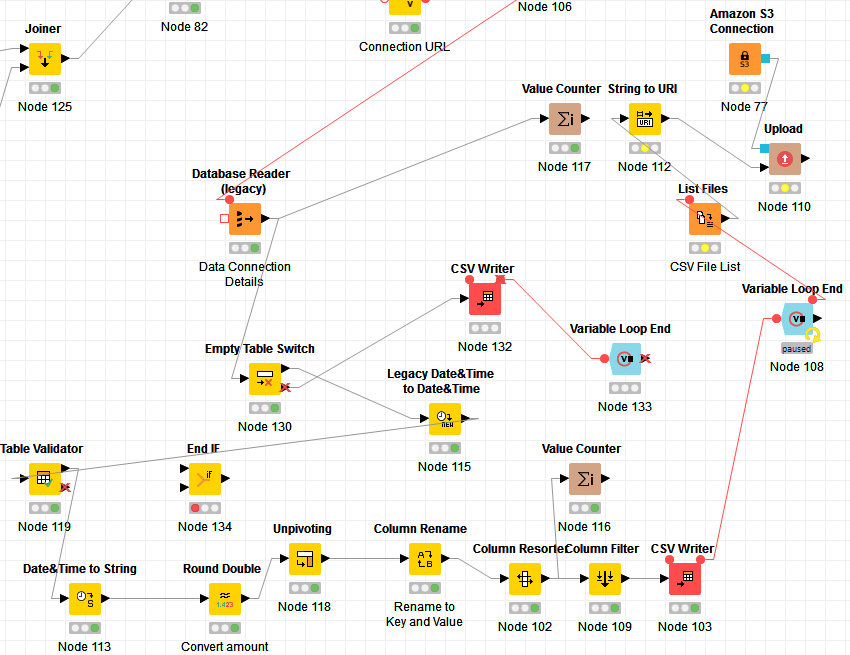
I have a table containing some SQL queries which I need to execute in turn, conform the results to a standard table structure and write to a folder in an AWS S3 bucket. The combined files, once conformed, are then queried using Athena as an entire table. Some of the SQL queries have differing numbers of columns, but using the unpivot node allows me to ensure that all of the CSV files in S3 end up with the same structure and don’t crash Athena.
The whole process works well as long as the queries always return rows, but when no rows are returned part of the conforming process fails and the loop stalls. If I use an Empty table switch and end if node to bypass the conformance process, I will write a CSV file with an inconsistent format to S3 and corrupt Athena.
What I would like to do is write a failing (audit) entry to a different folder whenever no rows are returned (or handle the problem in some other way) and continue the loop to process the remaining SQL statements.
Any help or advice would be really welcome.
welcome to KNIME Community! To be honest it is a bit messy
Just to see if I got it. If rows are returned from Database Reader node you want to run conformance process and if no rows are returned you want to write CSV audit file to another location not to corrupt Athena? I think your approach using Empty Table Switch and End If is a right one. I guess you define your location (and file name) in CSV Writer with a flow variable. Then in case of no rows returned overwrite that flow variable to have value of different location
Alternatively if you don’t use Empty Table Switch you can try using Try/Catch sequence to keep loop running in case of error but that seems like a more complicated approach.
Thank you. I have found a way using both Try/Catch and a single default row assembled from flow variables and with a row count of 0). If any of the elements fail in the Try/Catch sequence (usually due to an empty table), the default row is written instead. I have also beefed up the auditing.
I hope that my current workflow is a bit less messy now.