I was wondering if it would be possible to add an option to exclude counting missing or even count the missing values only when using the Collection Size node?
The use case is, when creating a List or set with missing values to ensure after ungrouping all ends up in the right spot again, I want to quickly check without ungrouping if there are any missing values and then maybe discard them all together / reprocess.
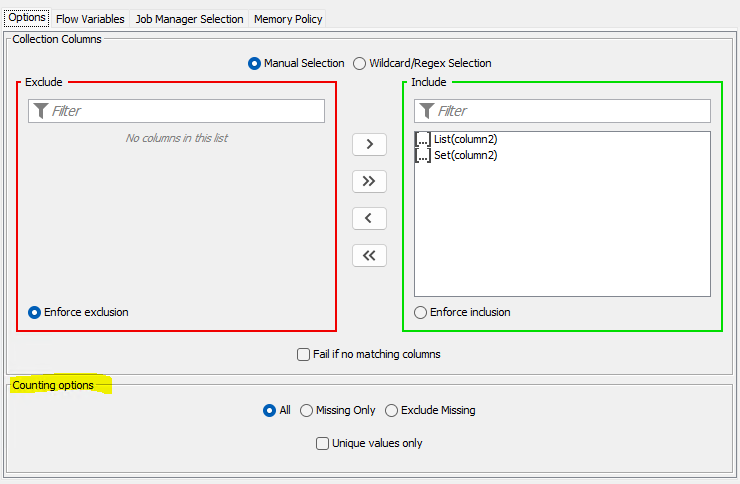
I’ve added both the requested options, and also an additional option to only count the unique (or ‘distinct’ in SQL or Java Streams nomenclature) values (for a set column there’s no effect with this, as they are always unique, but for a list, it saves going via an intermediate set)
Existing nodes will acquire the new options, but keep their behavior (i.e. the new options will be populated as shown, and the output count columns will be ‘int’ types). New nodes added to workflows will also default to these settings, as they seem to be the most obvious defaults, but the output count columns will be ‘long’ types
If that all looks ok to you, then I will try to get the public version updated in the coming days?
It should now be available in the nightly build/trunk channels, and the stable channels for KNIME 5.3.x and KNIME 5.2.x. I’m hoping to get it out in KNIME 5.1.x and 4.7.x too, but there is an issue I need more help resolving before that can happen.
Thanks again for the suggestion - definitely one of those “Why didn’t we think of that sooner?” ones!
Some sort of help I might be able to provide giving back something maybe?
About
“Why didn’t we think of that sooner?”
Did you, as the de facto leader in collection nodes, thought about doing math with collections containing numerical values similar to „matrix magic“? Bonus for nerds, doing that using the GPU