Hi @JulioCesar , your title is kinda the opposite of what you are looking for I think, no?
Anyways, I’m going by what you wrote in the thread since it corresponds to the results of your sample data.
I’m able to identify what needs to be changed, and I’m able to access them, but somehow the case would not work.
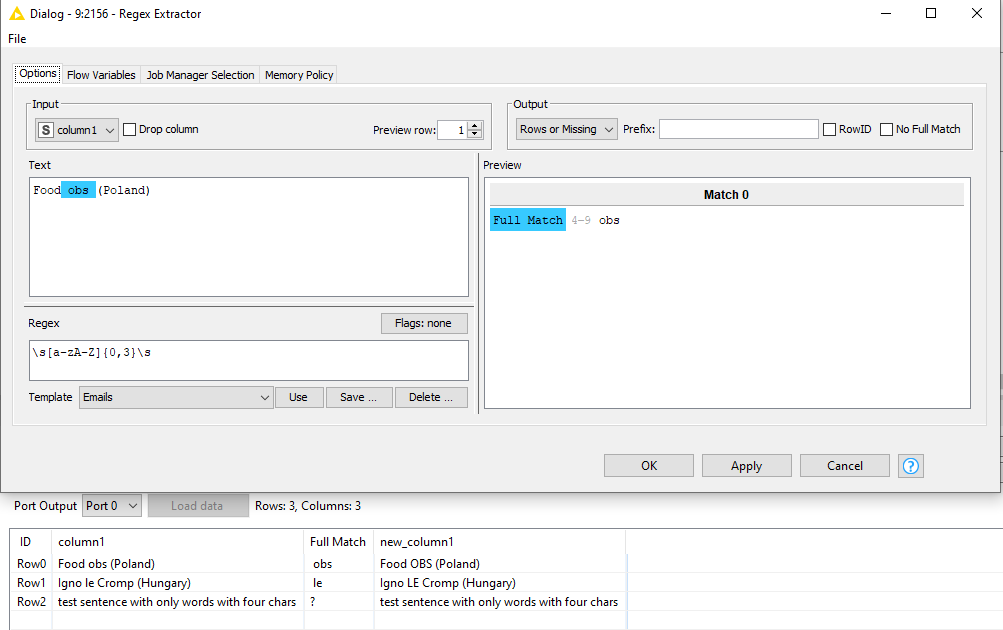
In theory, this should work: regexReplace($column1$, "\\b[a-zA-Z]{1,3}\\b", upperCase("$0"))
But it’s not changing the case. The proof that it should work is that when I tried this: regexReplace($column1$, "\\b[a-zA-Z]{1,3}\\b", upperCase("xxx$0xxx"))
I get this:
You can see that the targeted words are enclosed between “XXX”. More so that my original XXX is actually “xxx” but uppercased via the function upperCase().
Hi @ArjenEX , the problem with the approach you are doing, your replace() function is not targetting the specific word, but rather a string. I’d be curious to see how it handles the line “P&d drotaru zrt (Hungary)” for example. Chances are that it will uppercase the “d” in “P&d”, but also the “d” in “drataru” if I’m not mistaken.
I’d also be curious to see how the replace handles multiple matches for the same line, which is the case for the same example
@bruno29a
You’re right. I took only two examples and went for it
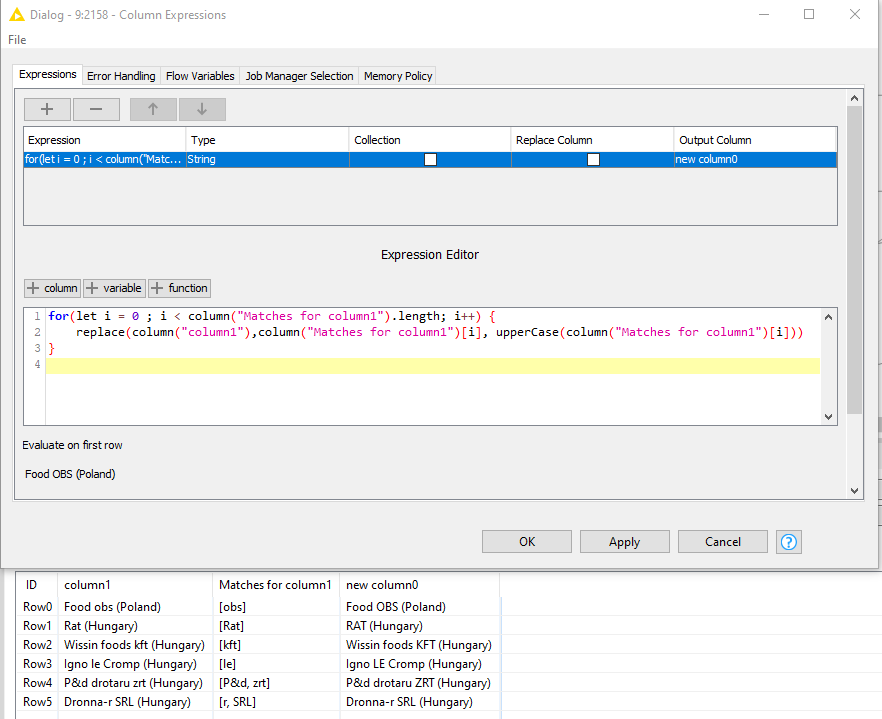
Strangly enough running into similar issues where some matches are capitalized and some not with this alternative approach.
for(let i = 0 ; i < column("Matches for column1").length; i++) {
replace(column("column1"),column("Matches for column1")[i], upperCase(column("Matches for column1")[i]))
}
Hi @ArjenEX , these are the exact 2 challenges I was seeing in my mind with this approach. Just looping will not solve this issue. You would need some recursive loop for it to work. And this is also not solving the issue of replacing “r” in the last example - it will capitalize the r in “Hungary”.
As you can see, the issue you are having is with cases where you have more than 1 element. That is going on is that, it is actually doing the replace via the loop, but the problem is that, without recursion, you are not passing back the modified version to be replaced, but rather the original version of the string at each iteration. That is why the zrt is replaced, because it’s the last iteration of the loop, and similarly for SRL.
So the 2 issues with this approach are:
1- Recursion for multiple replace for the same records
2- Replacing only the r in Dronna-r (FYI, for P&d, they’re actually detected as 2 words of “P” and “d”, so that would mean to replace “d” from “P&d” without capitalizing the d in “drotaru”
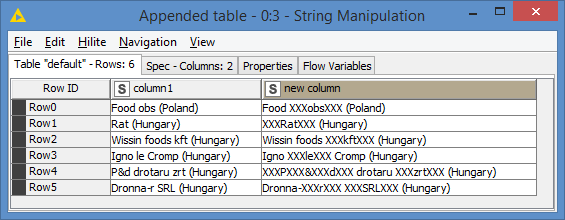
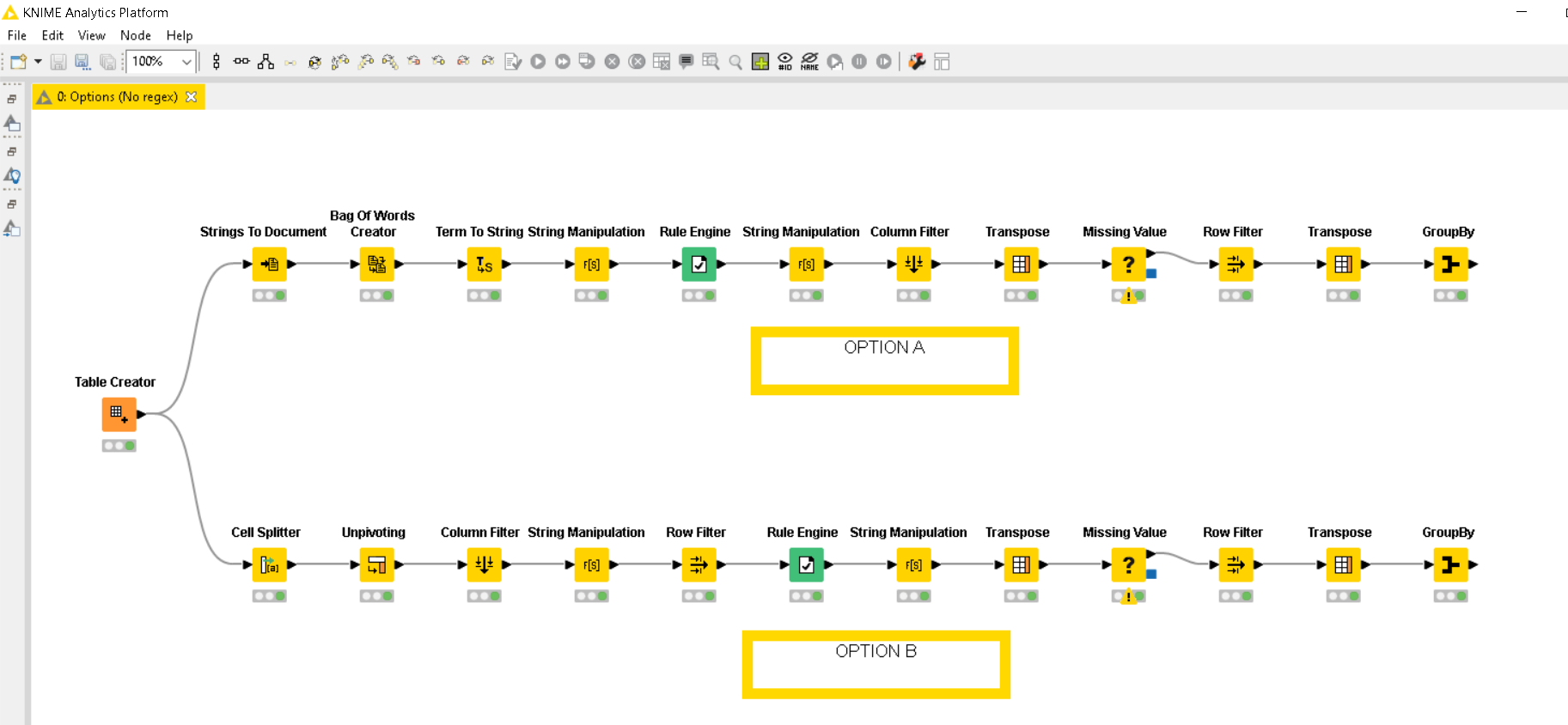
Hi @JulioCesar , I decided to look into an alternative.
I used the same approached that I originally did, but I then did additional string manipulations on it to manually uppercase the identified words.
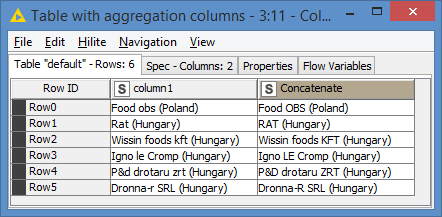
Here’s the results:
That’s how the workflow looks like:
And here’s the workflow:
Anyone else who is better at regex than me, I would still be interested to know why the upperCase("$0") from regexReplace($column1$, "\\b[a-zA-Z]{1,3}\\b", upperCase("$0")) did not work.
@bruno29a the cell splitter came also direct up in my mind. Otherwise it will end in a really long and rather complicated regex. The cell splitter helps also to not have to deal with the “Dronna-r” problem in regex. You have to tangle all possible cases. Which very likely not all known. In regex without it.
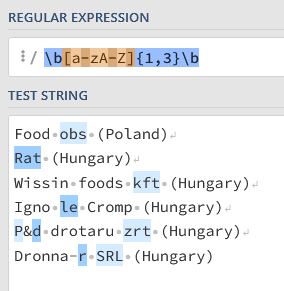
I am far away from being an experienced regex-guy. In my trusty regex checker your expression works as follows:
@bruno29a If you try this regex on the string “Food obs (Poland)” regexReplace(column("column1"), "(?<=\\b)(\\w{1,5})(?=\\b)", upperCase("$1"))
it should replace all strings of 5 or less chars enclosed in word boundaries (“words”) with their upper case version. Actually it doesn’t replace anything, which makes you think that the regex doesn’t work.
This one regexReplace(column("column1"), "(?<=\\b)(\\w{1,5})(?=\\b)", upperCase("$1a"))
should replace all “words” of 5 or less chars with their upper case version followed by “A”. You’d expect to get “FOODA OBSA (Poland)”, intead the result is “FoodA obsA (Poland)”. That is, the regex works, but the content of $1 (“Food”, “obs”) is passed to the function as a null value.
To complete the picture, regexMatcher(column("column1"), "(?<=\\b)(\\w{1,5})(?=\\b)")
(same pattern as above) returns false.
Thanks @duristef , you kinda wrote what I said and did the same “test”, but I guess my question would be, why is it “passed to the function as a null value”?
We can clearly see that $0 ($1 in your case because of your regex expression) is there, especially in my example where I am surrounding it with “xxx”. And as you did with “a”, my “xxx” got uppercased, like your “a” did, and my $0 is there. And if it’s “null”, why does it appear in the results (“XXXobsXXX”, “XXXRatXXX”, etc)? Should it not have produced “XXXXXX” then?
@bruno29a Sorry, I didn’t read all your previous posts. In fact, it seems that $1 is not treated exactly as a null value. It behaves more like a placeholder, which is replaced by the actual value only at the end of the process.
The alternative I found - as usual - is a Python script
import pandas as pd
import re
def ucase(match):
return match.group(1).upper()
output_table_1 = input_table_1.copy()
pattern = r"(?<=\b)(\w{1,3})(?=\b)"
output_table_1['column1'] = [re.sub(pattern, ucase, item) for item in output_table_1['column1'] ]
I think that’s the correct explanation, and that’s why it does not apply the upperCase() function since the placeholder would be replaced after the function is run.
For the alternative, yes, I’ve seen it be done via re. Thank you for sharing the Python code.