Join @victor_palacios for the webinar " PDF Text Extraction using KNIME, Regex, and Python" on Wednesday, August 17 at 5 PM - 6 PM UTC +2 (Berlin) which is 10 AM - 11 PM UTC -5 (Chicago)
In this webinar, we will parse PDF documents using the no-code, free tool KNIME and integrate it with code-based tools - Regex and Python.
PDFs bring a number of unique challenges. For instance, how do we know if the PDF is text-based or image-based? If text-based, extracting the text can be done with 1 node and a few clicks in KNIME. But if the PDF is image-based we need to perform Optical Character Recognition (OCR) first to extract the text. But what if we have thousands of PDFs of mixed types? Similarly, tables found in PDFs are almost always tough to extract, so what techniques does KNIME offer in this case? And can KNIME handle non-English or non-ASCII languages? Come join us for this 1 hour presentation with @victor_palacios (KNIME Team Member) who will tackle each of these interesting problems.
In this webinar, we will:
Learn different ways to read text- or image-based PDFs in KNIME.
Examine the quality of our input PDFs to understand our output.
Extract text from PDFs using KNIME, Regex, and Python integrations.
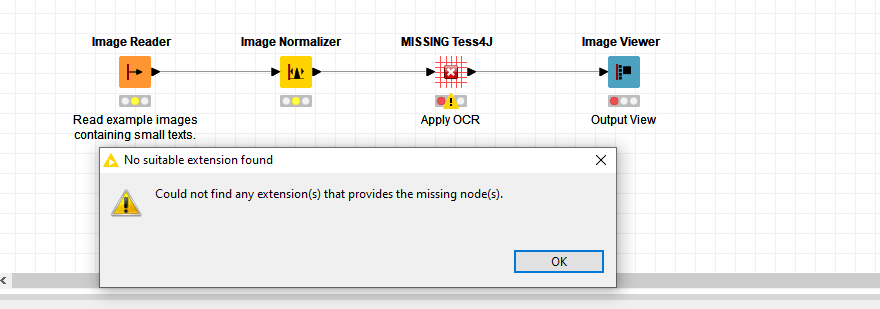
I am a little bit confused because not able to find tesseract integration in KMIME
Even automatically it is not possible
OC Windows, KNIME 4.6.1 vers.
Using archive files instead of direct links for installation and update (due to company`s limitation)