Hi leahxu,
this is definitely not a proxy issue here, at least as long as the page loads fine in the browser which is opened by Start WebDriver (could you confirm this?). If you see an error from Find Elements, the issue is likely rather that the given query is wrong. You can easily see, if the query works (i.e. returns an element) by checking the info text below the query input:
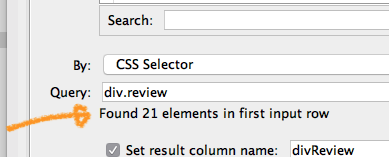
If you’re still having trouble, feel free to post the workflow here (or send it to me at mail@seleniumnodes.com in case you rather not share it), and I can have a look once I have some spare minutes.
PS: In case you’re a newbie with the Selenium Nodes, or web scraping in general, I’d really suggest to have a look at this blog post by forum fellow @armingrudd:
– Philipp
PS: Re. “proxy issue” mentioned here: I didn’t have time to investigate this further, but it’s not forgotten. I’ll get back about this during the next days.