Hello Community,
I am wondering if you have experience using the OpenAI nodes to analyze PDFs within Knime?
Many thanks!
Best regards,
Ricardo
Hello Community,
I am wondering if you have experience using the OpenAI nodes to analyze PDFs within Knime?
Many thanks!
Best regards,
Ricardo
I think you are talking about retrieval augmented generation (RAG).
There are example workflows available on knime hub:
https://hub.knime.com/knime/spaces/AI%20Extension%20Example%20Workflows/2)%20Chat%20Model/2.5%20-%20%20Retrieval%20Augmented%20Generation%20ChatApp~nBhjtxPFqFxnqGst/current-state
There’s also a full video play list out there which touches on this topic:
https://youtube.com/playlist?list=PLrVumvjxxTkAZSYZmYsazEtXqd_VWxqdE&si=Ys653B51-oD1PWE3
And a video from knime:
")
Thanks a lot Martin! I am actually trying to give an Open AI node to a list of links to PDF’s. For example, suppose you have 10 links. Each link takes you to a PDF that is 10 page long and contains the economic analysis for an specific economy for 10 different past quarters. I want to use a node or combination of nodes that as last output is a table with the links and a summary (based on my prompt). Each row has in Column A the link and in Column B the summary. Does this make sense?
I see so it’s just summarization.
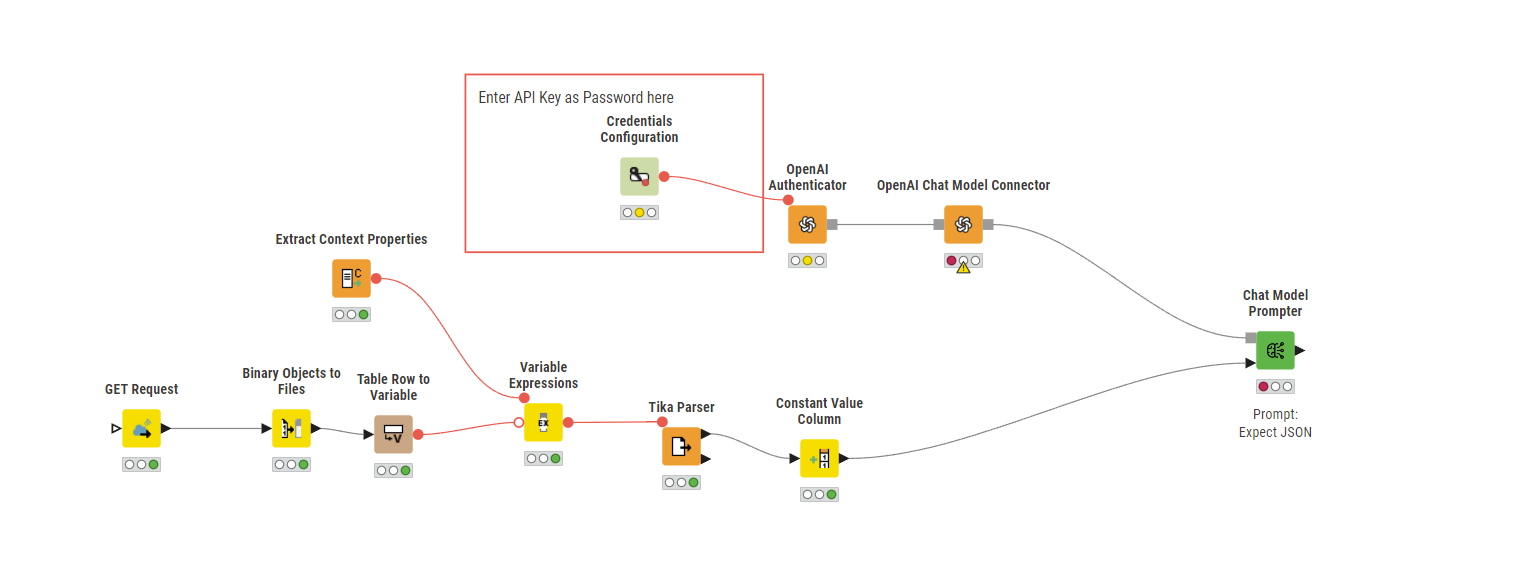
There are still some variables that may influence the solution, but I’ll share one possible approach on the assumption that the PDFs contain primarily text (i.e. no need to extract images / tables and to have them processed via LLM)
In that case:
I’ve set up the basics in this prototype workflow:
downloadPDFandsendtoOpenai.knwf (1.3 MB)
Overview:
Depending on your needs you can also try to leverage OpenAI structured Outputs - e.g. let’s say you want the summary to have somewhat the same structure - e.g. GDP Analysis, Inflation Summary… you can provide a schema that defines for the OpenAI LLM how to structure the response.
I have a workflow that implements using this via a component here:
And an Article on Medium here:
If you are OK with installing an extension I have implemented a structured output prompter and a node that converts a table to a valid schema - you can find the details here:
Hi Martin,
Thanks so much. This is great. And may I ask another follow-up question. Is it possible to get an OpenAI node to understand and summarize charts and tables? It seems your solution will only push words so I am wondering about understanding and summarizing other stuff like tables and charts that typically are many within this type of PDFs
well… let’s say it depends.
When you use a node like Tika Parser it extracts all information in text format - that means it includes the information in tables as well, but without maintaining the “tabular” structure. When asking the LLM to summarise the information will be included. In general LLMs tend to be fairly poor in understanding tabular data and as far as I know this has not changed.
With regards to images: Yes, there are LLMs that can be fed with images as inputs. That said right now, at least with the nodes included in the Gen AI extension that was developed by KNIME, it is not possible to send images to an LLM. As a work around I can point you again to my extension above, which includes a vision model prompter node or alternatively there is an example workflow from @roberto_cadili that takes care of this via POST request:
So in your context there are some additional challenges:
So my thought right now is:
I did test gpt-4o-mini, but not the stronger gpt-4o models - from an expectation perspective I think that the stronger gpt-4o models probably perform similar to Anthropics Claude 3.5 Sonnet (which did very well on this task when I tested it in the video above)
Edit: If you also think it’d be great to have the ability to prompt vision models using the KNIME-developed GenAI extension I’d appreciate for you to “vote” for my feature request here ![]()
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.