I have one web page that contains a table that we would like to parse out. I was able to use GetRequest and xpath to get the data for the table, however, the table content (in xpath output) seems to have lost the table format. Also finding the right table in the preview window wasn’t easy. Would selenium node be easier to use? Here is the web page I’m sourcing from: https://www.sec.gov/Archives/edgar/data/1537140/000158064217005048/swanfundsncsr.htm
I also need to look at SEC filing data, one example is N-CEN form, which can be downloaded from SEC as text. I used GetRequest (can’t get HttpRetriever to work due to proxy issues) but couldn’t parse out anything using htmlparser and xpath. The file isn’t pure xml (with xmlnamespace appeared in the middle) but it wasn’t a problem when I used beautifulsoup in python to parse it. Here is one example of the public filing data: https://www.sec.gov/Archives/edgar/data/745467/0001145549-18-005124.txt. We are mostly interested in the content between edgarSubmission tags. Any pointers would be highly appreciated.
(1) I’d definitely suggest giving the Selenium nodes a try, especially the Table Extractor node which is for conveniently converting an HTML into a KNIME table. (the Selenium Nodes are a paid software, and there’s a free 30 day trial available)
(2) This doesn’t look like the ideal use case for the HtmlParser – instead I’d try to extract just the XML document (starting with <?xml version="1.0" encoding="UTF-8"?>), converting it to a XML cell and then to use the XPath nodes.
Hi;
I’m using selenium nodes. At first I did the tests as a trial version and now I’m going to pay for it. The result of my work is this: It allows you to fully import data from any web page and automate the process in receiving data, including encrypted entries. I would recommend as a user.
qqilihq,
I tried Selenium webdriver followed by find elements. After webdriver opened the web page fine, the find elements DOM retriever timed out. I suspect it’s due to proxy again. Please see the errors. Any pointers would be highly appreciated.
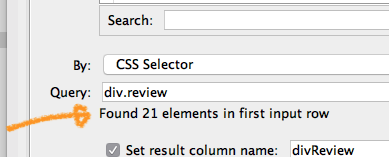
this is definitely not a proxy issue here, at least as long as the page loads fine in the browser which is opened by Start WebDriver (could you confirm this?). If you see an error from Find Elements, the issue is likely rather that the given query is wrong. You can easily see, if the query works (i.e. returns an element) by checking the info text below the query input:
If you’re still having trouble, feel free to post the workflow here (or send it to me at mail@seleniumnodes.com in case you rather not share it), and I can have a look once I have some spare minutes.
PS: In case you’re a newbie with the Selenium Nodes, or web scraping in general, I’d really suggest to have a look at this blog post by forum fellow @armingrudd:
– Philipp
PS: Re. “proxy issue” mentioned here: I didn’t have time to investigate this further, but it’s not forgotten. I’ll get back about this during the next days.
thank you. The query could be an issue, but I was relying on the preview to find out the exact path needed by the query to retrieve the table. I didn’t know the preview would be dependent on the query. I actually made a change in the preference in the KNIME to “parse html source” instead and that enabled the find element preview. I then searched and found the table that I needed (still not sure if that’s the best way), then used CSS selector to help define the query. This works fine in the retrieval. If there are other better ways, please share some examples. Thank you in advance.
Following-up on the content of the table extractor. Because the HTML table isn’t so regular, I would like to further filter on the content table like this and eventually populate the table(s) in a relational database. What nodes do I use next? Is there any good examples of table extractor usage?
Thank you. I tried row filter using row Id and it works to some degree. However, since a lot of web pages we process can have the content change from month to month. For example, the table I extracted for portfolio investment could have different number of rows next period. I would have to rely on something more dynamic so it can be automated somehow. I imagine I can parse and identify some values in cells like “Total Exchange” and grab the rows before that row into one table, etc. etc. However, is there anything Selenium nodes provide that could help avoid making the process too complicated?
Thank you both. I attached my workflow for your reference. To answer the two questions:
the section is the table after the following line:
SWAN DEFINED RISK FUND
PORTFOLIO OF INVESTMENTS
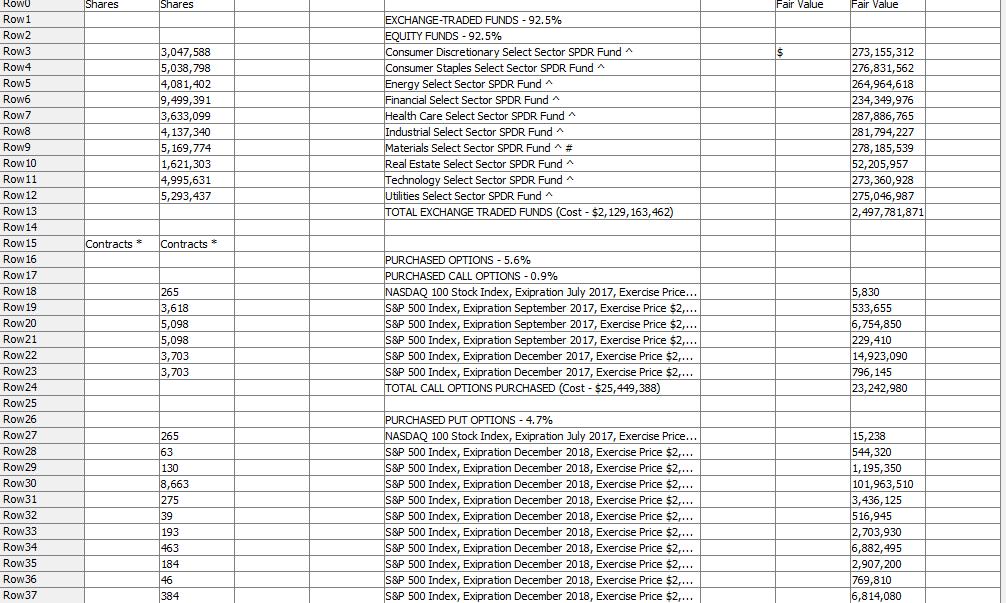
the table can be identified as table[34]. However, since this is not a well designed web page (likely just ported from a word document), the table may appear as a different table[n] in the next month reading. Is there anything we can utilize to automate the manual searching on the text before the table? And once we get the table, as I pointed out earlier, the content could vary. I can see using another searching to find the Total row and do separation accordingly to make the workflow re-executable, but would like to know the best way to do this without getting too complicated.
assuming the question is about the output of the table extraction - I attached a picture of the mapping of the fields. On the high level, this will be split to two tables - one would be the list of holdings +shares and the other one is summary (the rest of the tags, level 1 and level 2 etc.). I can see using the row filters/column filters to do manual mapping. But how do we make this repeatable for next period?
Thank you in advance for all your help!![Swan_extraction|690x240]Swan_SEC_Scraping.knwf (125.5 KB)
(upload://ibfwCXaSp9rTNq5nLXl8YMIFc44.jpeg)
Thanks for the explanation. Now I know what exactly the inputs look like.
I need an example of the output you want both for the table in the webpage (your 1st question) and the TXT file (your second question). Then I will do my best to provide you with a solution.
thank you. for the second question about XML parsing, I actually got a bit further - I ran into a performance issue and raised it in the forum in a different thread (XPath performance). Scott helped provide some answers, but my experience was still not ideal after changing the memory setting. I haven’t got time to look further on it.
For the first one, I found a spreadsheet that explained better than I did with the output. (see sampledatastructure tab). SDRAX Analytics.xlsx (65.9 KB)
The sampledatastructure tab is structured output format. you can ignore the first tab. The input is the table that I have in the workflow. Not to lose sight what I’m asking advice for - I’m mostly interested in is how to make the row filtering more dynamic, not just relying on the row Ids. If you could show that - even if the output is not exactly the same I think it’d be beneficial.
Dear @leahxu,
How did you calculate the day for the “expiration date”? I can see only the month and the year in the “Holdings” column. Anyway, I think you will be able to handle this one on your own.