)
ABC123
chosen
?
XYZ000
unique
?
DEF456
unique
?
JKL111
unique
?
GHI891
unique
?
?
chosen
?
ABC123
duplicate
Row1
?
duplicate
Row 3
Here’s the result I would like to get:
data_col
duplicate-type-classifier
duplicate-row-identifier
data_col (#01)
duplicate-type-classifier (Iter #1)
duplicate-row-identifier (Iter #1)
ABC123
chosen
?
XYZ000
unique
?
DEF456
unique
?
JKL111
unique
?
GHI891
unique
?
?
chosen
?
ABC123
duplicate
Row1
?
duplicate
?
The duplicate-type-classifier will not be included in the final output so it doesn’t necessarily need to be corrected.
Apologies if this is a little convoluted, I can post additional details if needed if anyone has an idea on how to make this work. Thanks for taking a look.
What is the duplicate-row-identifier (Iter #1) column and how is it being derived? Why does it show “Row 3” in the current result? You haven’t mentioned it in the text as far as I can see, but it appears to be the only difference between your current and required tables, so difficult to work out how to assist in what you are trying to do.
Would you be able to post the sample of data before the duplicate row filter is applied, so we can see more clearly what is going on.
One other question… in your data, how many columns will contain some missing values that you need to include as non-duplicates?
Thanks for your quick response, I have broken out your questions below for ease of reply:
What is the duplicate-row-identifier (Iter #1) column and how is it being derived?
The duplicate-type-classifier and duplicate-row-identifier columns are generated by the Duplicate Row Filter - I have “Keep Duplicate Rows” “Add column showing duplicates”, and “Add column identifying the ROWID of the chosen row for each duplicate row” selected for the node in its Advanced tab.
Why does it show “Row 3” in the current result?
That’s the question I am trying to resolve, it is puling in the ROWID of the chosen row for each duplicate row per the node settings above, which in my case is correct for rows that are non-null, but not for rows that are null.
You haven’t mentioned it in the text as far as I can see, but it appears to be the only difference between your current and required tables, so difficult to work out how to assist in what you are trying to do.
Correct, that is the only difference, and the one I am trying to fix - by either preventing the Duplicate Row Filter from identifying nulls as duplicates, or by applying a workaround to refine it afterwards (or other possible solutions).
Would you be able to post the sample of data before the duplicate row filter is applied, so we can see more clearly what is going on.
Sure, here is a brief sample:
data_col
data_col (#01)
ABC123
XYZ000
DEF456
JKL111
GHI891
?
ABC123
?
One other question… in your data, how many columns will contain some missing values that you need to include as non-duplicates?
There will be multiple columns, the number varies each time. Most likely it will be in the low hundreds.