What is the main difference between PMML model appender and PMML transformation appender?
When to use PMML model appender and PMML transformation appender?
What is the main difference between PMML model appender and PMML transformation appender?
When to use PMML model appender and PMML transformation appender?
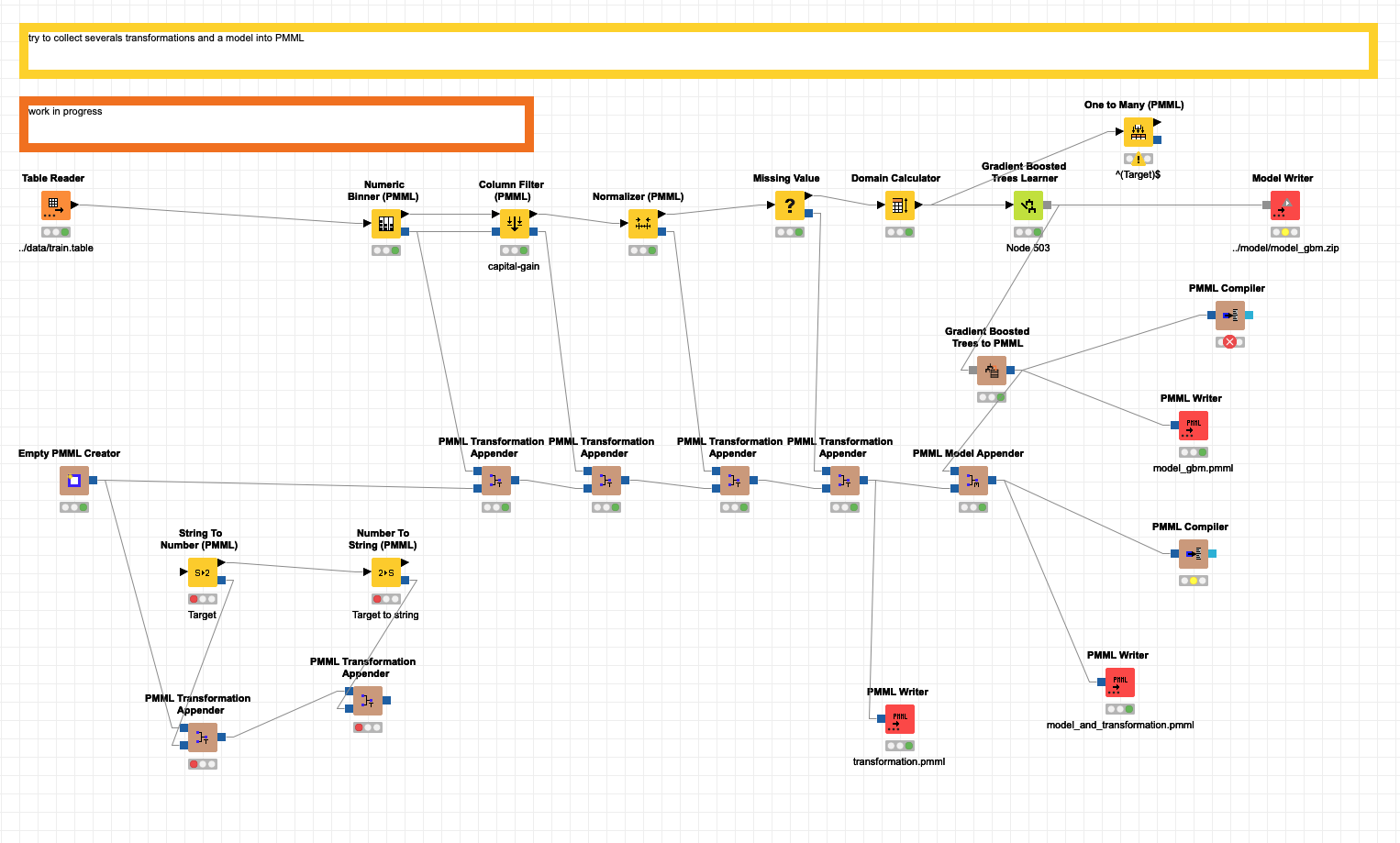
Here in this workflow:
We can see the difference is transformation appending (such as normalization) vs model appending.
If I understand correctly it allows to save transformation (like scaling) and the model together in one pmml file instead of storing both objects separately correct. Regarding performance or anything else it would work with 2 separate stored files as well?
thanks
br
@victor_palacios I now have been wondering for some time how these PMML combinations might work out. I do understand it in theory and there seems to be only one short example on the hub by @AlexanderFillbrunn.
Unfortunately once I started to try and use it in a slightly more complicated manner and especially store and read the PMML models back into KNIME the whole thing seems to fail. It might be small details that are not entirely have been worked out (dropping columns, renaming them …) - but the result it: this PMML combination and compiling does not seem to work in a nearly real life environment.
Maybe I am missing something:
And well yes I have tried several things. Reverting the order of the PMML input and so on ![]()
Hi @mlauber71,
I think this is a problem with the PMML Compiler, not with the PMML being generated. The PMML Compiler has been a part of my Master thesis many years ago and has not gotten much love since, to be honest. So at the time the goal was to support any PMML models KNIME can generate, but those models might have changed by now. Can you let me know what error messages the PMML Compiler node outputs when you try to use it?
Kind regards,
Alexander
@AlexanderFillbrunn the problem is not only with the Compiler but also if you try to apply the PMML ‘as is’ from the collection. Maybe you could check out the mentioned example. It is not very critical since all functions could be done with just using one PMML for each function.
Hi,
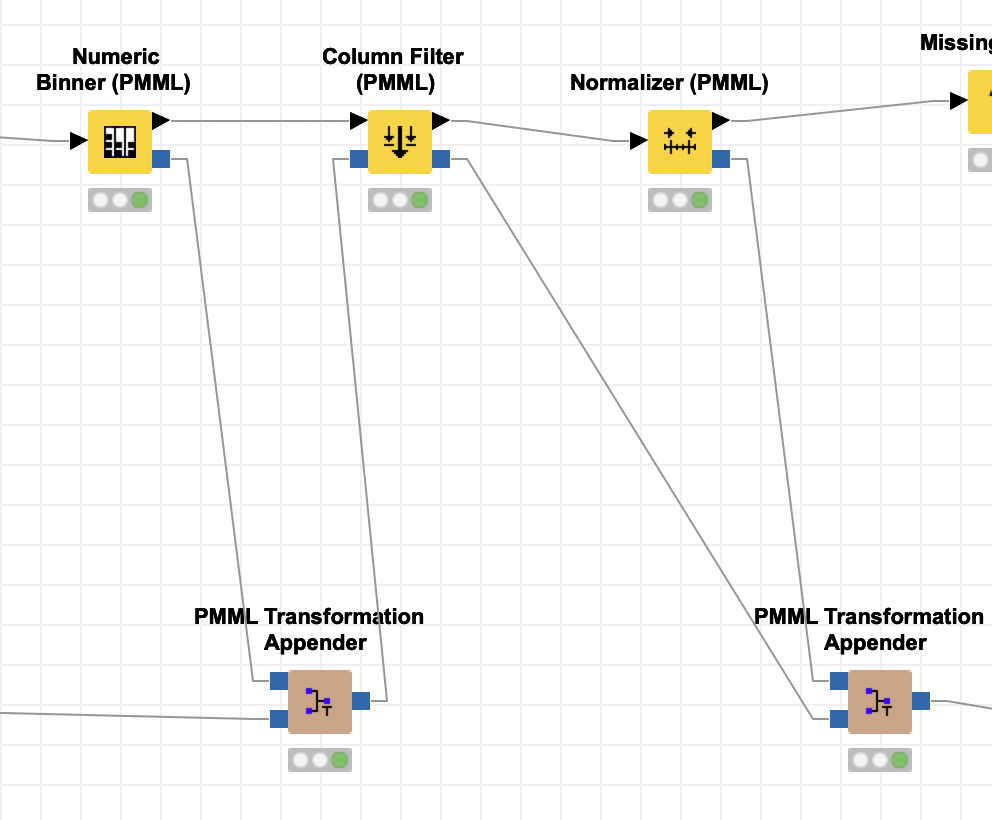
Thanks @mlauber71. I had a look at the workflow and I think I know what the main problem is: the Column Filter (PMML) filters the Data Dictionary of an incoming PMML document and outputs that, but PMML does not have any specification for filtering columns. So the new PMML created by the node does not really document the removal of columns, it just deletes every mention of them from the spec of the input data (the DataDictionary). It also keeps the TransformationDictionary as-is, so now the binner spec from the previous node comes into the PMML Transformation Appender from the top and from the bottom. The Appender now thinks that a new transformation for age_binned has been added and adds another entry in the TransformationDictionary, which is “overwriting” the old one, without really doing something new because it is actually just a copy. The Column Filter (PMML) must therefore be connected like in the screenshot below.
This issue is kind of a weird result of PMML not supporting column filtering/replacement and KNIME not documenting the usage of the PMML nodes properly here.
The Gradient Boosted Trees Model, by the way, is not supported by the PMML Compiler. The following model types are supported:
Kind regards,
Alex
@AlexanderFillbrunn the example was created to have something like a complete data preparation pipeline in PMML, though I did suspect it would not work that way ![]() - I sometimes have used compilation with reagrds to Spark execution. So one has to be careful what to coombine. Good to know, thank you.
- I sometimes have used compilation with reagrds to Spark execution. So one has to be careful what to coombine. Good to know, thank you.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.