Hi @Mirri, although on the face of it your sample data and required results looks like a “pivot” transformation, the Pivot node cannot be directly used here without some additional assistance.
The reason for this is that the pivot needs to know what your new column names will need to be, based on attribute values from your data.
I’ll try to explain this here by way of your example.
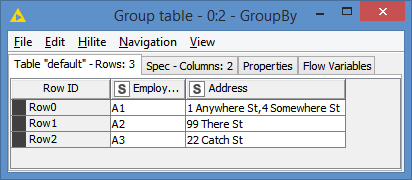
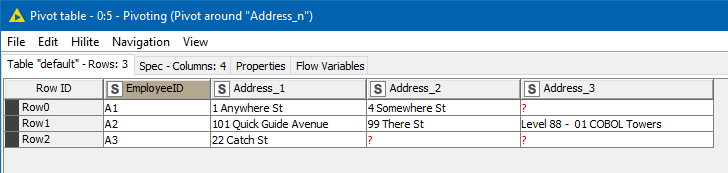
Your original data set simply has EmployeeID and an address, but (ignoring the inbuilt Row ID) there is no “key” to your data, that identifies a row uniquely for a given address. In effect you are wanting to break your data up into “Address_1”, “Address_2”… “Address_n” but the identification of which address is which, is not indicated in your data set.
We can see that implicitly your data is as follows:
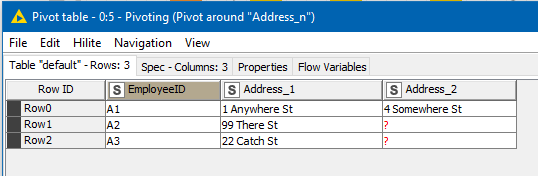
and if it were in this form, then Pivot could work, because it would be able to identify the different addresses using “AddressKey”. You would be able to “pivot your data around AddressKey”.
Specifically… if your data were in this format, you would be able to Pivot it by telling the Pivoting node to :
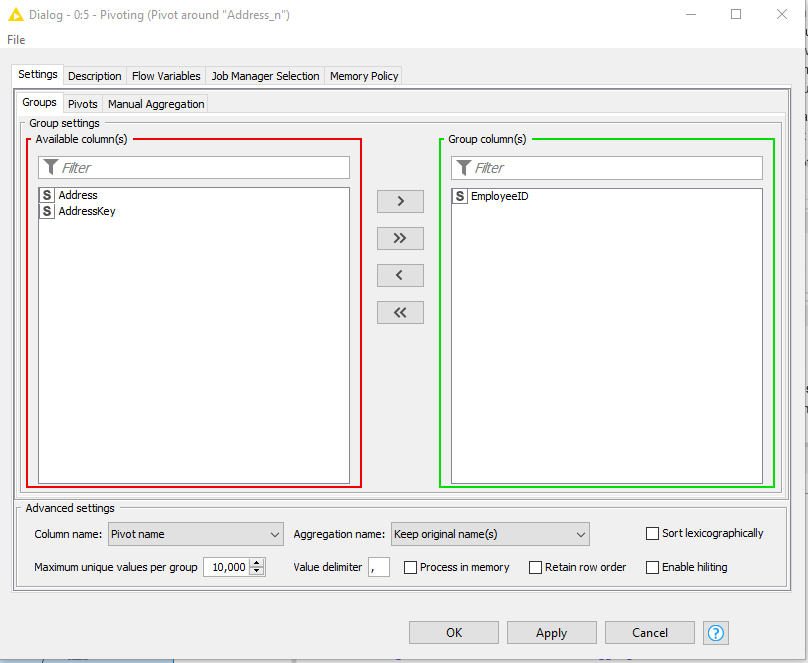
(1) “group by EmployeeID”
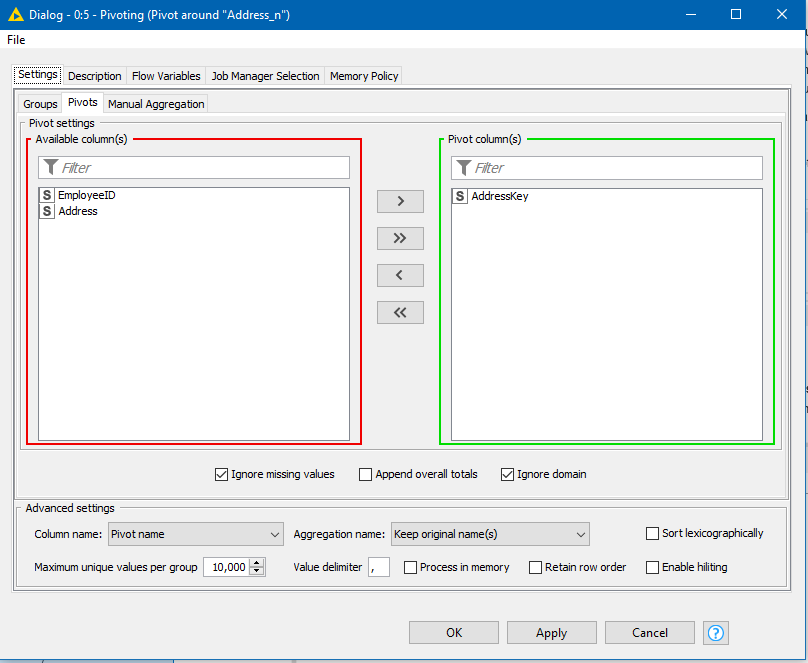
(2) “Pivot around AddressKey” (this is the “Pivots” tab)
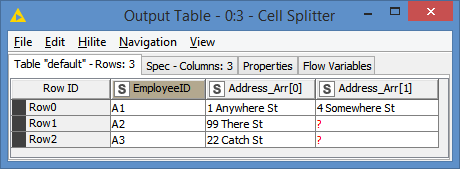
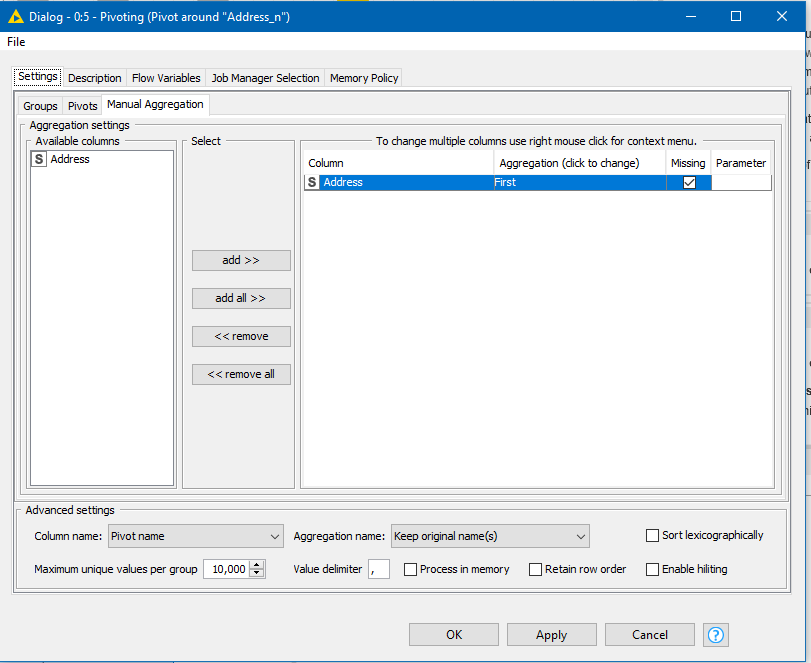
(3) And Aggregate the addresses. (As you simply want to take each individual address and put it into its individual output column according to the “AddressKey” I can choose to simply take the “first” address for each Employee/AddressKey combination, as together, this returns only a single address)
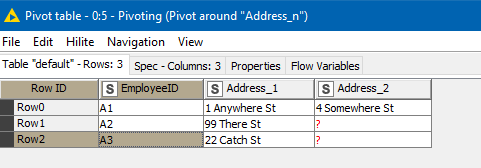
This would then produce the desired result:
HOWEVER…
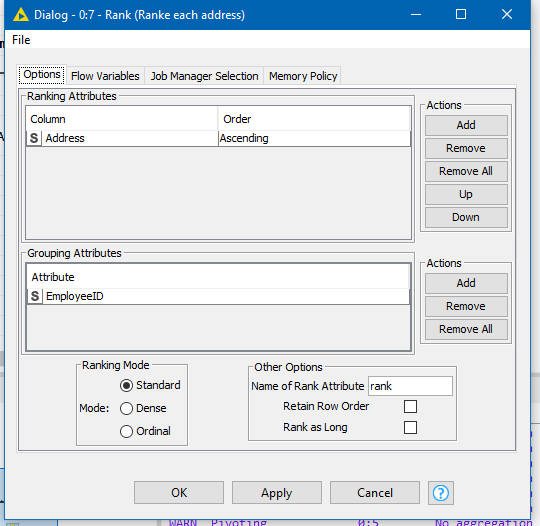
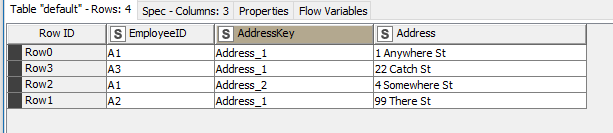
Of course your data doesn’t have this “AddressKey”, so for this to work, you would need to create it. One way of doing this would be using the Rank node and a String Manipulation.
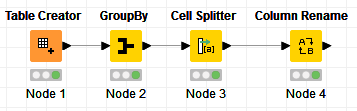
I’ve borrowed @bruno29a 's flow here to use as the example data:
Ranking addresses in order of appearance within EmployeeID using the following config:
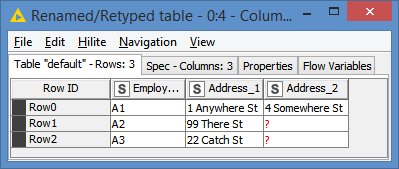
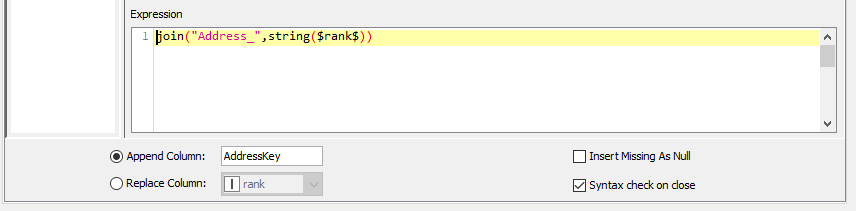
followed by a String Manipulation to create the AddressKey “Address_n”
returns the following dataset:
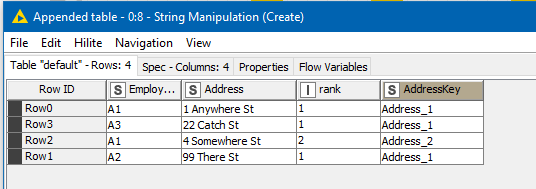
As you can see, we now have the required columns to enable the use of Pivoting. We can discard rank (simply by not including it in the Pivoting node config) and “pivot around” AddressKey as described above, and the output is as follows:
If we extend the sample data slightly:
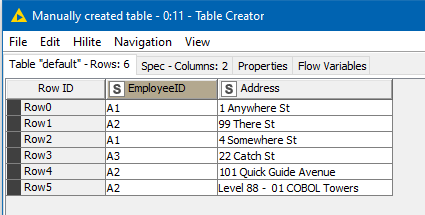
You can see that the output extends:
In this case, pivoting has not saved on the number of nodes used compared with @bruno29a 's example, and of course either method can be used effectively (although you may have to change the choice of delimiter character used by Group By and Cell Splitter if your data sets contains the chosen character e.g. commas !). Hopefully this might help a little in understanding how Pivoting can be made to work for you.
Pivot example.knwf (15.5 KB)