I’m trying to use the “column list loop start” node to filter out some columns as targets to train. Can I define the columns “indclude” using a flow variable?
More concrete question is for example, I need to keep only the columns with missing values and loop each column over for trainining. Can I firstly filter out the columns and then using the list of columns as a flow variable for filtering criterium “column list loop start” node?
Thanks.
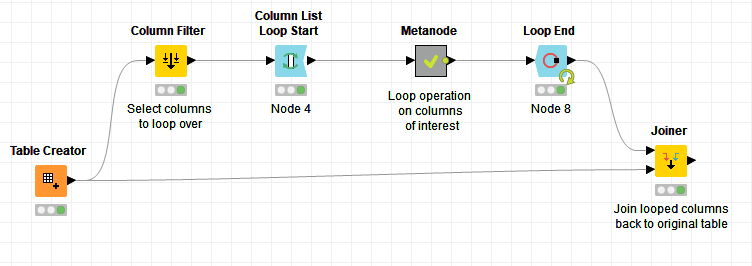
In this case, I think I would use the Column Filter node prior to the Column List Loop Start node to determine which columns would have the loop operation performed on them. After the loop, you could then use the Joiner node to put everything back together in the same table. The pseudo-workflow might look something like this:
This example workflow sets pulls out a particular string column, capitalizes it, and rejoins it to the original table. Note that there are a few changes from the defaults in the Loop End node to make this work properly.
This doesn’t involve use of any flow variables, but in this case I’m not sure you need them - that is, if I am understanding your problem correctly.
When I use Column Filter beforehand and change another data set for analysis, the configuration in Column Filter should be also changed, is that right?
Note that if you have a few different data formats, you could wrap the Column Filter node in a CASE switch, and supply a workflow variable to tell your data which port in the CASE you want it to take. In this way you could apply different column filters as needed, without having to edit the Column Filter node every time you want to run the workflow.
This approach doesn’t necessarily scale well, but depending on how many different file formats you have, it might be OK.
But can I give the same configuration of the input for the “column filter” or “column list loop start” (e.g. filter out every time the columns with missing values to loop over) , also when I deal with different data sets? I’ve thoght perhaps in this case the flow variable could be needed?
I don’t think what you want to do is possible using flow variables (although if I’m wrong, I’m happy to be corrected by other KNIMErs who may know better).
Depending on how your columns are named or typed, you might be able to approximate this functionality using the Wildcard/RegEx Selection or Type Selection radio buttons in the Exclude/Include dialogs.
Although Northern was able to find a way to work around his request, I was wondering if anyone could confirm whether a flow variable could be actually used to control the columns to loop over with “column list loop start” node?
We introduced new array flow variable types in KNIME 4.1 that should make this easier in the future, but the catch is that (for now) I don’t believe the Column List Loop Start node supports them yet. I will double check on that.
Flow variable (type array/collection) can be used to control columns to loop over in Column List Loop Start node but configuration depends on use case. Can you tell me a bit more about yours so I can create example workflow if necessary?
It is a rather elaborate flow of nodes to get a variable that you can name but it works:
Column Filter>>Extract Column Header>>Create Collection Column>>Constant Value Column>>RowID>>Table Column to Variable
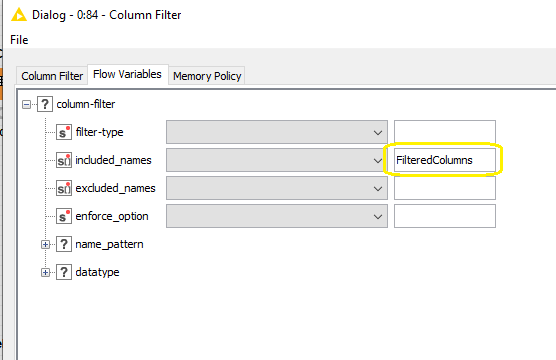
there is a better way in your case. Simply use blank text field next to included_names configuration under Flow Variables tab of Column Filter node. It will create array flow variable with included column names