does anyone know why the RowID-Node produces a string with the rownumber and the word “row” as prefix?
I mean, if we would only have an ID as number, then it would be much more efficient, because they are only bytes or integers. Furthermore it is easier to work with numbers if you want to do something with recordID.
Hi @Robinvm , I can’t tell you why it has the “Row” prefix, and it has always struck me as an unnecessary additional sequence of characters too.
RowID, though is not intended to be numeric, but simply represent a unique sequence of characters. Even so, it could equally have been just R0, R1, R2 and so on I guess, making it a little more compact.
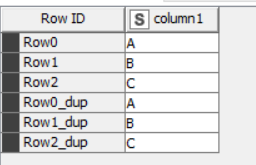
Taking your example table with just column1 present, and concatenating it to itself, it soon becomes apparent that RowId is not intended to represent a numeric value…
But again, it doesn’t really need the apparently wasteful “_dup” to tell us it is duplicated. Any additional suffix (such as “d”) would have sufficed
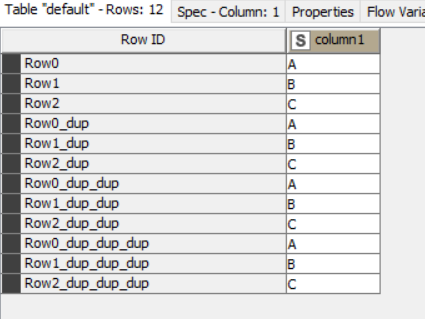
If we perform the concatenation again it becomes ever longer
In spite of relatively recent changes to Sorter which allow it to attempt to sort Row ID “numerically”, I don’t tend to rely on that because of the above kind of concatenations that occur, making any kind of sequence nonsensical. For any kind of record sequencing my preference would be to use the Counter Generation node or even Math Formula node, and leave RowId as an internal identifier that I can (mostly ) ignore; occasionally resetting it with the RowId node if it has become particularly horrific!