Wait node waits for a certain time, to a certain time or for a file event (such as file creation, modification or deletion).
But Wait node only runs on the local file system.
I want to this node to run for a DB table event( such as create, insert, delete …)
Hi @jjlee , can you may be explain why you are trying to do this? Is this to make sure you do not run another statement before the current statement completes? If that is the case, you can just link the nodes, and whatever links from the output (right) will run before the node that’s link from the input (left).
And if the nodes do not have a data port, or even no input nor output ports, you can use the Flow Variable ports to link them.
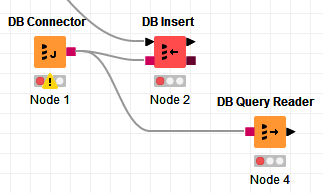
For example, if you have this:
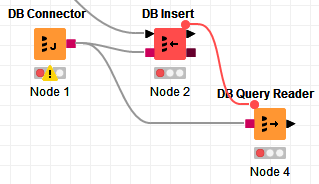
The DB Query Reader (Node 4) could execute before the DB Insert (Node 2). If you want to make sure that the DB Query Reader executes only after the DB Insert, simply link them like this:
Now, the DB Query Reader will only execute if the DB Insert is completed.
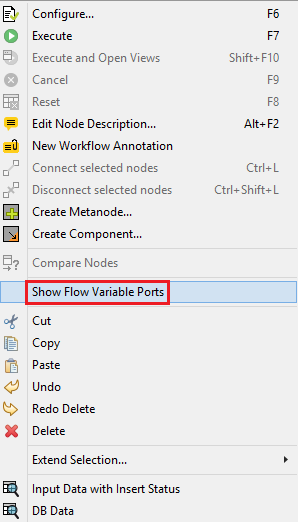
If you are not familiar with the Flow Variable ports and have a hard time using them, you can right click on a node, and choose the option “Show Flow Variable Ports”, like this:
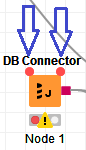
It will show you the Flow Variable ports of the node, like this:
This is much more efficient than using the Wait node - you’d use the Wait node when you are doing batch requests to a website for example, or batch email send out, among other examples, where you do not want to abuse the system by flooding them and wait between the batches.
Let me explain why I am doing this.
I don’t insert table in DB in Knime.
When new data is inserted into a table in a specific DB path, I want to detect it and runs a node that reads the new data.
Hi @jjlee , I’m not sure I fully understand your use case. If I would take a guess, are you running the workflow with an infinite loop where you want to wait for an X amount of time between the loop iterations and check for new data?
A better way would be to run the workflow at specific times, and this can be done via the command line.
In the thread below, I discussed the disadvantage of having the working running constantly via a loop, and how to run it via command line instead: