I have to be a bit harsh. I hope you don’t take it personal. it’s meant to be educational. But just because KNIME makes it easy to play with ML/AI doesn’t mean it’s easy to do it right. I speak from experience BTW.
Your example workflow has a major flaw. Of course you get good metrics if you use the exact same data you trained the model with. This will always be much better than on your test data. That is exactly why we split into train/test and only ever evaluate on test.
In regards to the image in your first post, instead of taking one model out of cross-validation loop to apply the test set, make a model with all the data from the training set after cross-validation. Ask yourself why are you doing Cross-validation exactly?
And I can’t let the next point slide as well. Chaining 5 dense layers with tabular data also looks like you don’t really know what you are doing and just using deep learning because it’s all the rage.
My recommendation is to first read up on the basics of ML and about what Cross-Validation is, for what to use it and why to use it and then also about splitting training and test set and why you should do that. Covering that is simply not part of a reply on a forum as books have been written about these topics.
Hint: Feature selection also must only be done on the training set and hence inside a cross-validation loop (the knime examples in that regard are rather poor and way to simplistic) and the normalize must come before low variance filter!!!
Then you should play with classical ML like Random Forest and only after you get comfortable with it (months at least) would I even try to look into DNNs. For such tabular data random forest or xgboost are better than Neural networks and orders of magnitude faster.
Still simplified a more sensible workflow (just 1 train/test split, don’t do it like this you need CV for parameter optimization and so forth) would look like this:
M14.1_RF.knwf (1.7 MB)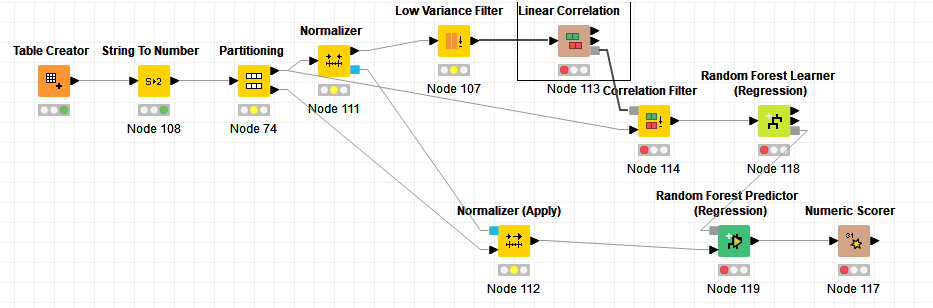
Still this gives basically random results. I also wonder what all the Integer columns are. Looks like categorical data. In that case they must be handled accordingly and the ML algorithm chosen accordingly (not tree-based).