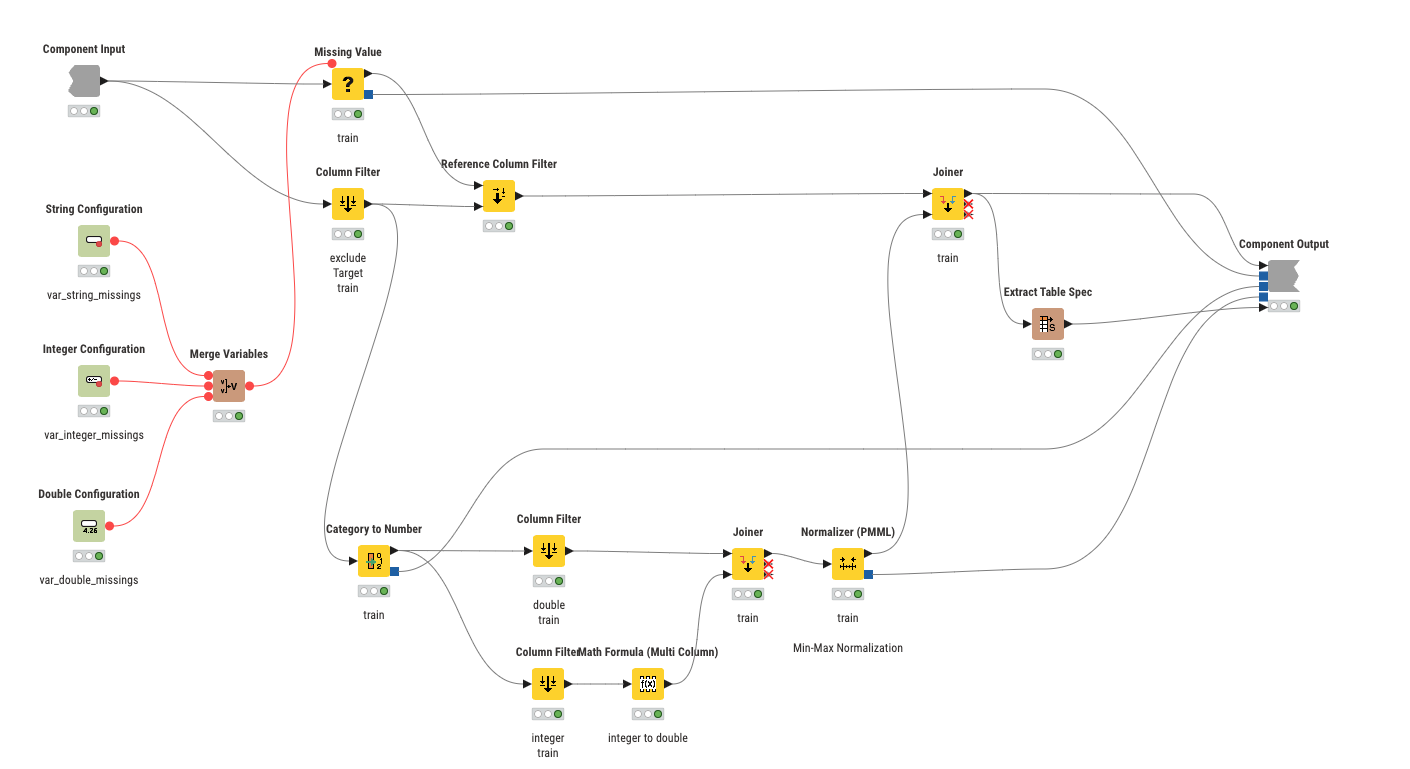
@mininoll I have compressed it into a smaller workflow. The data preparation inside the Component on the training data looks like this. Replacing missing values, categories to numbers and then normalizing the numeric data. You can store the rules in PMML files and then apply them on the training data and also new (unseen) data.
Maybe you compare this to your approach. You can re-use my several ML examples by providing the data and the label as a string variable called “Target“ with the values 0/1. Regression the same but “Target“ is a double.
This is the result on the census income (AKA adult) dataset. There is some differentiation but the result is far from perfect (AUC 0.84).
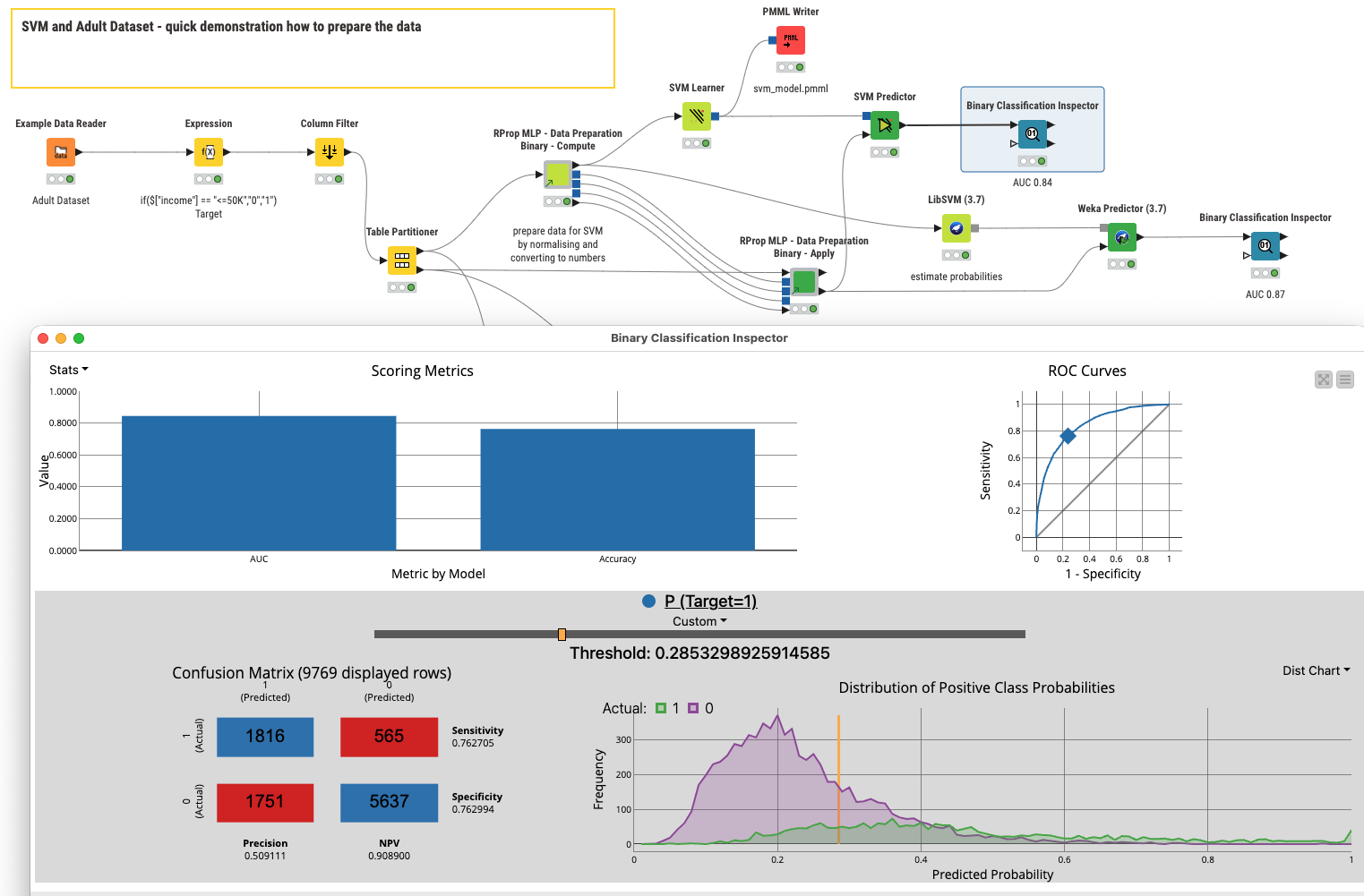
The results with this model can even be improved when you use a more sophisticated data preparation method (vtreat).