Hi,
I want to retrieve data from web page Złoto Inwestycyjne - Sztabki Złota, Złote Monety - Mennica Polska as a table containing name and price for every product.
I used node Webpage Retriever and Xpath in which I input “/html[1]/body[1]/div[1]/div[1]/div[1]/div[2]/div[2]/div[1]/div[2]/div[1]” for first price but I received empty cell.
How to obtain all data without opening subpage for every product ?
Marcin
Hi Marcin,
generally, it would be great if you could provide some current state with your attempts, e.g. an example workflow. That way, other users can better understand where you’re heading and have a testing workflow available to get you an answer to your question faster.
I’m not sure we can build the complete workflow for you; that would be more of a consultancy request, but with the XPath node you can select the type of item you want by clicking it in the preview (in my example below I wanted all “entry” items within a config). When you then hit Add XPath you get a predefined query and can select “Multiple Rows” as output, if you expect multiple matches.
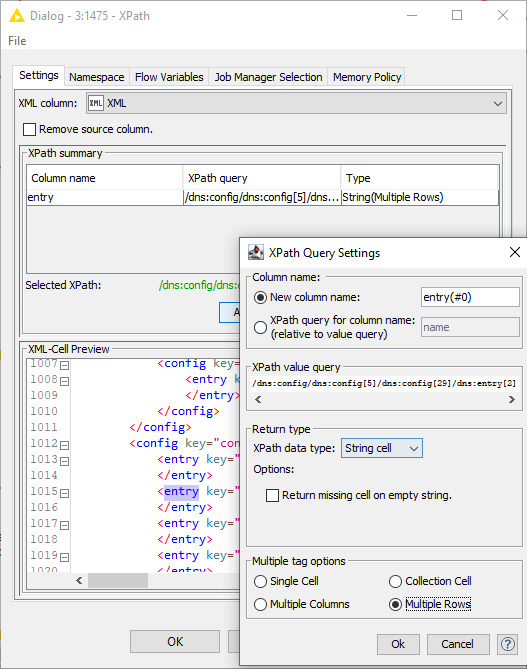
If you want to manually edit the query, you can read up on the syntax here:
Kind regards
Marvin
1 Like
Hi,
Thank you for your reply.
I insert my workflow with other examples where I was able to retrieve data without opening subpages.
inwestycje.mennica.com.pl.knwf (273.6 KB)
Kind regards
Marcin
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.