Dear KNIME community,
I am working on a Data Analytics project and thanks to the KNIME team I managed to generate virtual data so I could train the models better. The workflow they showed me was the following from the KNIME Forum: Data Generation Example: Supermodels)
Using the workflow they sent me the Decision Tree worked well as a preliminary approach, predicting good/bad parts (using 3 input variables).
The aim of the analysis is to identify the ranges of the inputs which will lead to good parts. A Design of Experiment have been conducted and the input variables have the following shape:
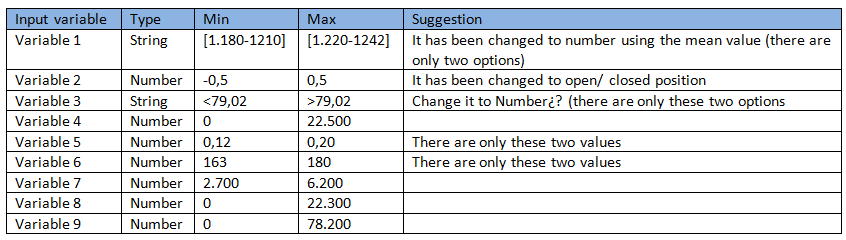
The output variable is a OK/NO OK type, meaning good/bad part.
I want to identify the combination of ranges of the input variables which will lead to good parts, so I can understand better the manufacturing process.
I hope you can guide me in the appropriate workflow or which nodes are the ones I need to use. I heard that a possibility might be virtual experiments but I am not sure how to apply it using KNIME.
Thank you very much in advance.
Kind regards,
Aner