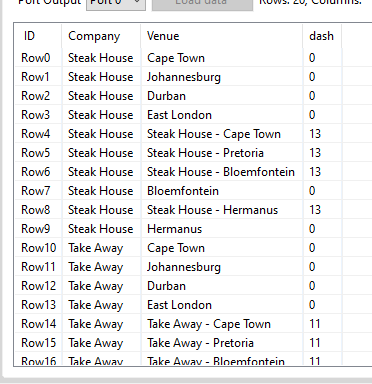
I have a data set with a column that contains restaurant chain brands and venues. It is compiled by area managers that sometimes include the brand name with the venue location with a “-” between the brand and the venue so I get a column that has values “brand - venue” instead of just “venue”.
I can fix it by using a “Row Splitter” node followed but a “Cell Splitter” and then a “Column Filter” which work perfectly well and is bulletproof, but I am starting to like using scripts in “Column Expression” nodes just because in KNIME I can and it is an opportunity to learn something at the same time.
If I use a “contains” function to test if the column row contains a “-” by itself it works perfectly and I get an additional column with true/false values, but when I include it in a loop the result is always “false”.
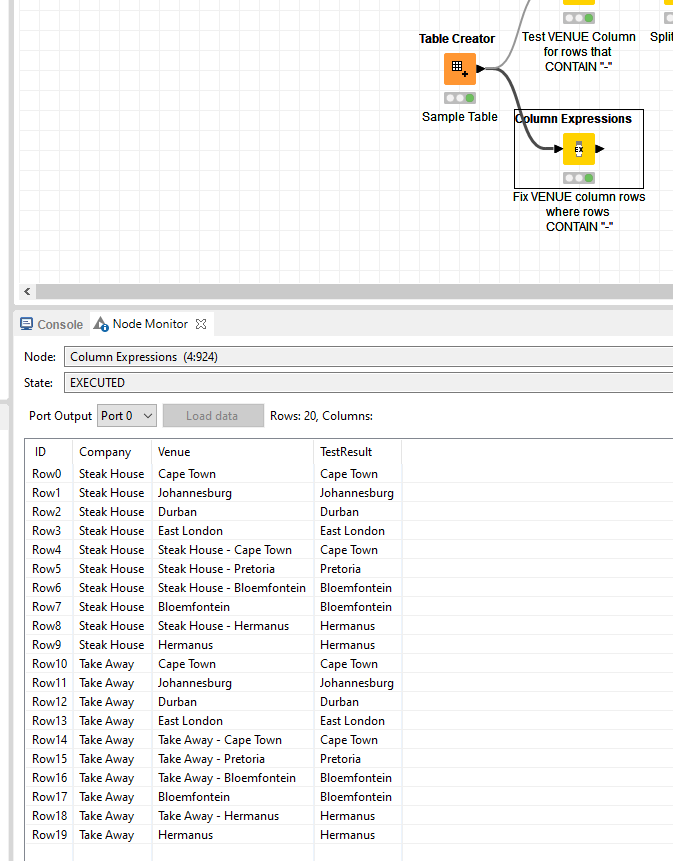
I see what you mean now. You can approach this in different ways. It depends a bit on how dynamic the Venue names are in terms of different nomenclatures that you could encounter.
Checks if the Venue contains a dash like you have. Note: you had "true" with quotes but the contains functions returns a boolean so true is sufficient here.
Take a substring starting from the position in the string where the dash occurs. Added a +1 as offset to omit the dash itself. The substr(str, start) is created dynamically based on the indexOf.
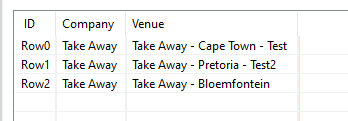
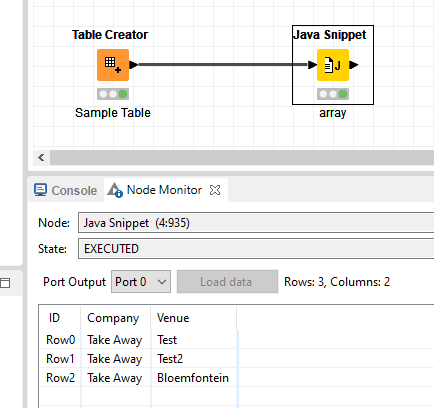
If you want to approach it even more dynamically whereby multiple dashes cloud appear and you always want to pick up the last element, I would opt for an array in a Java Snippet.