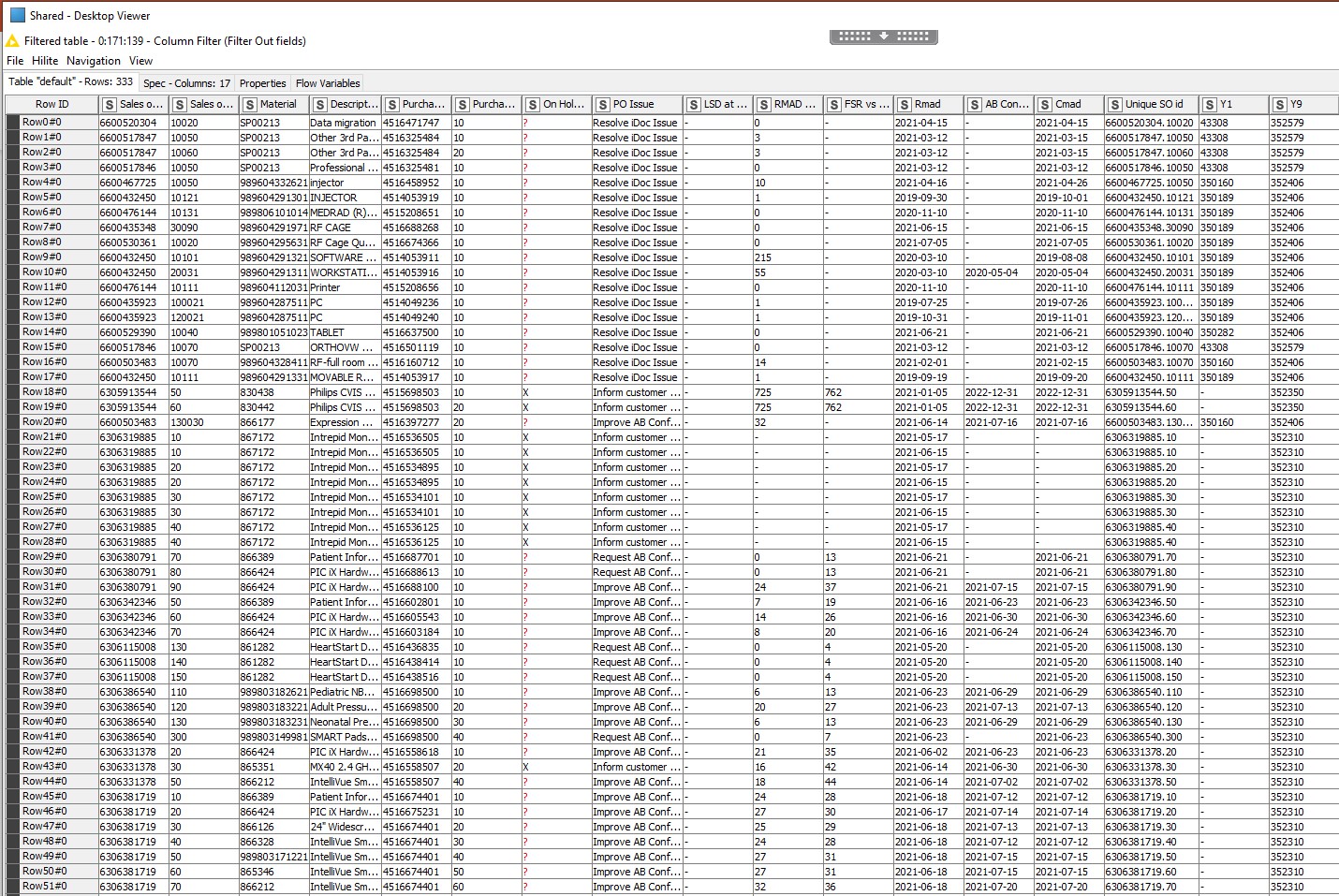
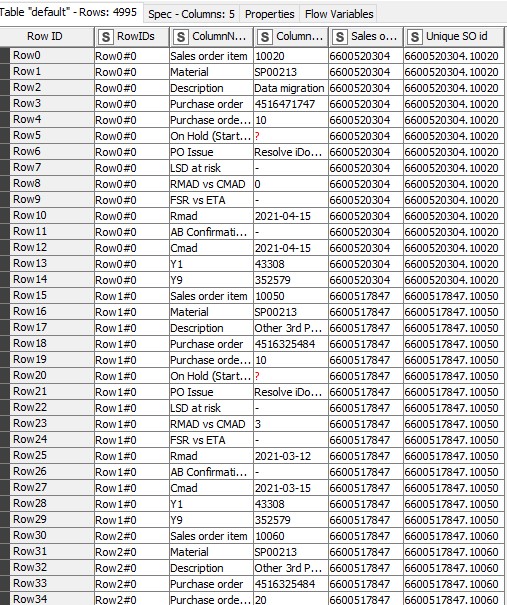
Building on what has already been said about joins, and hopefully clarifying… you should only see duplicates in your data if the join is not based on totally unique keys in both of the tables being joined. That should hold irrespective of the type of join used.
If my (left) table contains
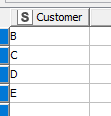
and my (right) table contains
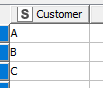
With an outer join, the rows returned are:
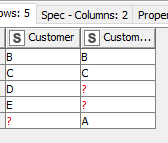
This output comprises all that are ONLY in left, plus all that are ONLY in right, plus all joined rows that are in BOTH)
It follows therefore that provided the join finds UNIQUE rows in both tables, then the total number of rows returned can never be more than the sum of the total rows in both tables (which is the limit for when no rows match). The lower bound for the returned rows is if the set of all the keys from one table is a subset of the keys from the other table, When this occurs, the the total rows returned will never be more than the size of the larger table.
So for an outer join, the range of counts of possible rows returned, assuming unique keys in both tables is
count of rows in larger table <= rows returned <= sum of count of rows from both tables
The only time you should get “duplicates”, and therefore exceed the sum of rows from both tables is if you are using non-unique keys from one or other of the tables in which case, you will get “cross joining” of those specific data items
If my left table were

and my right table were:
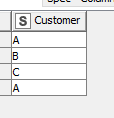
then the full outer join will now see two rows containing B (the cross join for B being 2 rows x 1 row = 2 rows) and two containing A
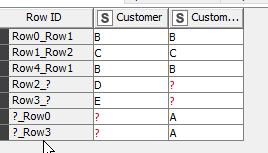
If B appeared twice in both tables, I would expect to see 4 rows containing B (the cross join for “B” being 2 rows x 2 rows = 4 rows)
So if in the above example my right table were:
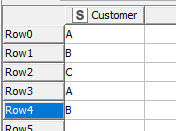
This would now result in the following:
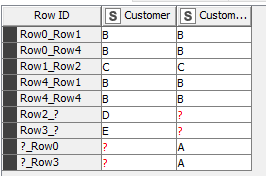
So, in summary, if you are getting duplication out of a full outer join, this must be because you are using join criteria that is non-unique on either one or both of your input tables.