I generated different classification models with 10 fold cross validation.
Do you think the best model should be the one with the highest accuracy only?
Are there other factors to check with the accuracy like Cohen kappa (I have a few models that generate similar accuracy)?
To predict the output of external samples (not included in the training or test set), should I train the whole dataset (train+test) to generate the final model and use it, or I have to use the model from the last training set of the cross validation?
Usually it is a good choice to take the model with the best accuracy, but depending on the classification task it might make sense to also take other values into account, e.g. the values of the confusion matrix (number of true positives, …) or Cohen’s kappa. The Scorer node can be used to get all these informations.
The whole dataset should be used for the final training.
When I use the wole dataset for training to get the final model, do you think this model will not overfit? Won’t this model lose the “immunity” to overfit?
Was the task of the cross validation that I did before to evaluate the performonce of the classification algorithms to get the highest accuracy of prediction without overfitting?
Can I consider the accuracy from the cross validation as Q^2 and the accuracy of the training of the whole dataset as R^2?
The goal of cross validation is finding the best parameters for your model. Using them for the whole dataset gives you in most cases a better model, since more training data is used, and results in similiar overfitting as during the cross validation, because the structure of the data stays similar, i.e. if you do not have overfitting during the cross calidation, there won’t be overfitting if learning on all the data usually.
Hi Simon,
For the Q^2, it is the following
This is the cross-validated version of R2 and can be interpreted as the ratio of variance that can be predicted independently by the PCA model. Poor (low) Q2 indicates that the PCA model only describes noise and that the model is unrelated to the true data structure. The definition of Q2 is: Q2=1−∑ki∑nj(x−^x)2∑ki∑njx2 for the matrix x which has n rows and k columns. For a given number of PC’s x is estimated as ^x=TP′ (T are scores and P are loadings). Although this defines the leave-one-out cross-validation this is not what is performed if fold is less than the number of rows and/or columns. In ‘impute’ type CV, diagonal rows of elements in the matrix are deleted and the re-estimated. In ‘krzanowski’ type CV, rows are sequentially left out to build fold PCA models which give the loadings. Then, columns are sequentially left out to build fold models for scores. By combining scores and loadings from different models, we can estimate completely left out values. The two types may seem similar but can give very different results, krzanowski typically yields more stable and reliable result for estimating data structure whereas impute is better for evaluating missing value imputation performance. Note that since Krzanowski CV operates on a reduced matrix, it is not possible estimate Q2 for all components and the result vector may therefore be shorter than nPcs(object).
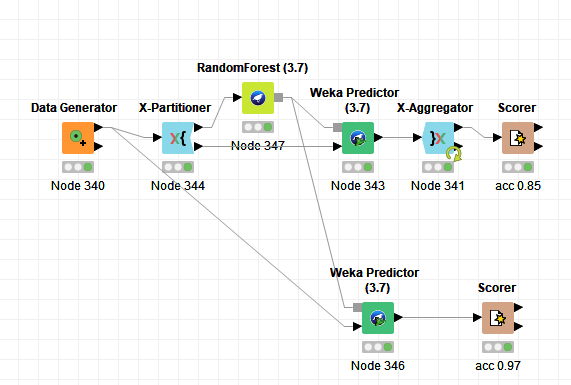
I would like to show you a model of using the whole data set for the external data prediction,could you please confirm it is correct or wrong?
Is it normal to have the acc on the whole data 0.97 while the cross validated model gives acc = 0.85?
Can we say according to the definition of the Q^2 above that Q^2= 0.85 and R^2= 0.97?
No I don’t think that is the correct interpration.
It makes sense that the accuracy is higher for the whole dataset, because you do a prediction on the dataset which has been used for training.
So the correct accuracy ist the 0.85, but what you should do now before you use the model for prediction on completely new data is to learn the model with same parameters again on the whole dataset.
Hi sSimon,
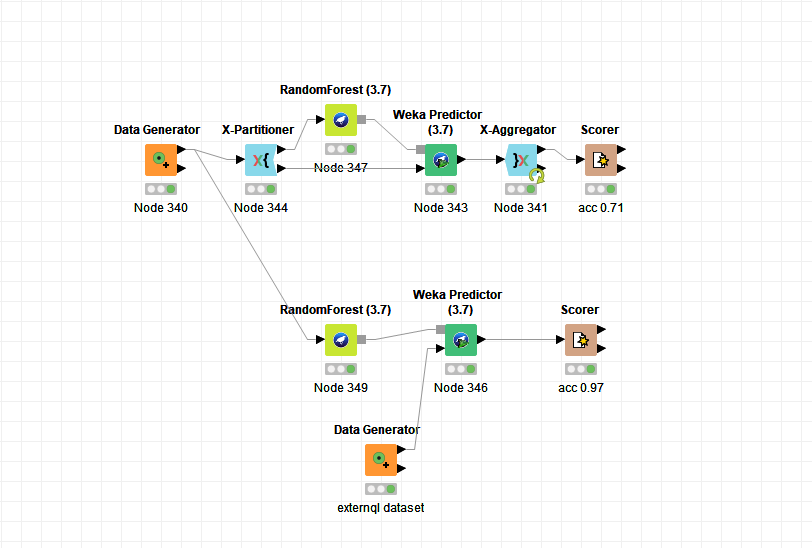
Isn’t that what I did in the picture just above? I linked the output of the training to a new predictor and I used the whole dataset. I expect that the second predictor will run after all the iterations of the cross validation are done. Please correct me if I am wrong?
No, I mean that the learning, not the prediction, should be done using the whole dataset. Because then you usually get an even better model, since more data has been used for training. This model can then be used for the external samples you mentioned in your first post.
The purpose of cross validation is not building the model, but finding the best parameters. And with theses parameters the final model then can be learned using the whole dataset.
Hi Simon,
I modified my workflow. But I still feel thqt there is something wrong in it becquse there is no link to transfer the best parameters between the 2 learners. Is there anything to use to link them 5for example flow variables).
parameters in this case means for example the number of trees you use in your Random Forest learner node. You can of course use flowvariables to set those parameters, but setting them by hand is way less complicated and appropriate in this case.
From a pragmatic point of view, you often times don’t need CV with Random Forests because they deliver something similar out-of-the-box: Out-of-bag predictions.
Each tree in an RF is build using a bootstrap sample of the data and the out-of-bag predictions are obtained from the rows that were not used to train a particular tree. Combining all out-of-bag predictions gives us an estimate of the generalization performance of our model. Note that this performance is in many cases worse than the actual performance of the whole forest because for each row only a subset of the trees are used.
In order to use out-of-bag predictions you would have to switch to the native KNIME Random Forest Learner and Predictor.
Please note also that Random Forests are among the robustest models when it comes to overfitting which is one of the reasons they are so popular.
Hi Nemad,
I am quite confused to consider the number of trees as a parameter for the model. I thought it is a hyperparameter that control the performance of the algorithm itself but the parameters that Simon is montioning are the ones that link the features to the response.
For instance, in neural network, the hyperparameters are the setings that define the topology of the NN such as the number of layers or neurons or learning rate. In the other side, the parameters of learning that are specific to the data itself are the weights and the biases. They are optimised and fitted during the training to get the fitted model.
In the cqse above, I am not trying to tune the hyperparameters of the RF 'numer of trees and features) but I am trying to extract the model’s parameters that are obtained after the training with cross validation and then use them for a final training and predition for the full dataset.
Please correct me if I am wrong.
Thanks,
Zied
ok then we have been talking past each other for most of the time.
I am pretty sure that Simon was talking about the hyperparameters, so sorry for this misuse of nomenclature on our side.
Concerning your question, I am not aware that it is common to extract the parameters of your cross validation models. I use cross validation to make sure that I am not overfitting my hyperparameters on my test set.
By that I mean that if I change my hyperparameters in order to increase the performance on a holdout test set, then I am tuning my model to work better on this specific test set which might cause worse performance on other unseen data. Cross validation alleviates this problem to a large degree.
Note that you will train n models in an n-fold cross validation and it is usually not easily possible to combine these into a single model (that is not an ensemble). Since a RF is itself an ensemble, one could argue to simply combine all the trees of all models into one big model but that might cause an unreasonable large model.
To summarize the steps I would do if I was in your shoes:
Split your data into a training and testing set
Put the testing set into a vault and throw away the key (you are not allowed to touch it until you want to deploy your model)
Select some initial hyperparameters (this includes the kind of model you want to train e.g. RF, SVM, etc.)
Use cross validation to tune your hyperparameter and get an idea of the model’s generalization ability
Once you are satisfied with the cross validation results (e.g. in terms of accuracy) retrain your model on the whole dataset (in case of data a general rule of thumb is “the more the better” (if it is well behaved, e.g. relatively balanced))
Search for the vault key and evaluate your final model on the test set
Deploy your model if you are satisfied with the performance on the test set, otherwise start at step 1 (or step 2 but each time you change your model because of the evaluation on the test set, it becomes more likely that you overfit on it).
That’s a bit lengthy and there are certainly other paradigms out there but that’s how I would do it.
(Well actually not because RFs don’t need cross validation but see my post above for that).
 but see my post above for that).
but see my post above for that).