Hello! I can’t get my SVM learner and SVM Predictor to make accurate predictions. In most cases I get accuracy 1.00 which shouldn’t be possible for this dataset. Can someone please take a look at my workflow and explain what I’m doing wrong?
This is a school assignment and I probably will move forward with KNN instead, but I really want to know why SVM doesn’t work for me.
@mininoll you might want to check how you prepare your data for the SVM and also the initial results where you might habe to find a cutoff point that is suitable. Maybe use the Binary Classification Inspector – KNIME Community Hub
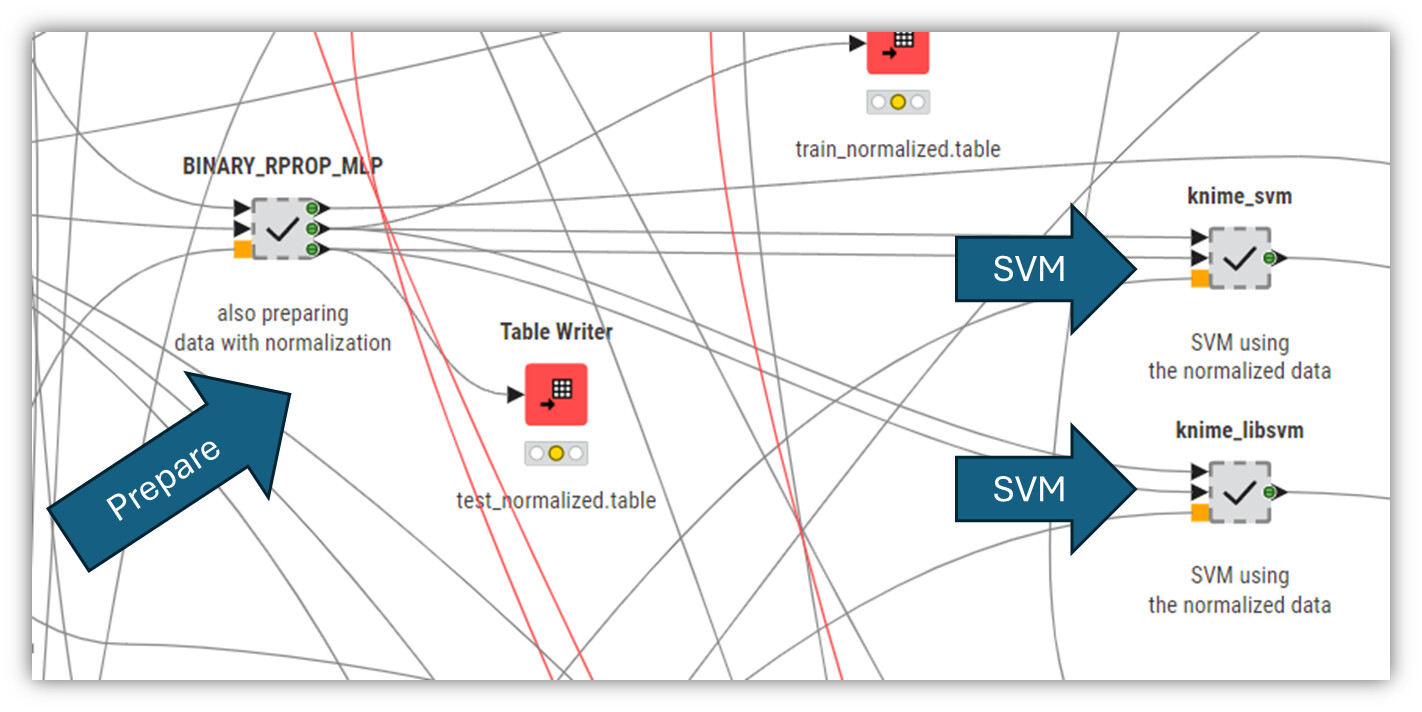
I have a workflow where I prepare data for a SVM and other models. And then use the data. You can try to adapt that to your needs (just provide data where your target/label variable is a string called “Target“ with 0/1):
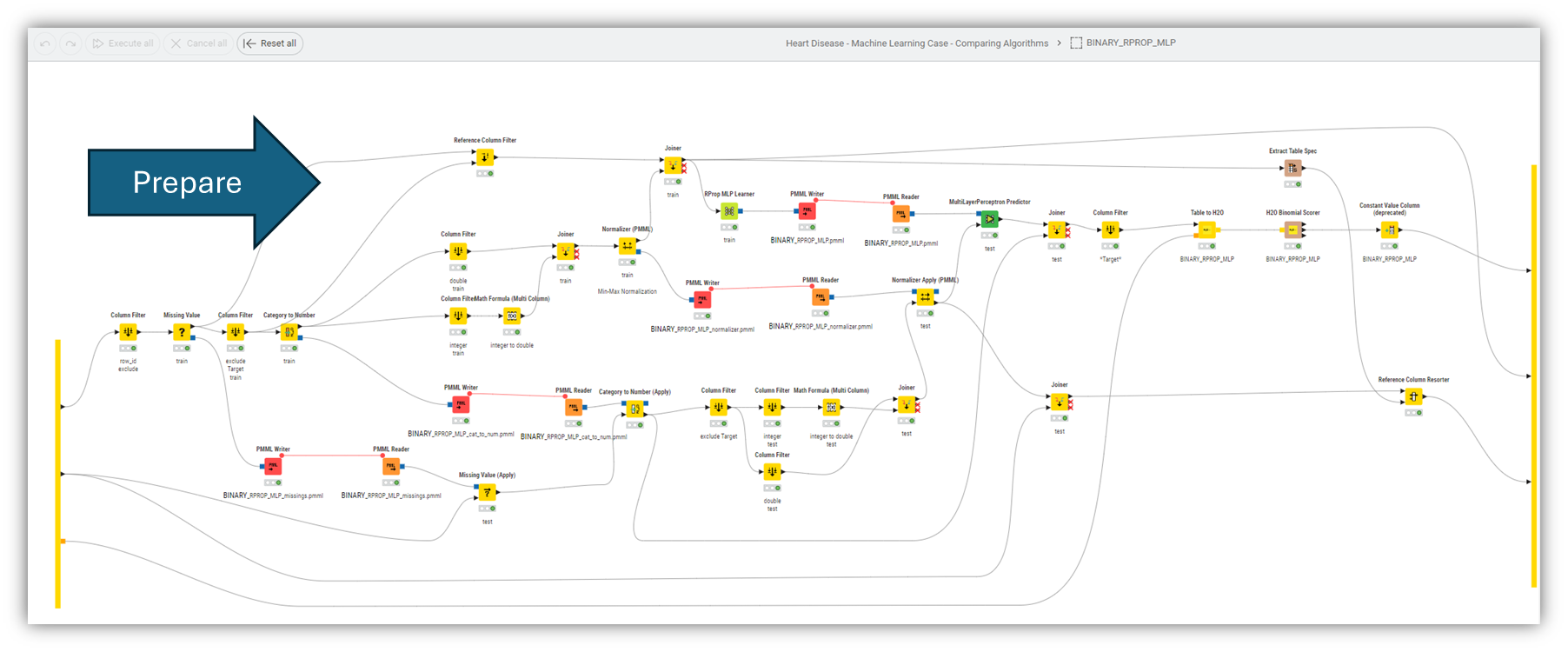
The data preparation inside does look like this:
2 Likes
Thanks for your reply. I’m not sure how your data preparation works, nor how I would use it on my own dataset. I was more curious about why my solution doesn’t work, and what I simply need to do instead.
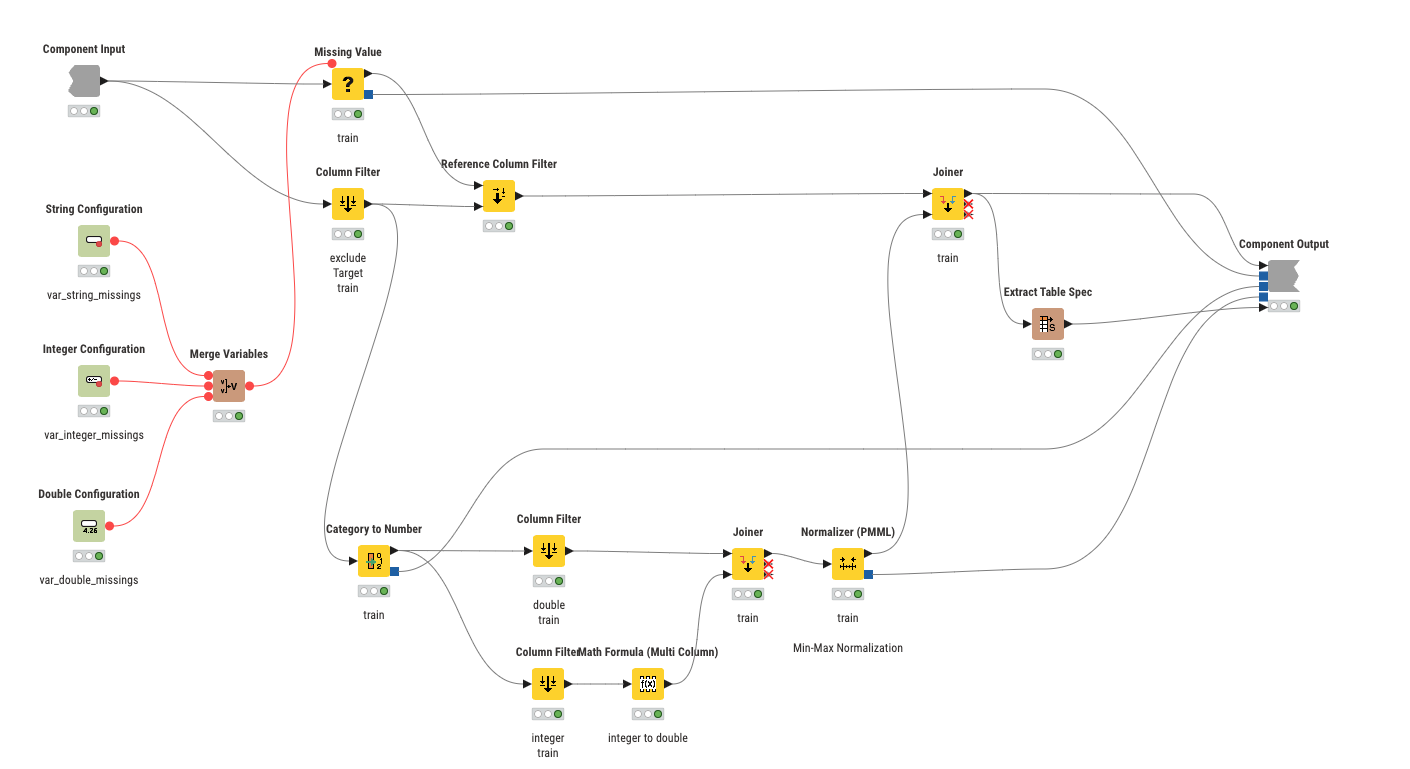
@mininoll I have compressed it into a smaller workflow. The data preparation inside the Component on the training data looks like this. Replacing missing values, categories to numbers and then normalizing the numeric data. You can store the rules in PMML files and then apply them on the training data and also new (unseen) data.
Maybe you compare this to your approach. You can re-use my several ML examples by providing the data and the label as a string variable called “Target“ with the values 0/1. Regression the same but “Target“ is a double.
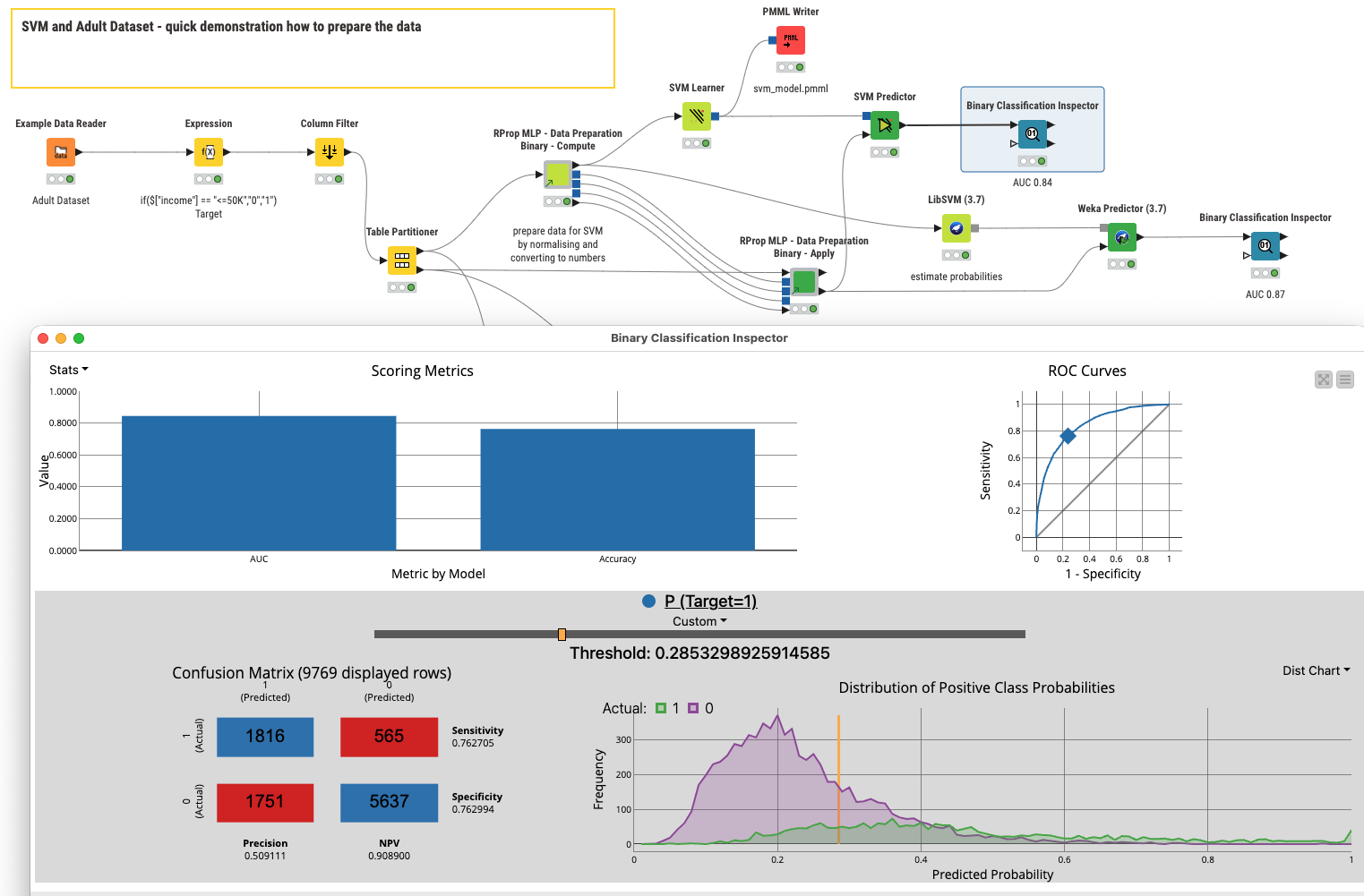
This is the result on the census income (AKA adult) dataset. There is some differentiation but the result is far from perfect (AUC 0.84).
The results with this model can even be improved when you use a more sophisticated data preparation method (vtreat).
2 Likes