I hope someone here can help me… I’ve googled already so much and have also asked ChatGPT for help, but somehow my workflow is not working.
The “problem” goes as followed: I have a carbon emission result for my base year 2023 (e.g. 6,059,046,747 kgCO2e) and I have growth factors for that emission from 2024 onwards. I would want to calculate the 2024 emissions by multiplying 2023 times growth for 2024 and then take the 2024 result and multiply it with the growth factor for 2025 to get the emissions for 2025. This calculation should reiterate until e.g. 2030, by always taking the previous year and applying the growth factor.
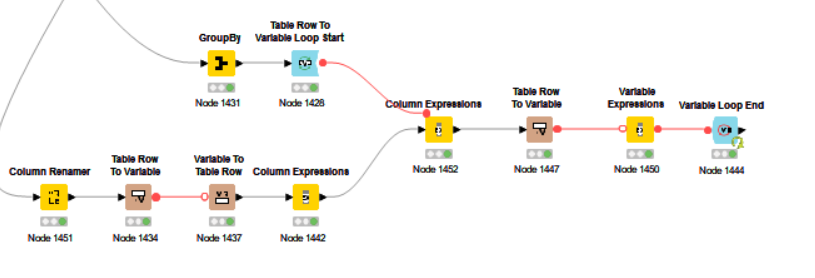
Grouped emission data into one number and renamed the emission column to “initial_emissions” (#1451)
I send the emission number through a table row to variable node (#1434) next, which is then connected to a variable to table row node (#1437).
In the column expression node (#1442) I am duplicating the initial_emission column under the name “previous_emission”
Grouped growth factor data (#1431) to a table with column A – years and column B – growth factors (FC – Growth)
Connect growth factors to a table row to variable loop start (#1428)
In the column expression node (#1452) I’m calculating column(“previous_emissions”)*variable(“FC - Growth”). The results are saved under the column “calculated_emissions”
In the table row to variable (#1447) I’m only including calculated_emissions
The variable expressions node (#1450) now renames the calculated_emissions column to previous_emissions
I end the flow with a variable loop end
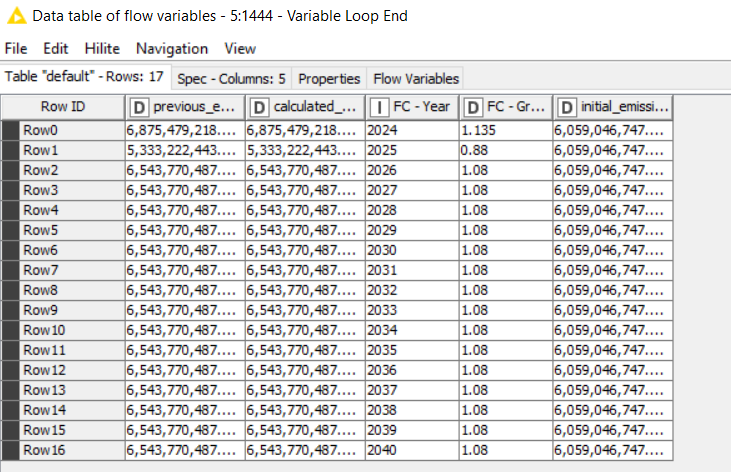
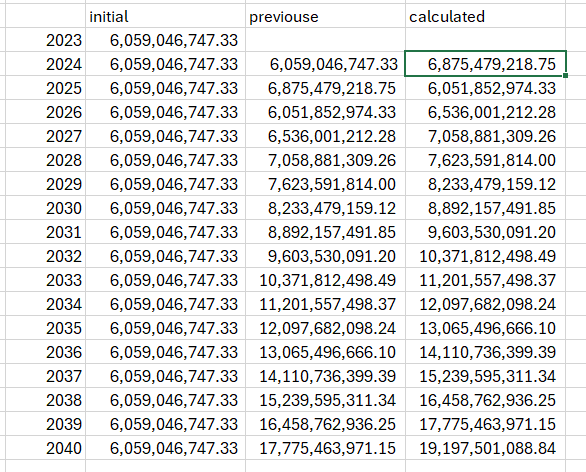
In my results the calculated column gives me the emissions as if I would apply the growth factors always to the base year, so it is not taking the new calculated emission for the next year, see screenshot of result table. I don’t know what I am doing wrong or what is missing. Could you please help me?
Is there any chance you could upload your workflow, or at least the part of it that you have pictured in the screenshot, along with some sample input data.
I would think there are a number of people who can probably help you with this, but they are almost certainly going to need to work through the flow to determine what needs to be changed, and also be able to see the input data because it is difficult to picture even though you have documented the above very well (kudos for doing that!).
Obviously remove anything sensitive. We just need to be able to execute the workflow even if the data is fictitious
thank you so much for the quick reply!! Ok, it makes sense to upload the workflow as well to open up the nodes thanks for that feedback.
Since the raw data is quite small I’ve created a new workflow and added the data with table creator nodes. So hopefully it should be fine to just upload the workflow without any additional documentation.
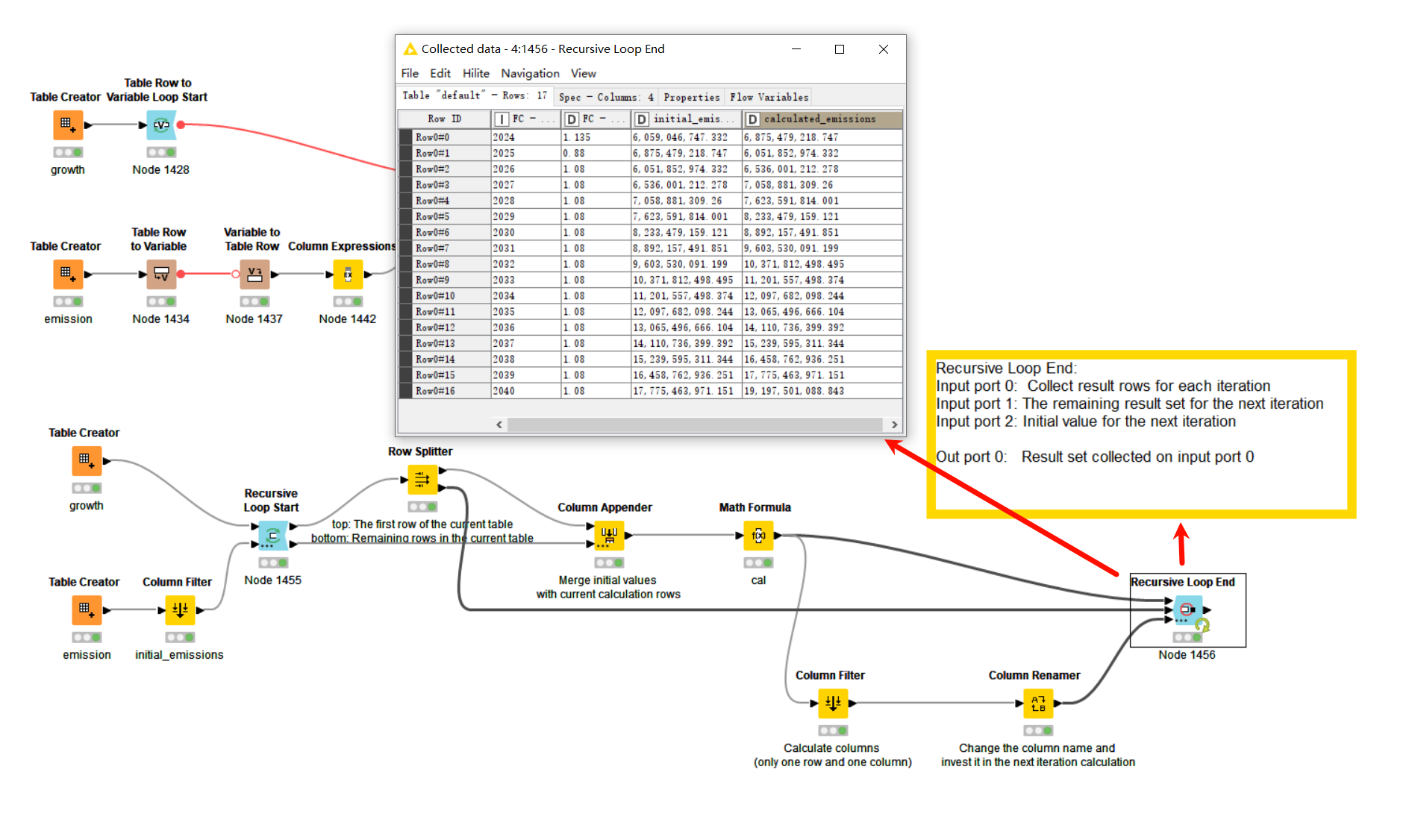
Ahhhhhhh @tomljh you are a genius!! It worked perfectly Honestly, I would have never solved the issue. THANK YOU for your help!
If it’s not too much to ask… could you help me out in widening the scope of the calculation with a more complex data entry (I need both workflows for the flow I’m working on). So the more complex raw data splits the base year emissions in Group 1 and Group 2. Each line is unique. 2024-05-24_emissions by group.xlsx (9.9 KB)
Respective to that, the growth assumptions now also include the Group 2 characteristic. 2024-05-24_growth by group.xlsx (10.1 KB)
Should I somehow first join the both data sets before the loop? Or how would you tell the loop to match the growth factors based on grouping 2?
I tried further requirements and implemented them using an additional “group loop start/end”.Please check the final output, I’m not sure if I have correctly understood your data.
Of course, appreciation where appreciation is due and you killed it twice!! Thank you so much there is still a lot for me to learn, but I’m happy to know that if there is a major roadblock the KNIME community is so nice and helps each other out. Thanks