I am in desperate need of help with KNIME. I am using it for uni work and I’m getting really confused on what to do with my dataset.
I need to use kNN, SVM and Random Forest. However, I’m experiencing a few issues with data types.
For example, in my visualisations I found that two variables were valuable to use to explore further. I then created the streams but they just aren’t playing ball. I feel very overwhelmed with the amount of preprocessing options too.
If anyone would be so kind to give me advice or even better set up a call with me that would be amazing. I am so so stuck and no one is giving me help.
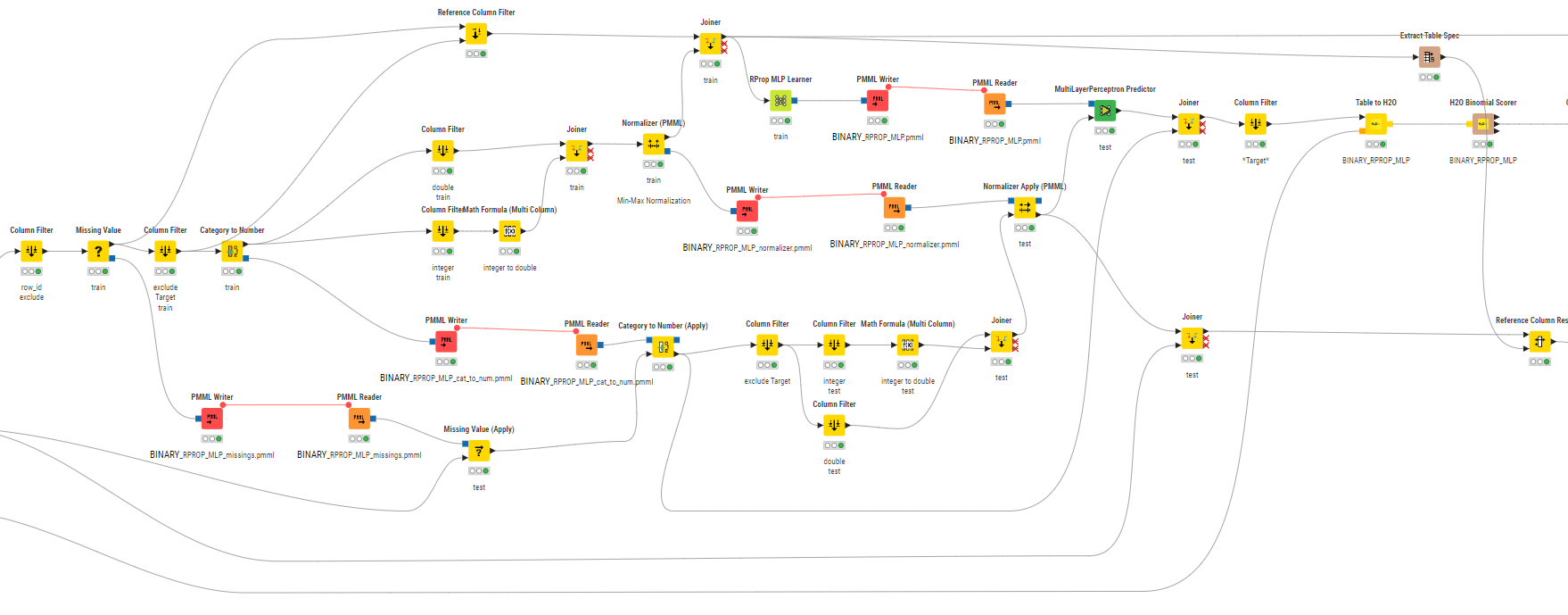
For Algorithms that need normalization and just numeric data you might also take a look at the data preparation in the Metanode “BINARY_RPROP_MLP”. This will involve converting the string columns to numeric ones (you could also employ vtreat for that), to normalize the data and while doing that preserve the option to re-do this for new data. It does look a little bit complicated first but you can just use the example for other data, provided your target variable is named “Target”.