Hi @npatrick , what character set encoding are you using, and how long is the data that you are inserting?
UTF8 consumes 1-4 bytes per character depending on the character. Is your string data generally western alphanumeric characters and punctuation or is it using other non-western alphabets / characters? That would make a difference to the bytes consumed.
The Snowflake varchar datatype can be defined up to the default max size of 16MB but this defines the number of bytes rather than the number of characters, so a multi-byte encoded character set will use potentially more than one byte per character in your strings, meaning that a string containing fewer characters than the defined max number of bytes could be too long.
Since your definition is only for 16 thousand characters rather than 16 million, there would be plenty of scope for defining them twice that length, or even four times the length and seeing if it then works. Snowflake only uses the data size required for the actual data and so defining a varchar column to be larger than needed does not waste space.
Unfortunately i have yet to find a reliable and quick way of determining the maximum byte length requirements for specific string data when using UTF8 and have hit this problem before where my data character count was near but not exceeding the maximum 16M byte column limit.
Hi @npatrick ,
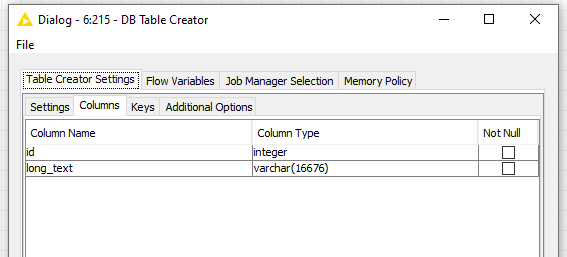
are you sure that the table was recreated in the DB Table Creator node e.g. did you check the “Replace existing table” option in the Existing Table Handling section? To double check the column definition you can also execute the DESCRIBE TABLE command via the DB Query Reader node in KNIME.
Bye
Tobias
@tobias.koetter, that was exactly the problem - when using the DB writer node, the replace table option was checked, which (of course) replaced the table. My colleague saw the answer in another post, so was able to make the correction.