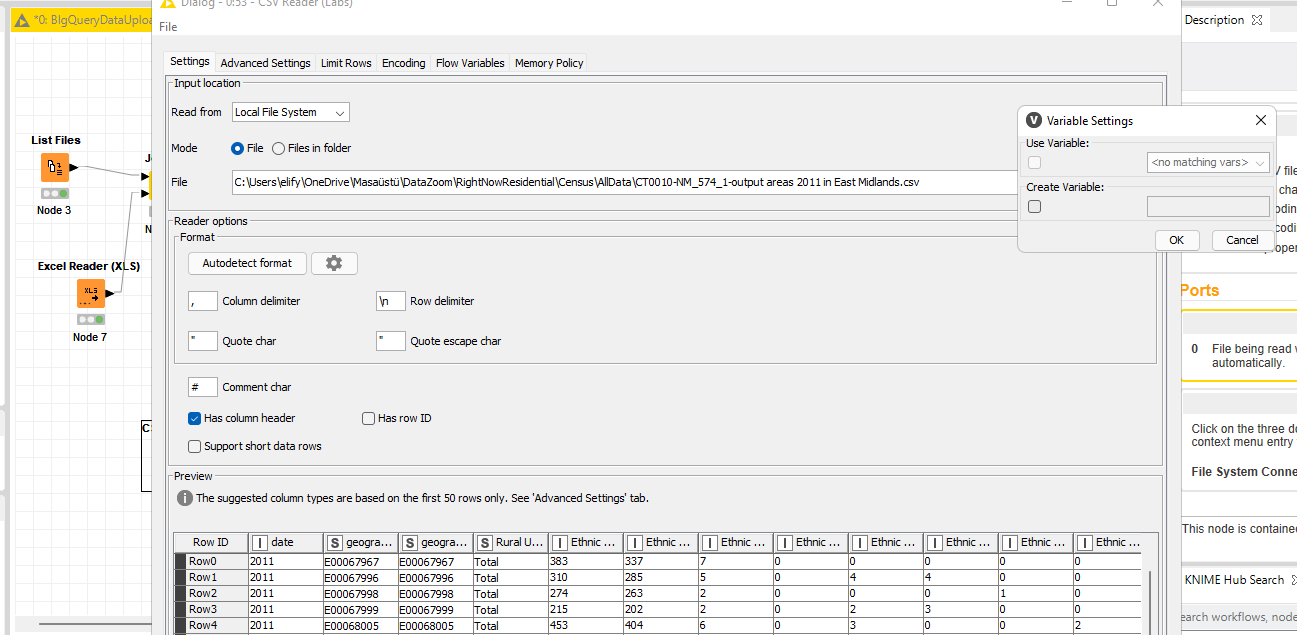
I am trying to read 1000 CSV files with different schemas and upload them to Google Big Query using a loop. I get an error: “ERROR File Reader 0:5 Execute failed: For input string: “9.77” In line 2 (Row0) at column #10 (‘Ethnic Group: White and Black African; measures: Value’).”
I think this happens because the schemas of the CSV files are different. How can I solve this issue?
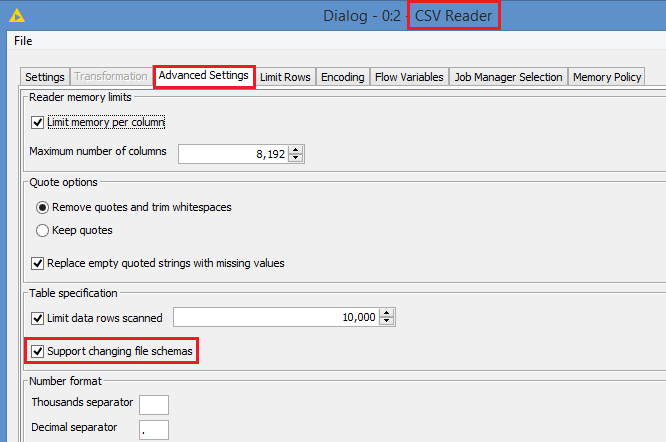
Hi @datazoom , I don’t have Knime in front of me right now, but the CSV Reader has an option in the advanced tab for “Support different schemas” or something like that.
Also, the CSV Reader has the option of reading multiple files on its own without having to run it through a loop.
I think you are referring to CSV Reader (Labs) node. When I try to read all the files in a folder it again gives an error saying that the number of columns differs.
I tried to get the URL from another file using a flow variable but it does not accept the variable, I do not know why.
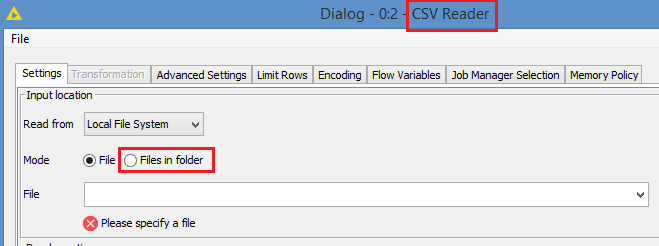
Hi @datazoom , if you are seeing the “Files in folder” option only in the Labs version, I’m assuming that you are running on a quite “old” version of Knime.
The regular CSV Reader node of the newer Knime versions offers this option.
And this is the option for supporting different structure from different files:
Thank you again. You are right! But I updated the version. I cannot use the folder read option, it tries to combine the files. I managed to create a loop but it still gives an error while getting each table:
ERROR Variable Condition Loop End 0:51 Execute failed: Input table’s structure differs from reference (first iteration) table: different column counts 64 vs. 15. I click on execute again and it continues. Still easier than uploading the files manually.
Wouldn’t reading the files via a loop do the same? Unless you are processing the data and writing it to somewhere within the loop?
Can you show us how your workflow looks like, so we can understand what you are doing? It’s best if you can share you workflow. If you can’t share your workflow, can you at least show a screenshot of the workflow?
I’m also trying to understand why you are using a Generic Loop Start and a Variable Condition Loop End
I have 1400 CSV files in 140 different schemas. Each file includes a dataset about different properties of a portfolio and there are 10 portfolios vs 140 properties for each portfolio, so it ends up to 1400 files. I try to create 140 tables (1 table for each property) in BigQuery and append 10 portfolios’ data to these tables.
So, I do not want to combine the data included in the CSV files.
Hi @datazoom , thanks for sharing your workflow. As I guessed, you are writing the read data to somewhere, in this case to Google BigQuery, in which case the use of the loop is justified.
In your case, you can end the loop with a Variable Loop End, which you attach to your DB Table Creator, instead of the Variable Condition Loop End
You should not get any error after that.
Also, if you are going to write to different tables, you need to create different table names dynamically via a variable, and pass that variable in your DB Table Creator.
Are you trying to write to the table though? Or just create the table?
Thank you very much for your help. I changed the end loop to Loop End and ticked “Allow Changing table specifications” and “Allow variable Column types” now it works without errors:)
I created the tables first and then loaded the data into the tables.
Thank you again for your support! Much appreciated!