I’m trying to create a web scraper with Selenium nodes.
Basically I’m struggling to use the loop nodes to build something which gets the details page, then returns to the main page. I’m struggling to build the concatenation in - so it adds the detail for each page scraped. Please help!
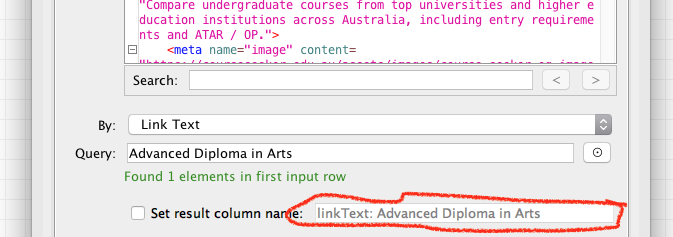
basically, the problem in your workflow is in Find Elements: Node 63: You query for an element by its text, and in each iteration, the node will create a column with a different name, as the default name of the appended column is created from the query:
The solution is simple: Check the [x] Set result column name, and specify a column name which will remain constant within each loop iteration, and instead remove the Flow Variable configuration in Node 64.
This should already do the trick.
Best,
Philipp
Additional tip: Instead of the Execute JavaScript node, you can also use the Extract InnerHTML node. This makes it more obvious, what’s going on in the workflow and you don’t have to write any JS code:
you’re right. I just had another look, and there are still some minor gotchas:
In the first Find Elements, make sure to check Wait for x seconds. This will make sure, that the node waits until the elements appear on the page and avoid an empty table output (when loading the page in a browser, you’ll probably notice that the page appears, and the courses a little bit later … at least when you’re on a slow German internet connection like me ):
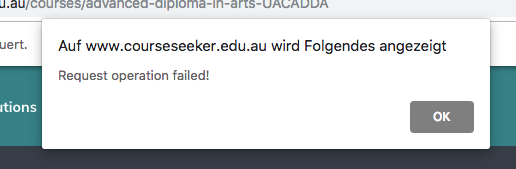
At this point, I started the workflow, first iteration worked fine, but in the second one I saw this error:
Frankly, I’m not sure why this error appears (I assume it’s some site-specific peculiarity). However, the fix is quite easy: I changed the Navigate node from Navigation type Back to a fixed URL (i.e. the one which you also specify in the Start WebDriver node.
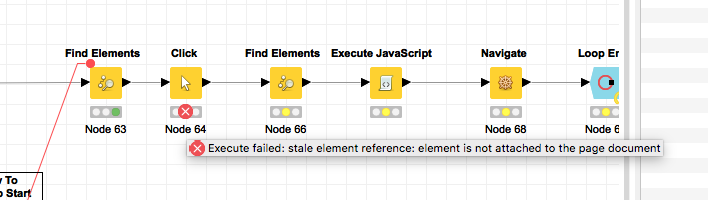
Okay, next run. At this point the loop seems to be working fine, until iteration 8, and then we receive this error:
My current assumption is, that this is triggered through to the way you construct the queries in the second Find Elements node, or that we’re still running into a synchronization issue.
I’ll get back about this tomorrow (in case you shouldn’t figure it out by yourself) – for now, bed time for me.
If I change the settings on 63 to find first match only it moves past that issue - but then I miss a course! I assume I need to track a different HTML snip for the first find elements?
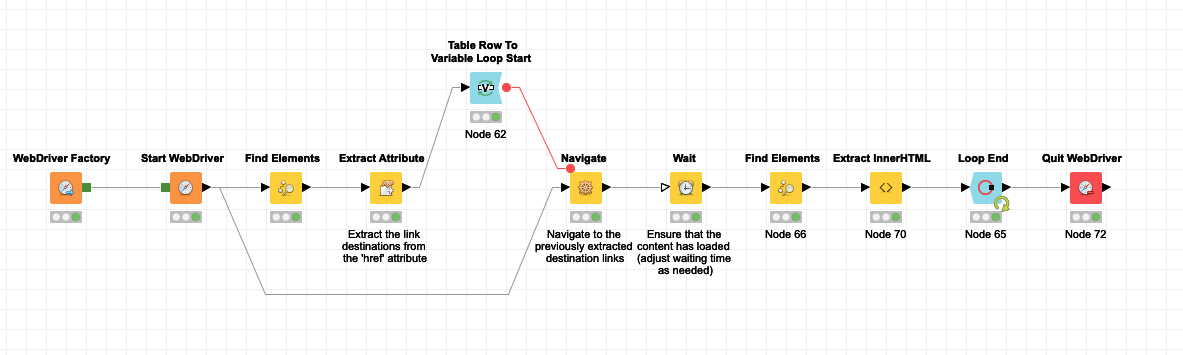
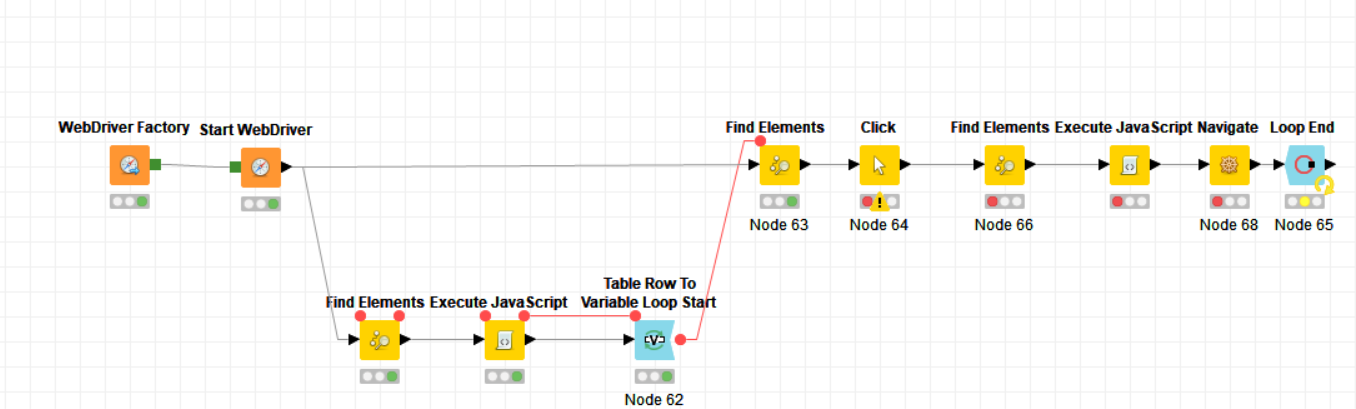
this indeed seems the issue. I just gave it another go and did some modification to make the workflow more robust. Instead of relying on the link text, I extract all the course link destinations (href attribute) in advance, and then navigate to the these destinations within the loop. The result looks like this:
The Wait node is necessary to ensure that the AJAX content has loaded on the course pages. Without this, you’d end up with extracting empty pages. With this node, the workflow will simply wait a moment before continuing the extraction (fyi: in a future release of the Selenium Nodes, we’ll add “conditional waits” which will allow to wait for a specific event to happen – e.g. “wait until an element on the page contains text”).
I’m now trying to manipulate the menus on the left hand side, but can’t work out how “check” and “uncheck” boxes.
I’ve found the class “popup-submenu-item-with-icon” but when I run a click on it, it won’t run. What’s the best way to interact with this type of tick box?
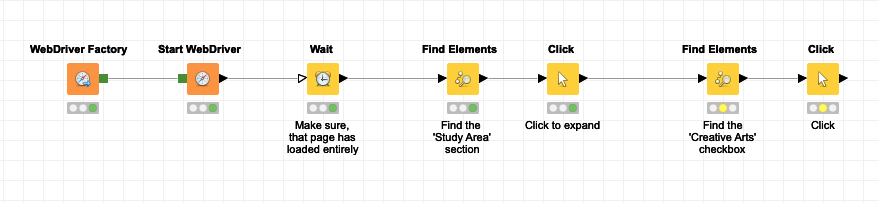
First thing to consider: Selenium will be picky when you’re trying to click non visible elements (i.e. even though they might be present in the DOM, they need to be visible on the rendered page before you can perform clicks). Else wise you’ll end up with an “Element Not Visible“ error.
So you need to make sure that you expand the corresponding menu (e.g. “Study Area”) first. You can do this with a combination of Find Elements and a Click node. To expand e.g. “Study Area“ you can simply search by Partial Link Text and enter Study Area into the field. Then connect a Click node.
Then, to select a an entry (e.g. “Creative Arts”), you should make sure to interact with an <input> element (clicking on a different element might work as well, but my experience tells that interacting with “real” form elements is the most robust way). To address the <input> element (in this case, this is the checkbox) for e.g. “Creative Arts”, you can construct an XPath as follows:
 ):
):