Hi Henry,
this indeed seems the issue. I just gave it another go and did some modification to make the workflow more robust. Instead of relying on the link text, I extract all the course link destinations (href attribute) in advance, and then navigate to the these destinations within the loop. The result looks like this:
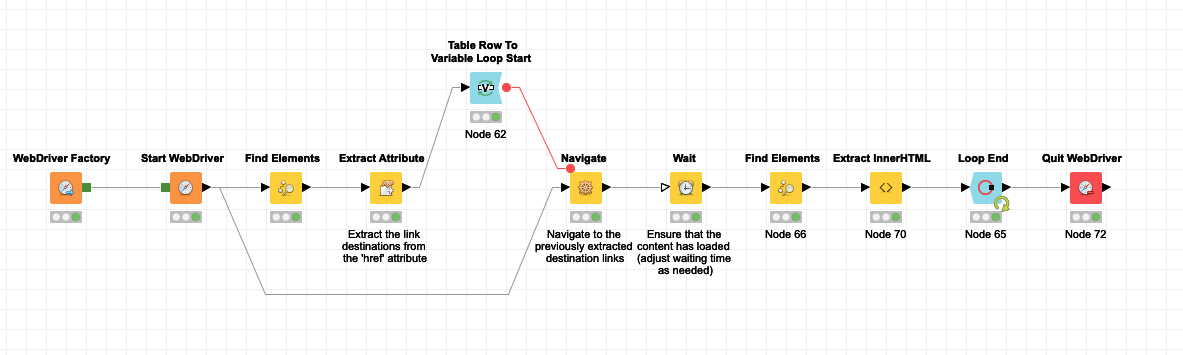
The Wait node is necessary to ensure that the AJAX content has loaded on the course pages. Without this, you’d end up with extracting empty pages. With this node, the workflow will simply wait a moment before continuing the extraction (fyi: in a future release of the Selenium Nodes, we’ll add “conditional waits” which will allow to wait for a specific event to happen – e.g. “wait until an element on the page contains text”).
Workflow is attached.
Best,
Philipp
CourseSeekerScraper.knwf (35.3 KB)