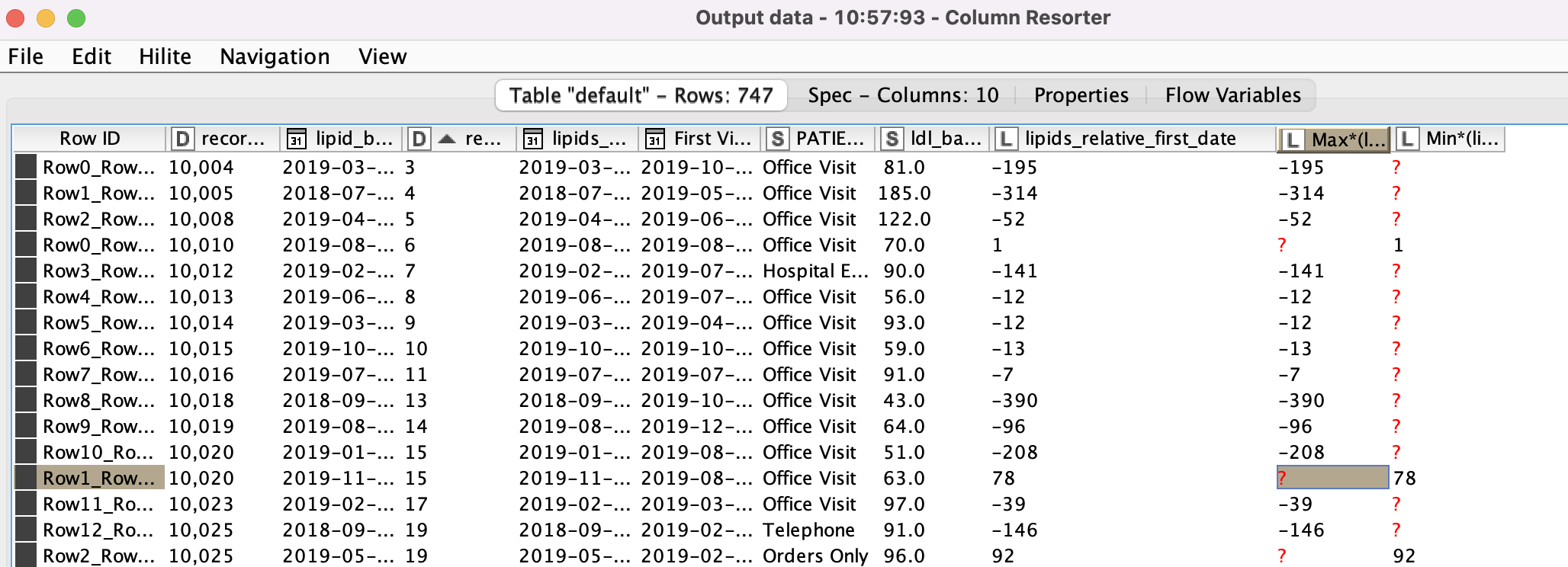
I’m running into a situation in which I don’t know how to identify, via KNIME, the duplicate row that has a value closest to “0”.
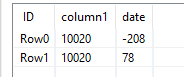
I have a column that is titled “lipids_realtive_first_date”, where it shows how far the date of a lab draw is to the patient’s first visit date with a provider. This number can either be positive or negative depending on if the visit for the lab draw was after or before their first visit date. I want to remove the duplicates for a given patient (i.e. record id 10,020) that are farthest away from “0” and keep the row or instance that is closest to “0”. However, when using duplicate row filter, I can only select the row that is the first, last, minimum, or maximum of this column “lipids_relative_first_date”. Is there another node or nodes that can help me accomplish my goal?
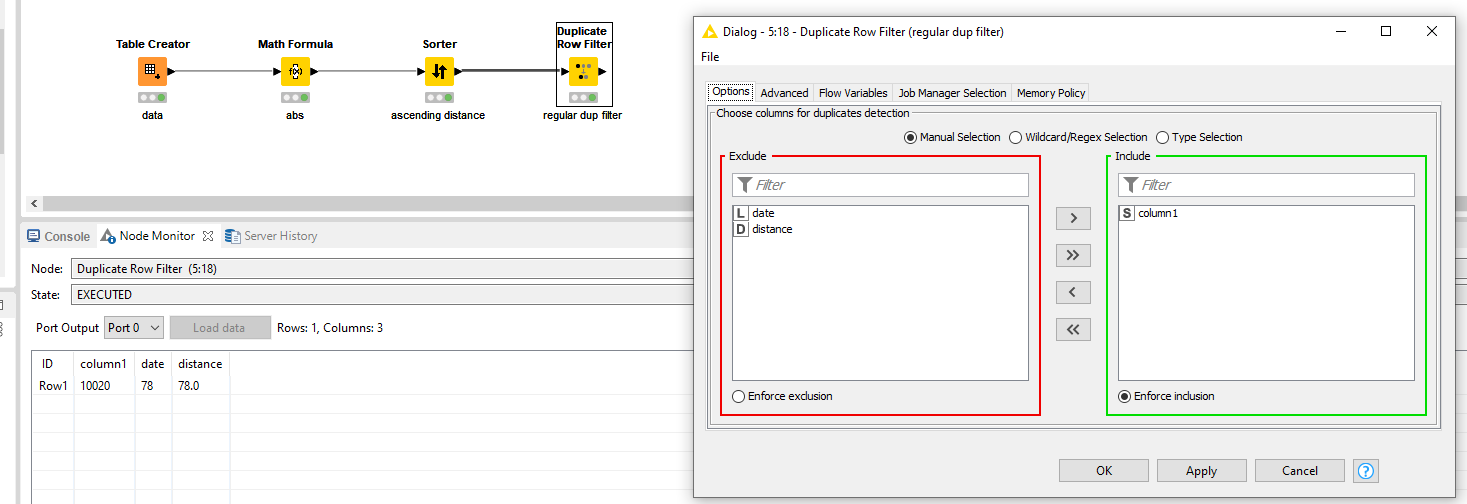
If I understood it all right, you should be able to get this done relatively quickly if you consider the absolute value of lipids_relative_first_date, sort it ascending and apply a regular duplicate row filter.
This is great! I didn’t even think about absolute value but this is ideal because I really just want the value closest to “0”. I can create a new column for absolute value and then select the minimum. Thank you so much!