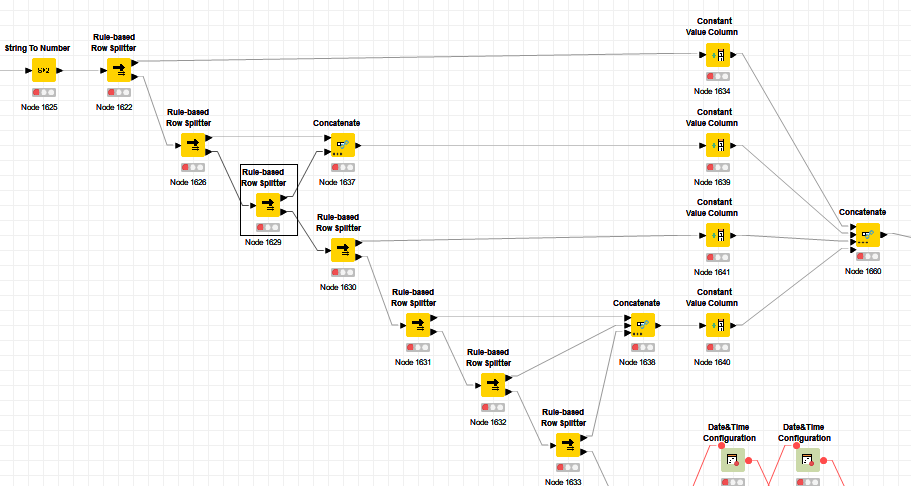
I have very nearly 70 million rows of anonymised credit card data that I need to mark with an issuer tag. I have built a really cumbersome cascade of rule-based row splitters and constant value columns that do the job but it slow, bulky and difficult to manage.
What my cascade does is simple, for example, if the 1st digit of the first 4-digit number is a ‘4’ then the constant value column adds “VISA”. If not. then the next splitter checks if the 1st 4-digit number is ‘2221’ or ‘2720’ and if true “MASTERCARD” and on through all the levels of the cascade.
And so it goes through all 69 million rows… at the end of the cascade, all the data is brought back together with a ‘Concatenate’ node. It takes near 90min to pass through this very inefficient section of the flow.
What I would like to know if there is a simpler way to do this, possibly using an “IF…”?
Thanks for the great suggestion. I implemented both suggestions and was really surprised by the results.
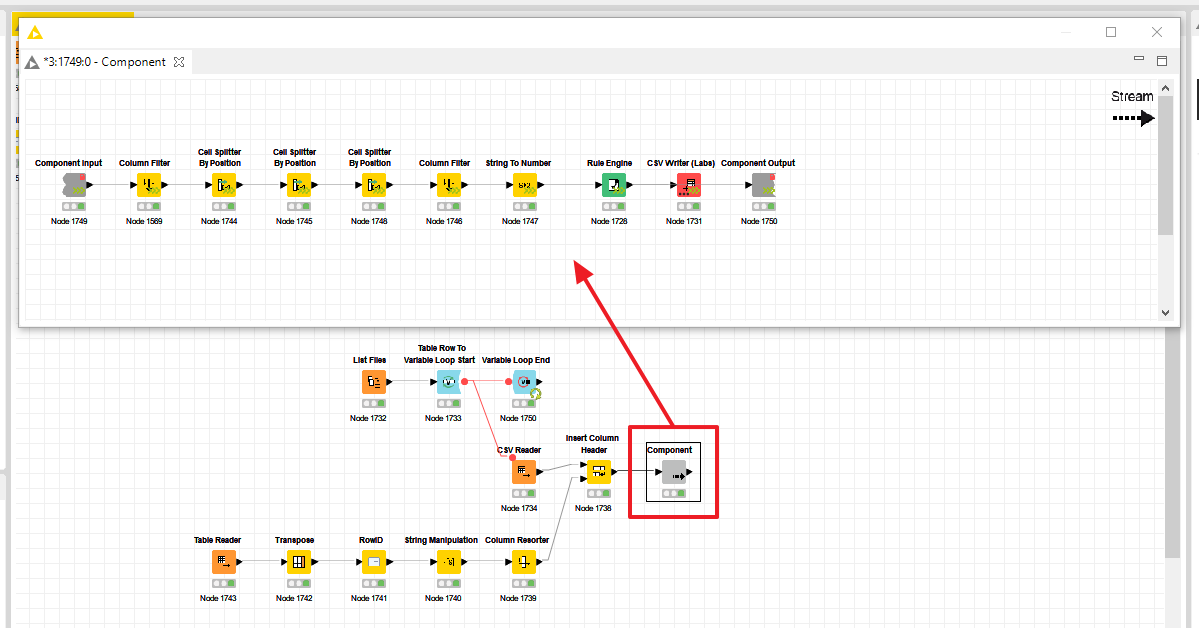
The source data is written in CSV monthly data sets so I had to use a loop and a CSV reader to load each file in which took a bit under 3 minutes per file before streaming the rows. I did all the processing in a streaming component and it took 01:17:24 to finish processing all 69 million rows. I used the KNIME labs CSV writer in the component to write all the data back to a single CSV file which is 6.75GB. If you deduct the 36 minutes wasted reading the CSV files the component took 39 minutes to process the rows. What also needs to be taken into account is that the data was being read from and written to a standard notebook hard drive, not an enterprise speed version or an SSD. Using an SSD, I am sure would have produced better results.
I tried to use the KNIME Labs CSV reader but in the first attempt, I could not use a variable from the File List node to provide the path to the source files and then when I chose to load all the files from sub-folders it had unexplainable issues with rows of data. I am quite sure that using the Labs CSV reader which is streamable, the process would have completed in under an hour even on my slow hard drive.
What was really nice to see was the massive drop in memory utilisation. Without streaming the 32Gb I have made available to KNIME is always at max levels, and I was often seeing a warning about possible data loss in the console because memory was not available. While running the stream, memory utilisation seldom went over 8Gb, even with 2 other flows getting data from an API running at the same time.
glad to hear it’s working faster now. The CSV Reader from labs still can’t be used in combination with List Files node but maybe you can give Simple File Reader node a chance as it should be much faster.