Hi everyone
I am currently trying to build a solution which is able to read multiple PDF files and extract specific data. I cam across a previous post which mentioned the use of TIKA and then further using RegEx to search for the data items I’d like to extract.
I downloaded the solution previously posted “Data extraction/processing from PDF and other files”
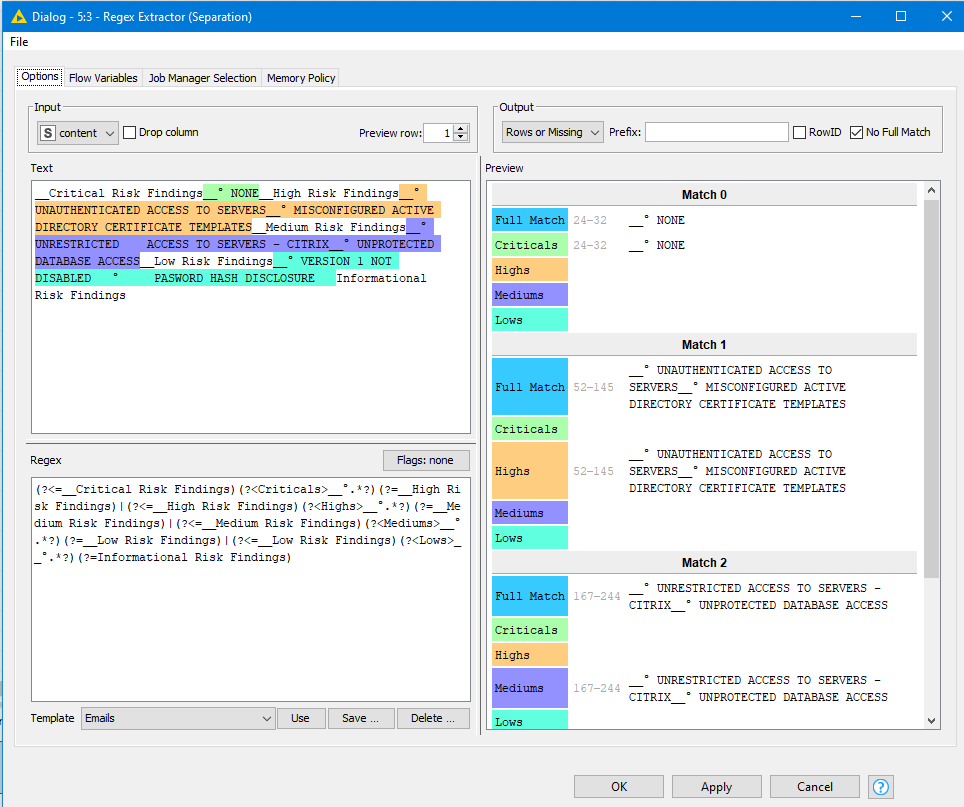
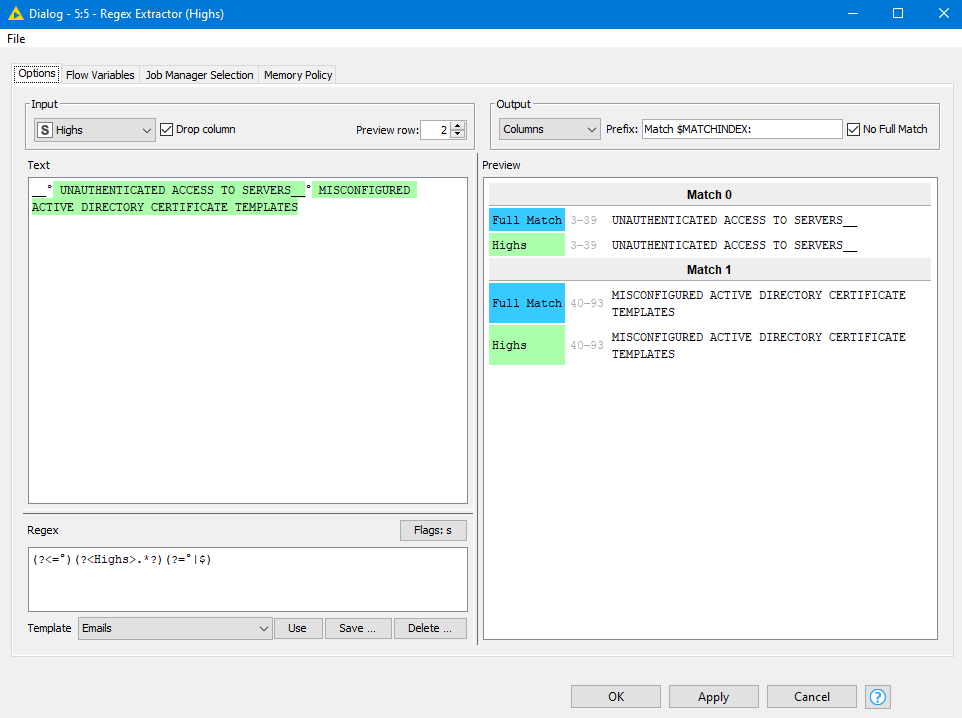
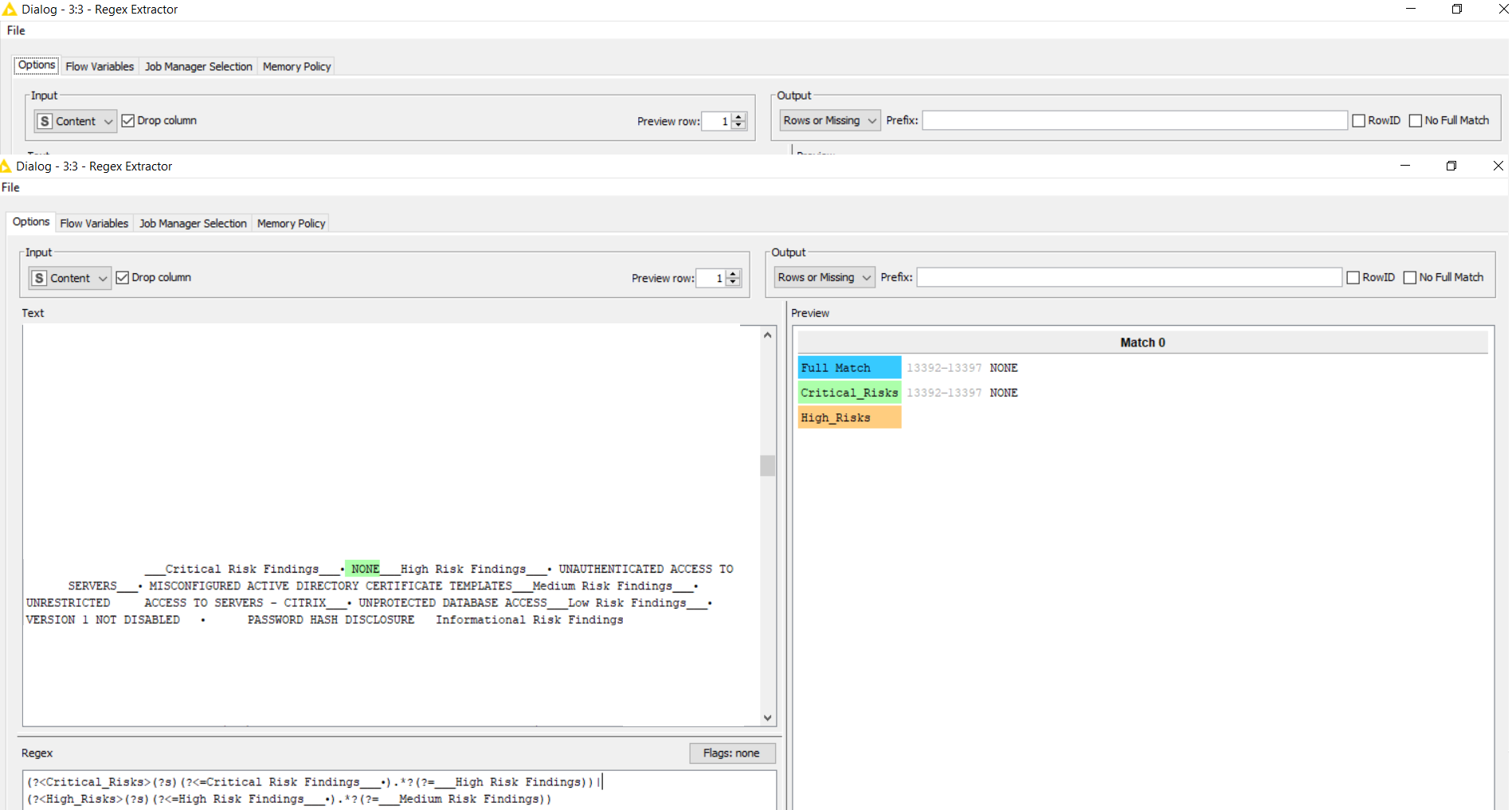
I used the solution and changed the parameters such as the PDF folder. When it comes to changing the RegEx, I have problems. I have built them and tested them in online tools and the expression works, but what doesn’t seem to work is that as soon as I have multiple expressions trying to extract different items, it only collects the data for the first.
In the solution above, they are fetching multiple items form the document and that is exactly what I am trying to achieve.
Hoping someone can help.
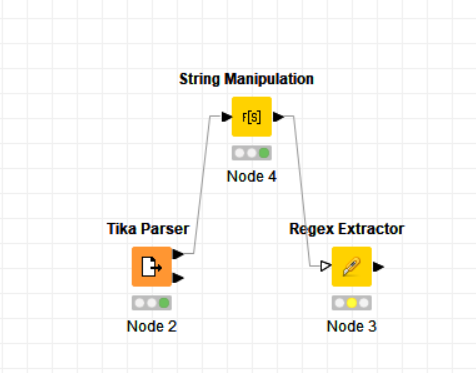
This is the code I am using and the data fragments I am trying to read into critical, High, Medium and Low risks (Code only shows for Critical and High now for testing purposes) - I did sanitize the data to ensure I can provide enough detail for assistance.
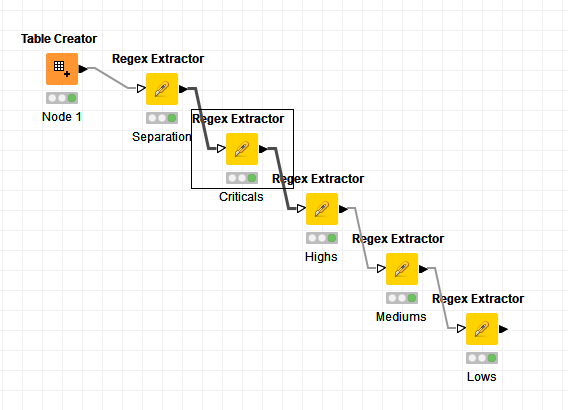
Here is the view of the workflow: