I am eager to build a productionized LLM use case for my organization, but the KNIME AI nodes are lacking some key functionalities.
There should be a dedicated node to split long text, similar to the text split functionalities of the PDFMiner & PyPDF python libraries. Both of these libraries use the recursive character text splitter I believe.
When creating a vector store, using the Chroma Vector Store Creator node for instance, there should be options to select the directory to store the vector store, and also an option to assign a collection name to the vector store. Then in the Vector Store Reader nodes, the user should be able to identify the right directory and collection to read in. Right now when I create a vector store with KNIME, I have no idea where it is saved so I am unable to read it in.
The Vector Store Retriever node should allow for the configuration of metadata filtering, this is super crucial to retrieve the most relevant documents.
I will be happy to hop on a call to discuss these further.
Yes, splitting text is not as convenient as it could be and we would love to improve it. I believe that the AP already has all the necessary functionality to implement this, so this might be a good opportunity for a shared component.
I am wondering why you need the directory the vector store is stored at? Do you want to access the vector store outside of the AP? Otherwise you can use the Model Writer and Reader nodes to save and load the vector stores to/from wherever you like.
I agree, this would be a very useful feature for more advanced workflows and RAG scenarios.
I tried different methods using AP nodes, yet I did not find anything satisfactory or remotely on par with the performance of the Python libraries. Right now I am having to supply KNIME with pre-split text. I can use the Python script node in KNIME to split the text, however, this would not be ideal if I am trying to promote a no-code approach to building an LLM solution with custom data.
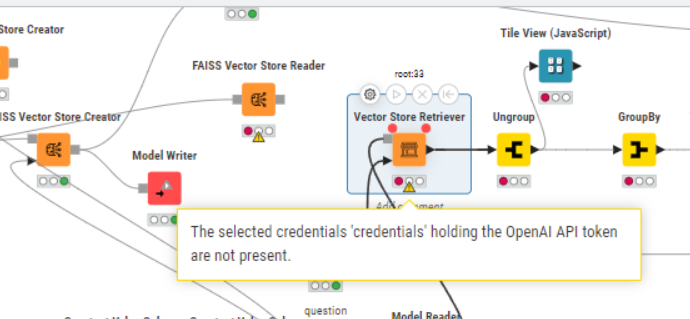
This is rather unintuitive and if I try to use the model write and reader nodes, I get an error message when I connect the model reader to the vector store retriever node. Screenshot attached.
Maybe I am missing something. If so, please what would be the appropriate way to query the vector store if I am using the model reader node?
Yeah it’s a bit of a challenge and I haven’t had the time to look into it more deeply, yet. However, I have a workflow that does some chunking: GenAI Document Exploration – KNIME Community Hub
It’s not using the recursive character text splitter but it might give some pointers on how to do it. I’ll also give that one another shot and will let you know how it goes.
Hmm, I see. The problem is that it is missing the credentials of the embeddings model you used to create the vector store because we don’t store the credentials in the model for security reasons. I agree that this is not very intuitive? Would a dedicated Vector Store Writer be more intuitive to you?
Thank you for your feedback, please keep it coming!
Adrian
I will check out the workflow you shared, but my point here really is that KNIME should have a dedicated text splitter node complete with the main methods used in the field. Without this, the LLM node package is incomplete as text processing is one of the key parts of building a use case with sizeable custom data.
Yes a vector store writer node would be the solution here. The issue I run into with the Vector Store Creator node is that if my workflow resets, I need to re-embed the documents and re-run the vector store creator node. This is an expense that should be avoided once the vector store writer node is created as I will be able to read the vectors at any point in the future without having to re-embed. Alternatively, the vector store creator node can be updated to allow the user to specify where to save the vector store so it can be retrieved in the future using the vector store reader node.
Hi @TosinLitics,
quick follow-up on the text splitter node: In 5.3 we will include a Text Chunker node that will make it easy to split text into chunks. If you are interested, you can already check it out in the nightly build.
Internal ticket ID: AP-22348 Summary: Support meta data filters in Vector Store Retriever Fix version(s): 5.4.1, 5.5.0 Other related open ticket(s): AP-22351