Hi @kludikovsky
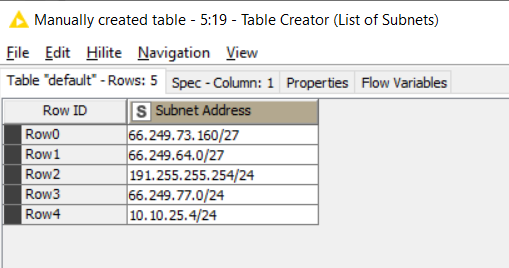
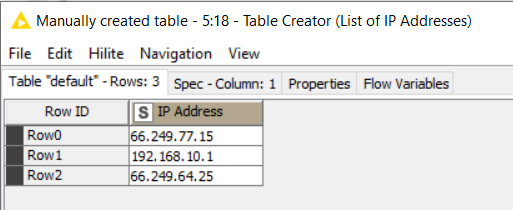
Thanks for the feedback. I haven’t tried to download and convert the list of IP subnets but instead have just created small tables of sample data. One is a list of subnets and the other a list of IP addresses.
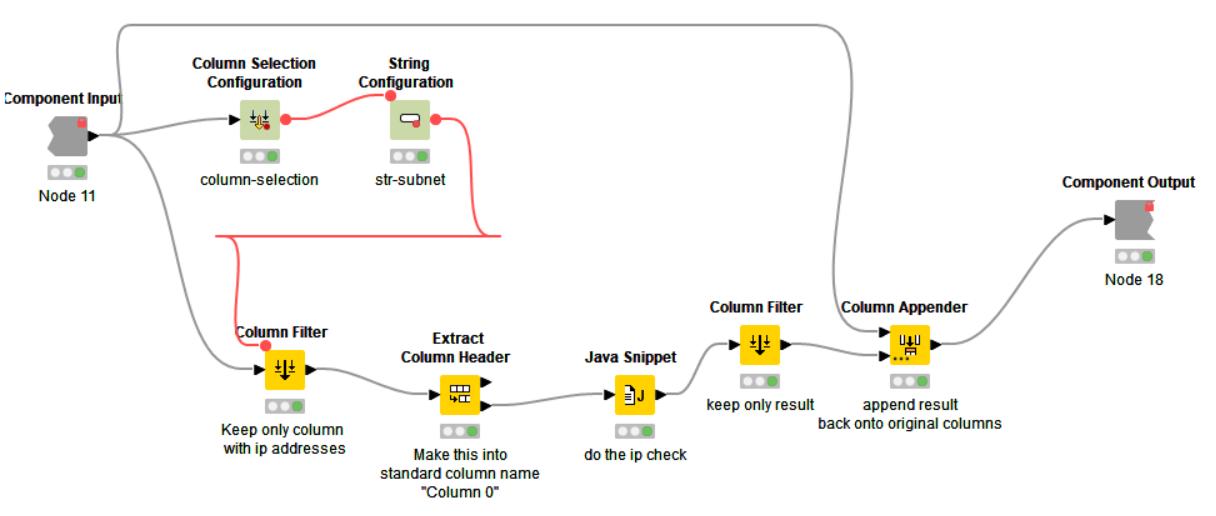
I have taken from ideas in your last post, and combined with my component idea to produce a new component “IP Address to Range”. The idea is that given a single ip address or subnet, it generates the range Low and High values. (If it is just given a single ip address, the low and high values generated are the same). It returns both low and high as both dot-separated and Long values.
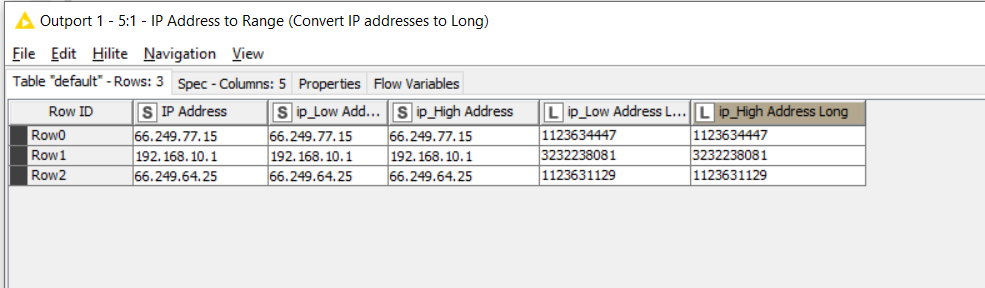
For single IP addresses:
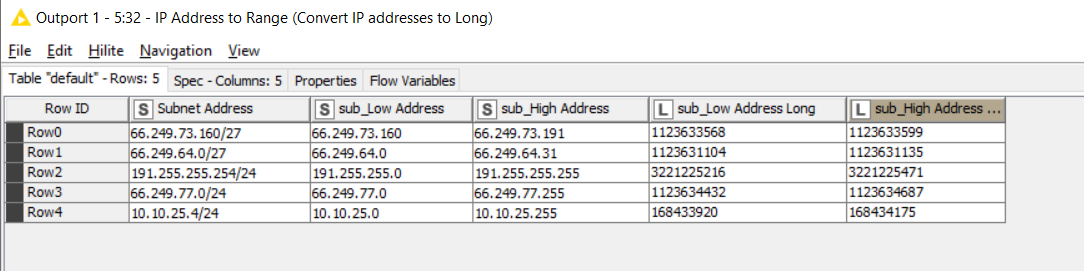
For subnets:
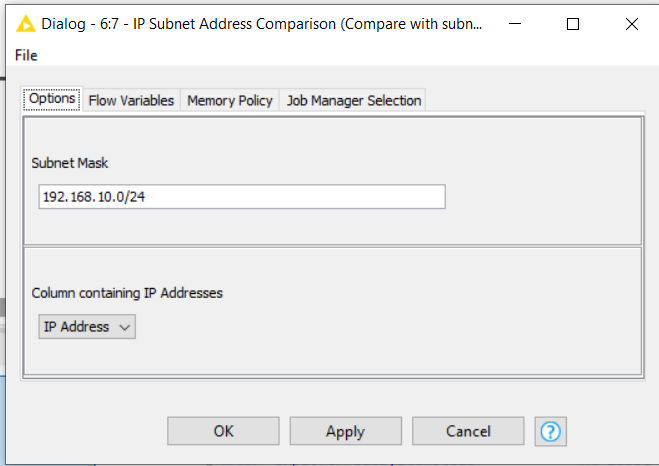
The configuration for the IP Address to Range component, is this:
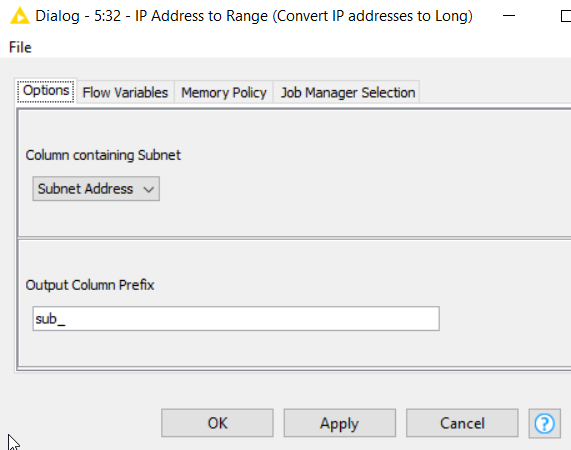
So you simplify the column containing the address/subnet to be converted, and also give it a column-name prefix for the generated columns. This prefix is useful for identifying the columns to compare later.
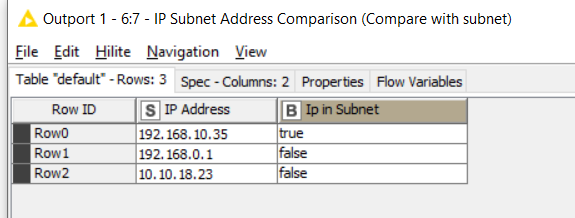
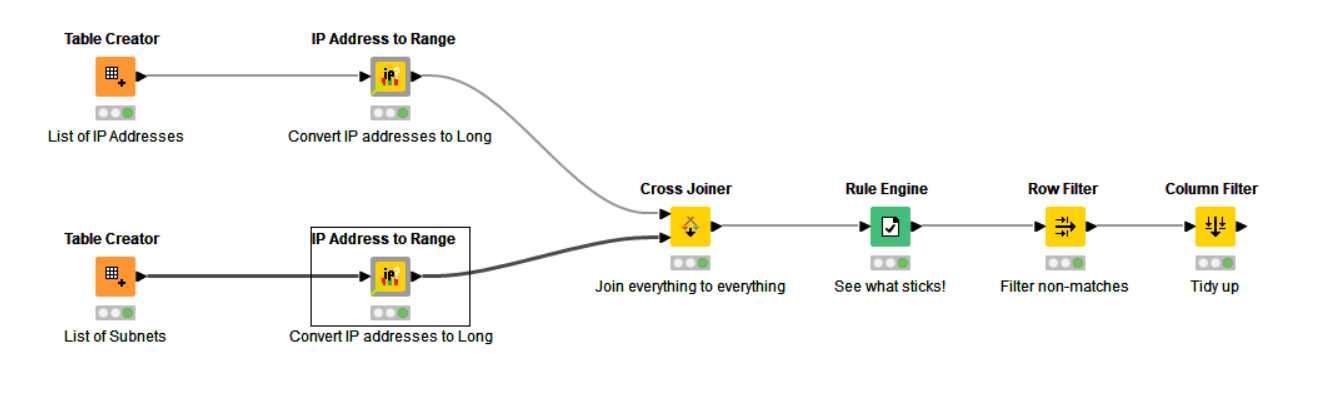
In the attached workflow, I’ve then compared the two outputs as follows, using a Cross Joiner which will compare every row with every row. This is used because the standard Joiner node doesn’t allow us to perform “between” joins. However this can work surprisingly well even for (relatively) large data sets but obviously there will be an upper limit on the size of lists you’d want to compare this way, as you do get the product of all the rows from the two inputs.
To keep it small, you could potentially put the comparison into a “chunked loop” so that it only compares a small number of ip addresses with the full list of subnets at any one time, to keep memory usage down.
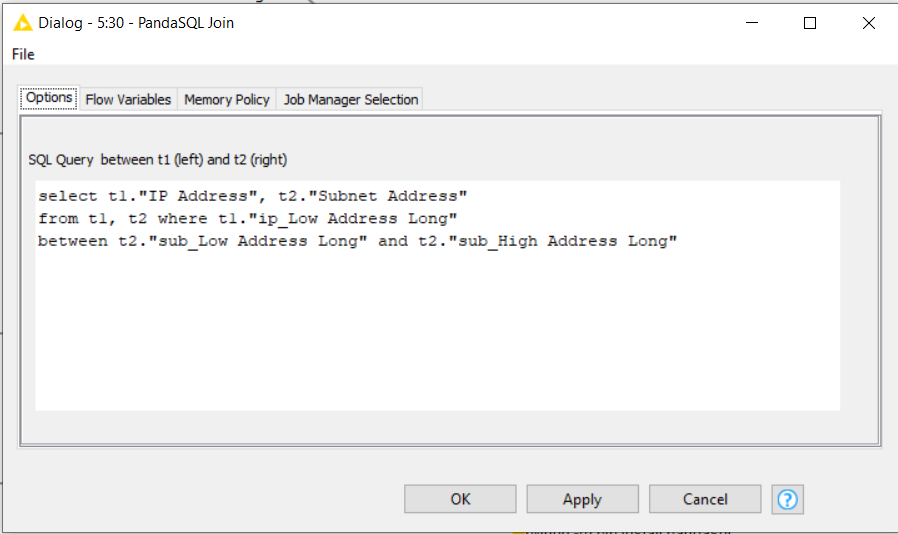
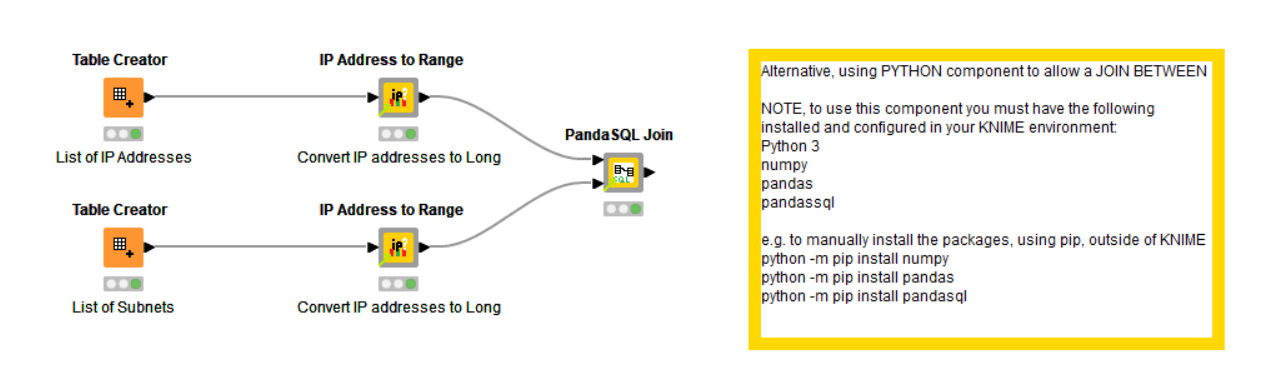
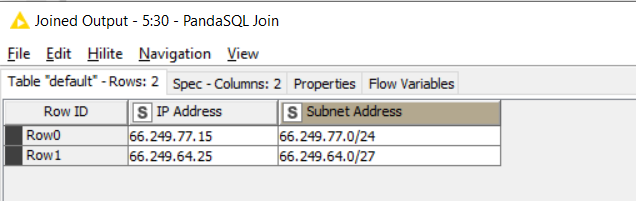
An alternative to the cross joiner, if you have Python 3 installed with your KNIME environment, is to use my “PandaSQL join” component. This takes the two data sets and uses SQL with a between statement to join them. You do need to know some basic sql. You join T1 (top input) with T2 (bottom input)
You will also need the following python packages installed:
numpy,
pandas,
pandasql
I think KNIME requires numpy and pandas anyway, so probably pandasql is the only additional package needed if you already have python.
With my sample data set, the end result is as follows:
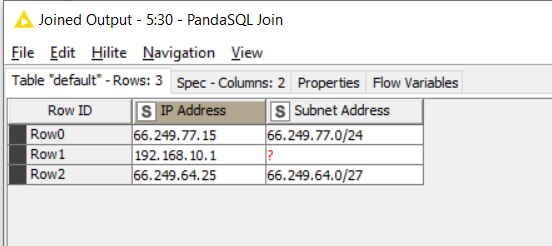
If you modified the SQL in the PandaSQL component to:
select t1."IP Address", t2."Subnet Address"
from t1
left join t2 on t1."ip_Low Address Long"
between t2."sub_Low Address Long" and t2."sub_High Address Long"
you could have the following output…
Here is the workflow:
Test ip address in subnet.knwf (3.4 MB)
Would something like that work for you?
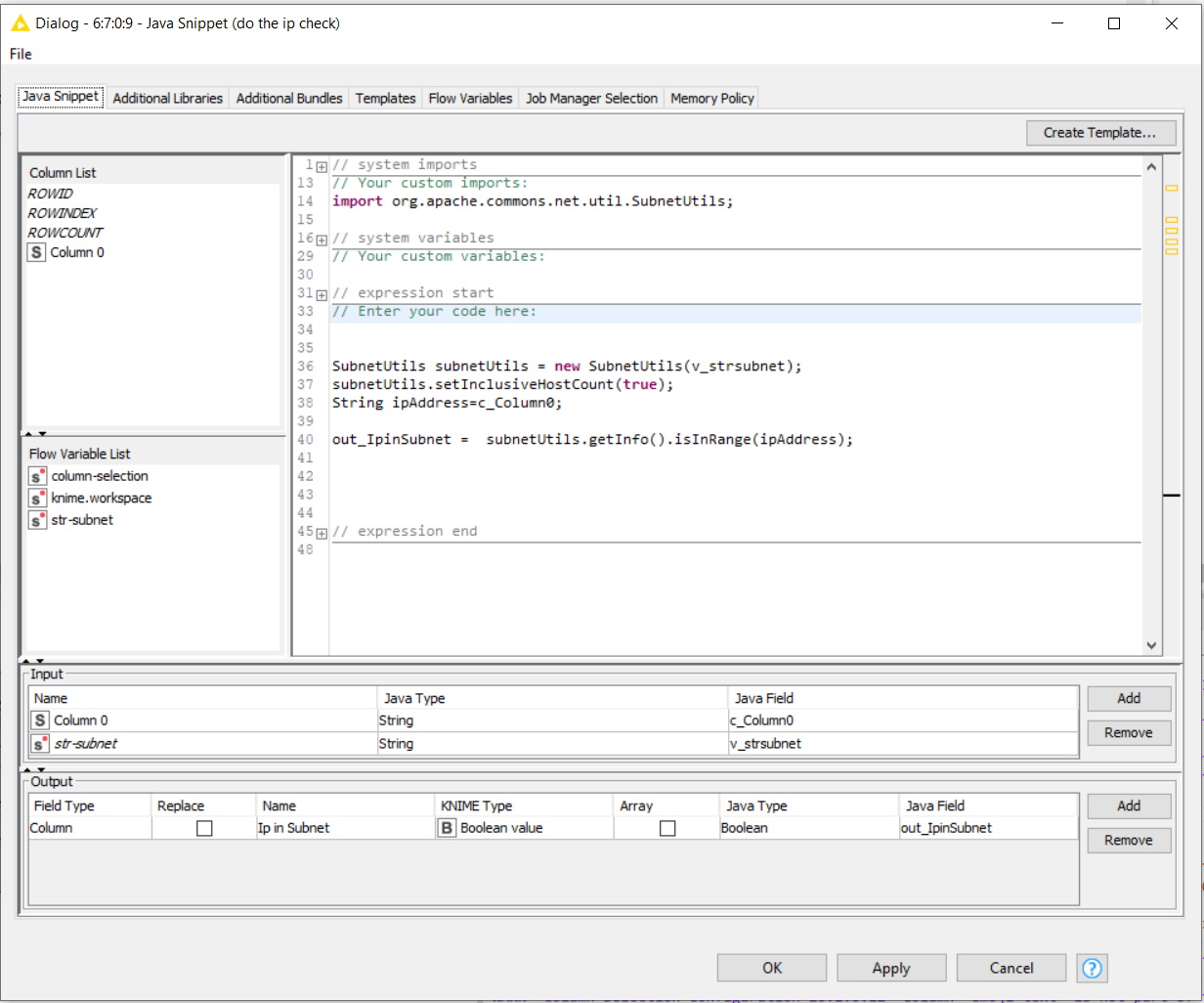
The components I have used are: