I’ve been doing some research on my issue and exploring various solutions.
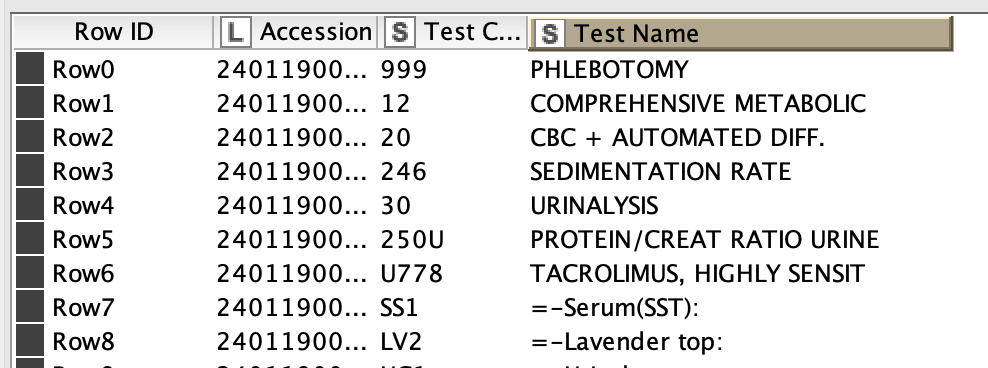
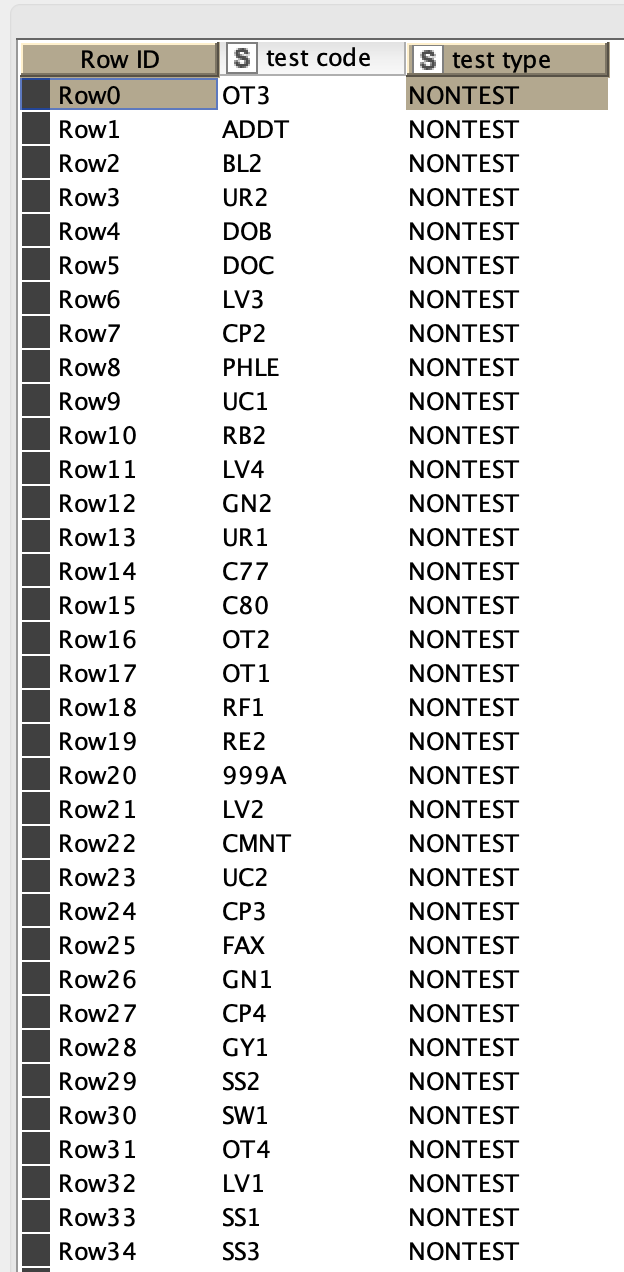
The case, input excel sheet with a log, input excel sheet with a “dictionary” of values, join the test type from the dictionary file to the log and filter out the specific test type. Here is what the sample data looks like:
Posing an example using the data outlined above, in theory the join should show that SS1, LV2, etc… are NONTESTS. No matter what I do and which approach I take I don’t get the right result.
What output do you get - only missing values? What kind of join are you doing? Are you sure there are no hidden spaces (or other characters) in the respective test code columns? It would be a lot easier to try to help you if you could upload sample tables and your current workflow.
@rfeigel were you able to get there proper result after doing this?
Even after doing the string manipulation I am facing the red question marks when joining. On a side note, how were you able to detect those hidden characters?
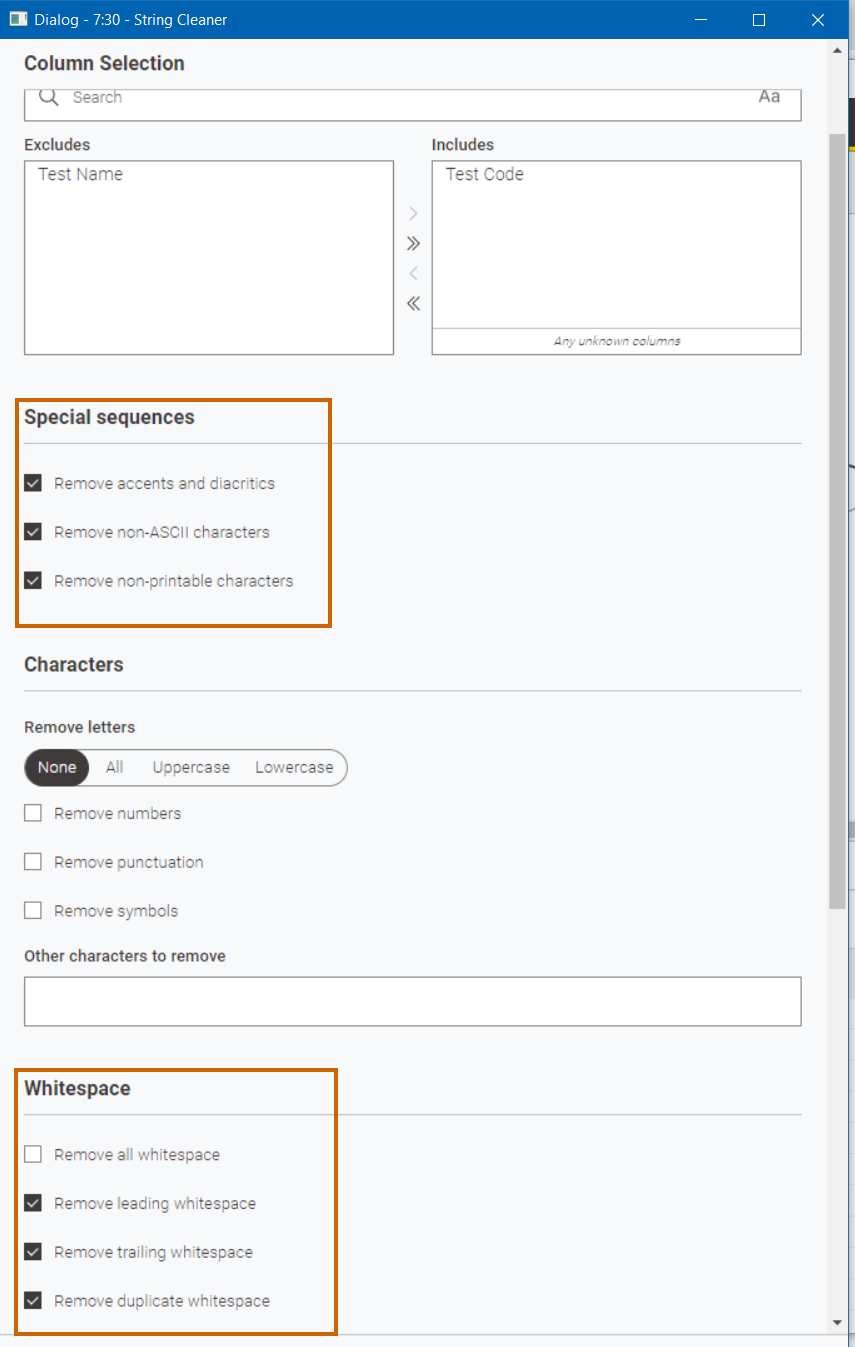
As you are using KNIME 5.2, you can also possibly make use of the new String Cleaner node to help you here. As has been mentioned already, there are differences in the codes in the two tables in the forum of space padding.
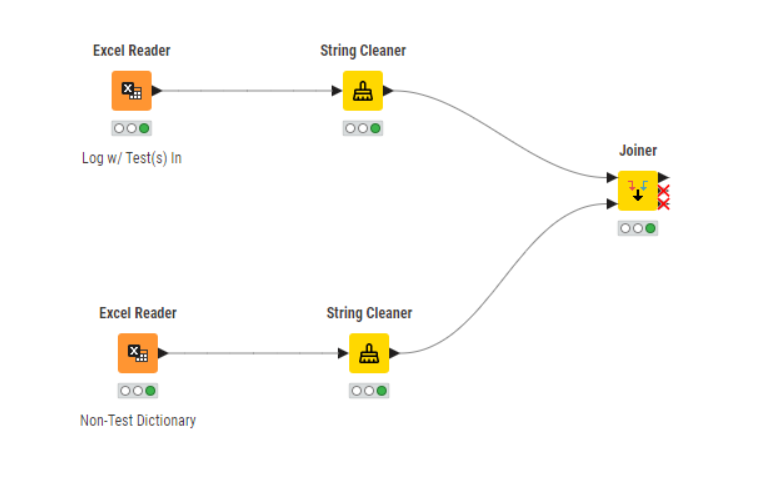
Adding the String Cleaner after both Excel Writers for good measure, they can be set to remove leading and trailing spaces and a variety of other potential problems:
I gotta start keeping up with the new nodes coming out
Thank you so much @takbb !!!
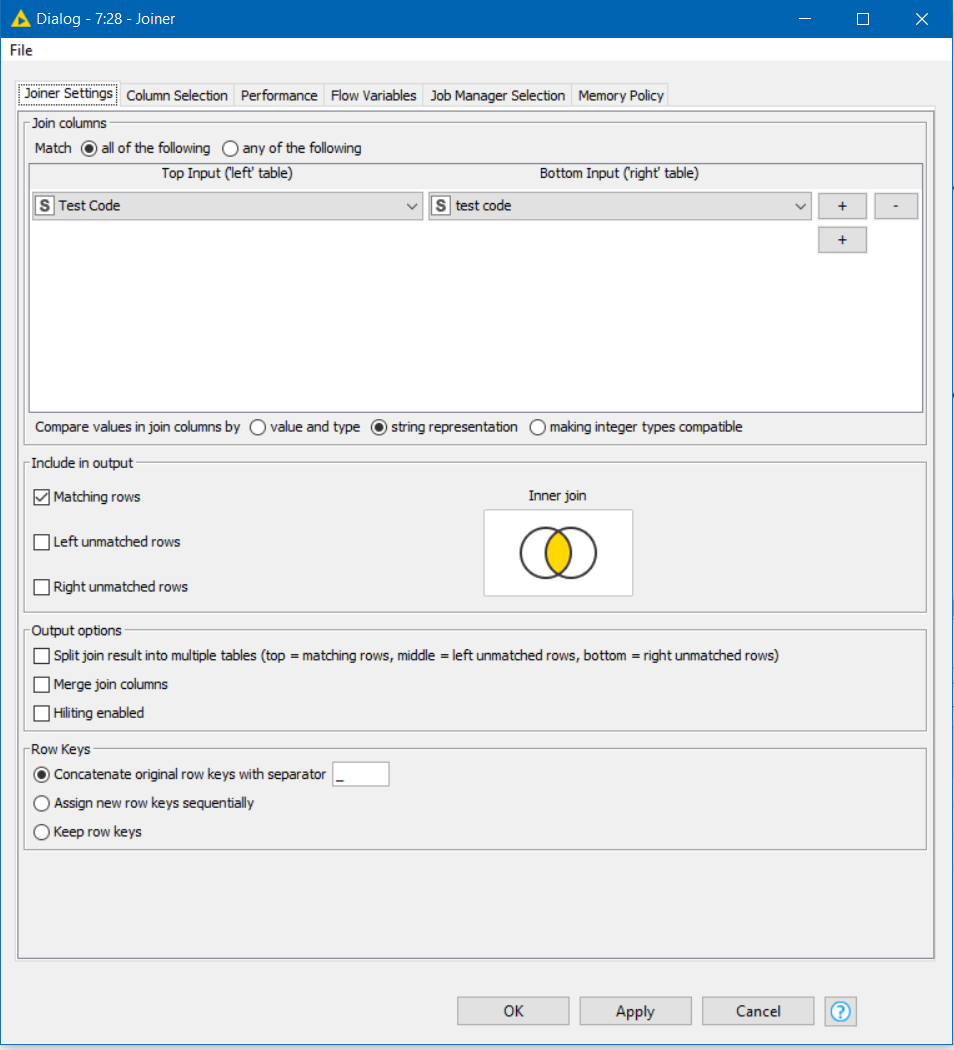
This one worked to see all the ones that are matched. But I want to see matched and unmatched, where it is unmatched it would be blank there. When trying the left unmatched. I checked Matching Rows and Left Unmatched Rows
The regexreplace function in the screenshot removes hidden characters just like the String Cleaner node @takbb suggested. His approach and mine produce the same results although the String Cleaner is probably easier to use.