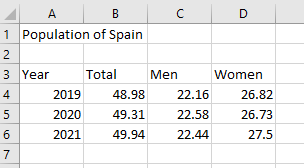
Hi @Stanislaw
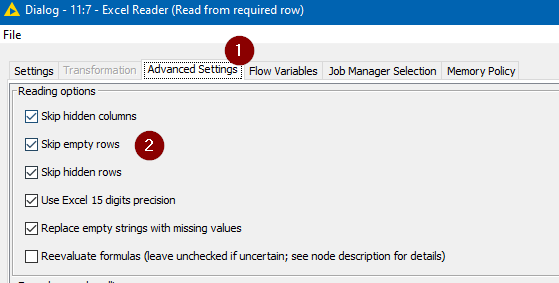
If the initial rows are just empty, then the simplest setting is on the Advanced tab
but in your case obviously that doesn’t help as you have additional wording above the header row.
If there is a “settings” way of achieving this, I have not found it! Maybe this should be a feature request… 
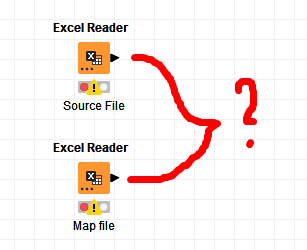
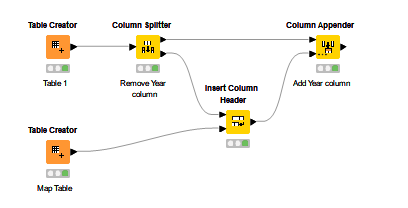
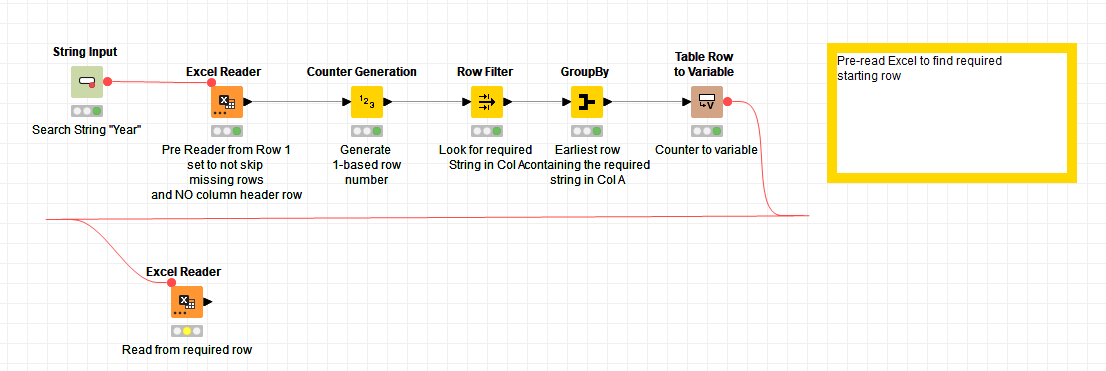
The only way I can see to do this currently is something like the attached flow.
Here, an Excel Reader is set to “pre-read” the entire file, with no knowledge of column headings
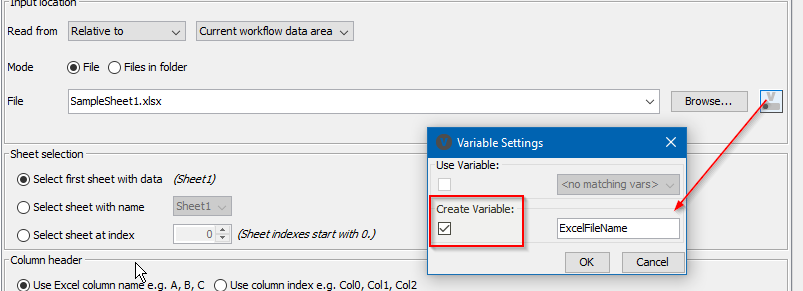
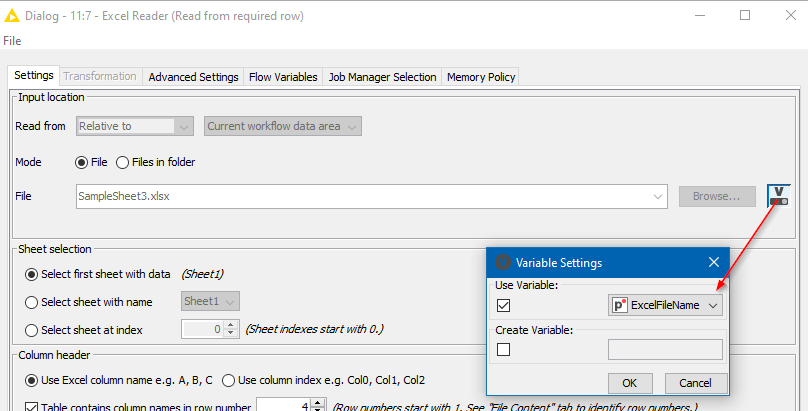
I suspect you’ll already have a variable containing the file name, but if you don’t, I would have this set to CREATE a flow variable so that the name of the file opened here, can be automatically passed to the subsequent Excel Reader and so doesn’t have to be edited in two places.
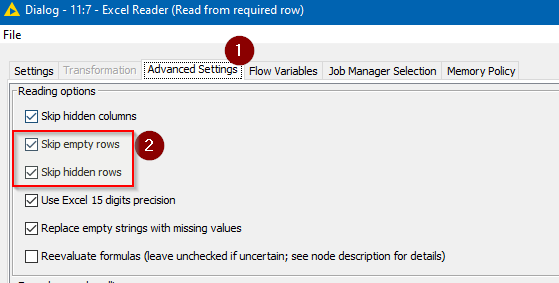
This first reader also needs to be told NOT to skip empty or hidden rows, and to support changing file schemas, since the schema on one iteration may not conform to the way it reads on a subsequent occasion.
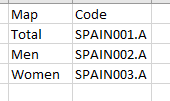
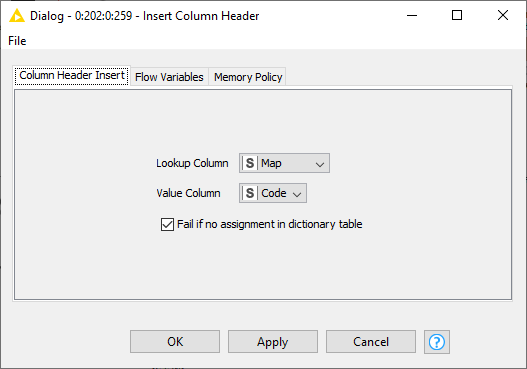
Having created a “counter” identifier for each row read, which is one-based rather than zero-based, a given search String, such as “Year” in your case, will be looked for in Column A of each row. The earliest occurrence of that will have its “counter” stored in a flow variable.
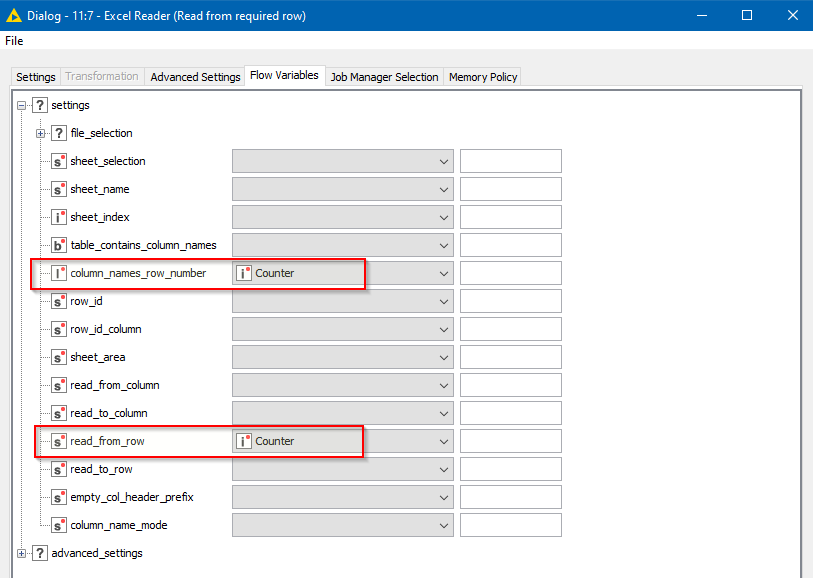
That flow variable needs to then be passed into the “real” Excel Reader for your workflow, in two Flow Variable settings:
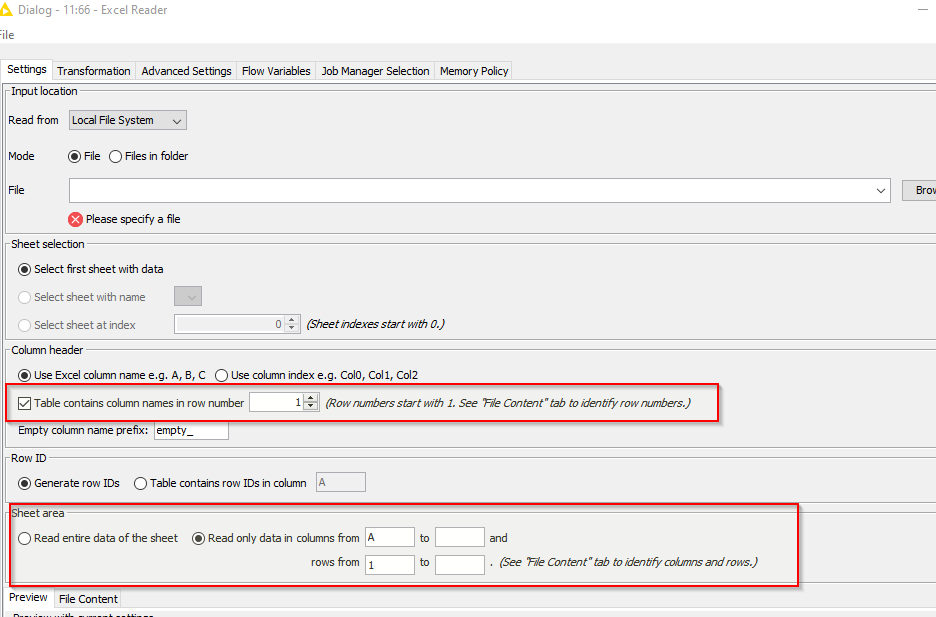
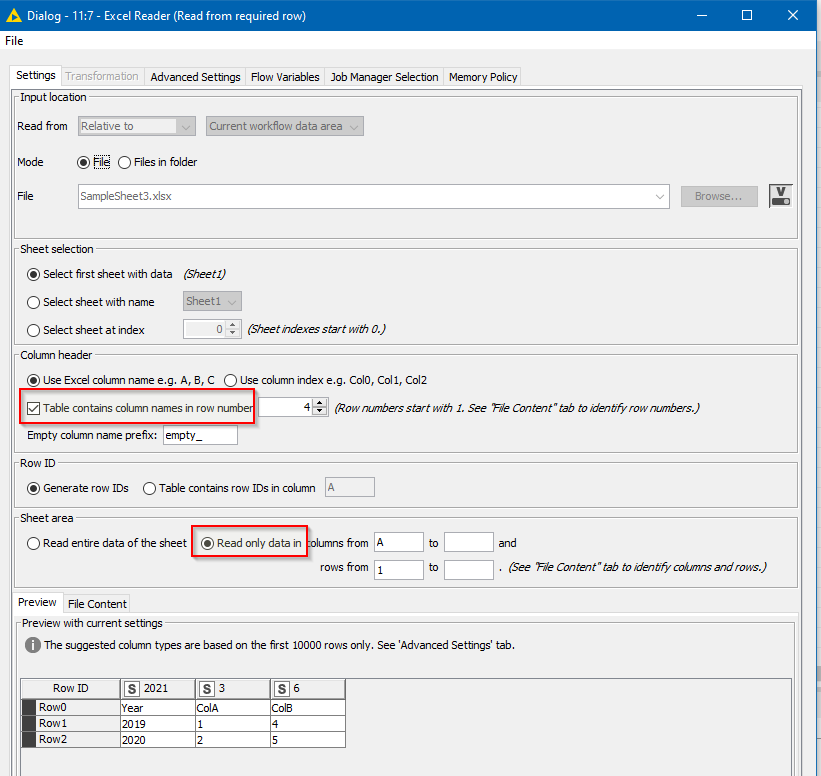
Firstly, it needs to be told which row number contains the column names, and secondly it needs to be told to treat only that row onwards as data “read_from_row”.
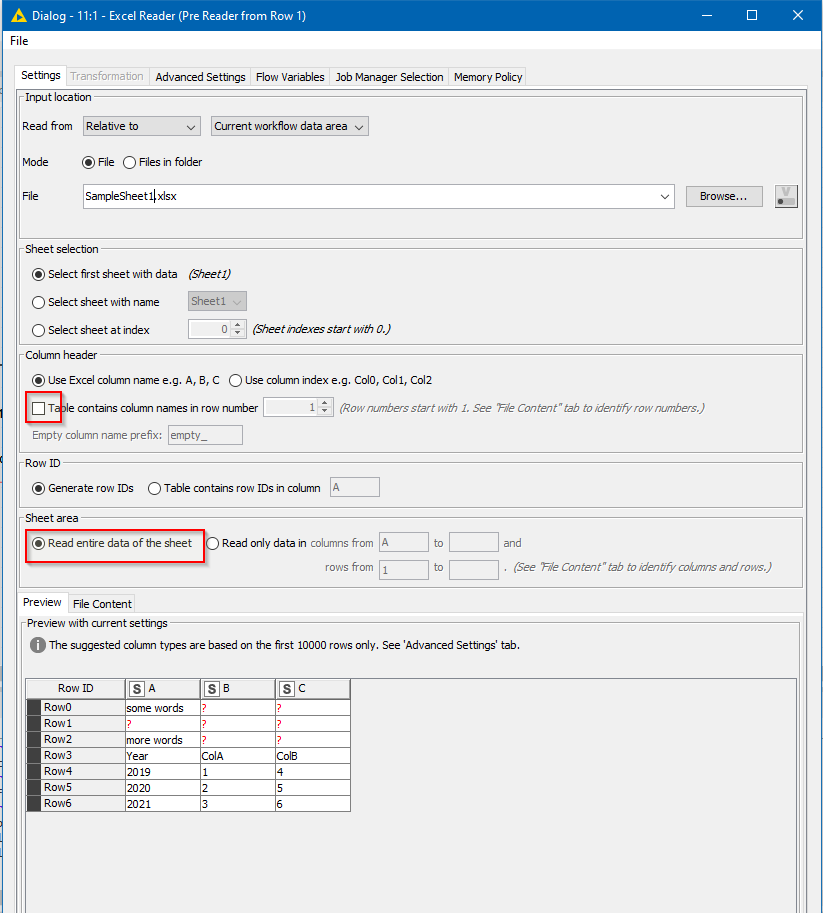
On the “Settings” tab for this Excel Reader you will need to have ticked the “Table contains column names in row number” box, as it can then use the row number supplied by the flow variable.
Likewise you need to select the “Read only data in…” so that it can change the “Rows from” value as required
Also make sure the file name is specified using either your own Flow Variable, or the flow variable created by the “Pre reading” Excel Reader
In the example workflow, there are 3 sample excel sheets, which appear to the “pre reader” as follows:
SampleSheet1.xlsx
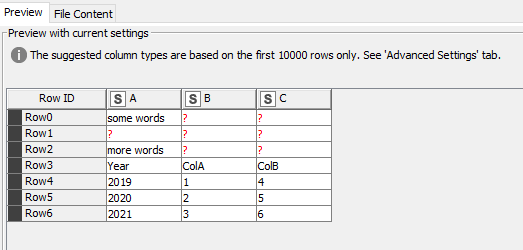
SampleSheet2.xlsx
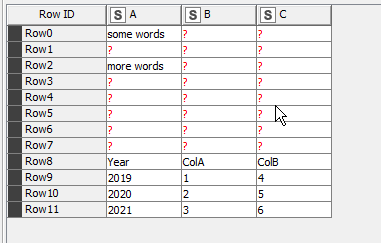
SampleSheet3.xlsx
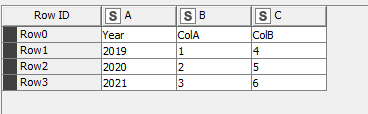
You can manually changed the file name in the Pre-Reader
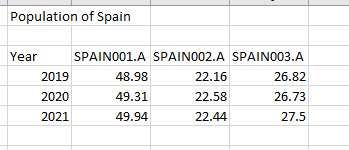
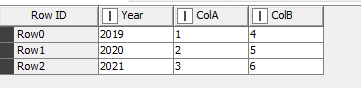
These sheets are all read by the second Excel Reader as:
Find Header Row for Excel.knwf (37.6 KB)