Hello
Is there a way to use a widget to reference a folder and upload all the files in that folder? I’m using File Upload Widget but it generates an image in the temp stream of the selected file (single file), but I can’t use it to upload multiple files.
Thanks
Hi @lsandinop,
this isn’t possible yet. Checkout Upload multiple files for more details.
I’ve added you as a requester for this feature.
Kind regards
Marvin
2 Likes
Hi @Isandinop,
I had a comparable “obstacle” in one of my workflows in KNIME AP (not KNIME server). The difference to your question was my need that the user selects a set of files (image files) and not all files within the given folder.
I circumvent it by
- reading all files names within a defined folder (using the ListFiles/Folder node)
- adding information to that table needed by the user to “know” what the file names represent
- using this output in a Table View node (in my case it was a Table Editor node)
- use the selected files for any further operation.
This part of the workflow is “encapsulated” in a component to allow user interaction.
So, in my case, I needed several photos for a BIRT report . As additional info in the table I created links to the files, so that the user can see the photo before he makes his choices.
To solve your problem loading all files (I just assume, these are images) you can skip the Table View node and read all files in one table using a loop.
Perhaps this approach helps
Best regards,
Jürgen
2 Likes
Hello, dear @marvin_kickuth,
I currently have a situation, most likely easy to solve. The lack of knowledge is mine, and mine alone (sorry for that)…
My problem is while reading several .DBF files in a loop. I have downloaded 40 consecutive monthly files (corresponding to my research interval). Each of these files has about 1 to 3 million lines (each line for one register).
I tried some tips and minor changes on the workflows suggested on the Hub.Knime and the Forum.Knime, such as Read files in a loop – KNIME Community Hub ; or Reading multiple files using loops – KNIME Community Hub
I’m stuck on this question: I haven’t found exactly how to configure the loops on the nodes “File Reader” and “Loop End”, along the loop. See how this part of my workflow looks like:
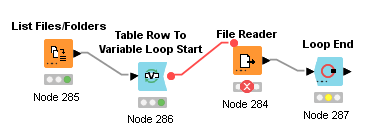
1-The Output of “List Files/Folder” node presented a list with the 40 original files (using the “Filter Option” to .DBF), in their original folder location (as I expected);
2-The output of “Table row to Variable Loop Start” node (the Variable Connection) presented the path to the first file on the list (the output of the former node), with 40 iterations (as I expected, too);
3- But I got the “Error Message”: “The data row has too few elements” → the node execution did not get to read any row, except the
In case you might want to test with these specific data, here are 4 links (from my Google Drive) of 4 sequential of these monthly files, in the format .DBC (which is much smaller than DBF, and easier to handle, easily convertible to DBF files by many converters):
a) Covid data from Dec-2021:
b) Covid data from Jan-2022: PARS2201.dbc - Google Drive
c) Covid data from Feb-2022: PARS2201.dbc - Google Drive
d) Covid data from Mar-2022: PARS2203.dbc - Google Drive
The same original files are available at Transferência de Arquivos – DATASUS , but under the options:
“Fonte” (or Source): “SIASUS - Sistema de Informações Ambulatoriais” → “Modalidade” (or Mode): “Dados” (or Data) → “Tipo de arquivo” (or type of file): “PA - Produção Ambulatorial” → And selecting the months of interest
Would you mind helping me to understand where and what did I do wrong in the configuration of the node “File Reader”?
Thanks in advance.
ATB,
Rogério.
@rogerius1st it might be best to use a separate thread. The File reader will most likely not be able to import this special format.
You will have to try something like this R package which is under development
Then you will have to use the R package foreign in order to import the decompressed dbf files.
I will see if I can build a workflow
1 Like
@rogerius1st I built an example how to import such files - DBC (compressed DBF) from DATASUS (Department of Informatics of Brazilian Health System):
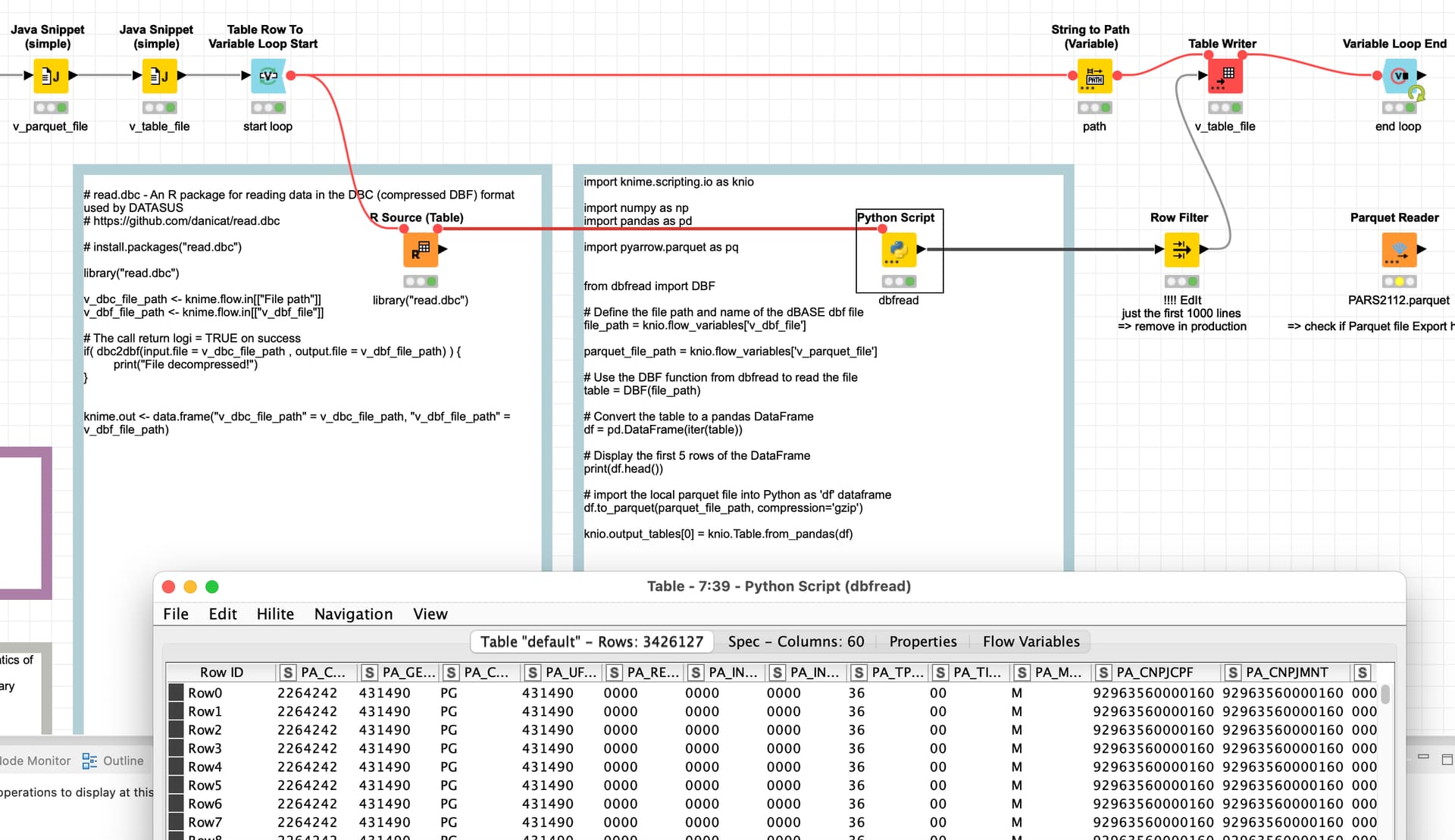
Due to the size of the data in the sample on the Hub there are only 3 result files with the first 1.000 Rows. But it did work for your larger DBC files you provided:
Please also consult the external resources.
2 Likes
Dear Markus,
Thanks for your prompt answer (and for the delay on mine). Indeed, you’ve already helped me once (and quite a lot), several months ago, with another project, in my Master’s thesis (thank you once again for that…).
As I’m not an IT professional (nor a student), I’ve never used R or Python before, in any specific project. I’m not skilled in any of these languages or in their libraries. This is why I chose Knime, for its usability for non-programmers using only its graphic interface for building low-code (or no-code) solutions. Although I tried, I confess to you that I could not understand your nodes involving R and Python.
Therefore, I ask you if it is possible (or not) – and under which configuration in the “File Reader” node – to read all my 40 DBF files (formerly downloaded and decompressed from DBC format) using Knime loops such as the one I wrote above (“List Files/Folders” → “Table Row to Variable Loop Start” → “File Reader” → “Loop End”). I saw some closely similar solutions (for reading several files in a simple loop) in a few other examples in the Knime.Hub, but unfortunately none of them worked out on my case.
I tried to change some options in the “File Reader” node, such as clicking on the “support short data rows” check box, which gave me 2 rows (instead of no rows, as under the default option), but their content was not acceptable either, for they had only the titles of some of the previous column headers. I also tried different options for “Encoding”, but those minor changes hadn’t brought me any better solutions.
Sorry for insisting on a more straightforward (or shorter, or simpler) solution, without using program languages, but… would you might suggest me such a set of configurations for the “File Reader” node?
ATB. Rogério.
1 Like
@rogerius1st glad you liked my previous examples.
Unfortunately there is no simple setting to read this DBC format. This is why people have created these libraries.
My example can read your data and did with three of your sample files. The results are in the /data/ subfolder (the first 1000 lines) for you to check
To set up Python and R/Rstudio I have written two articles to help you do that. It is not that hard and you would not need any coding yourself but can just use the example and place your files in the source folder. The list files node will read them and give the results:
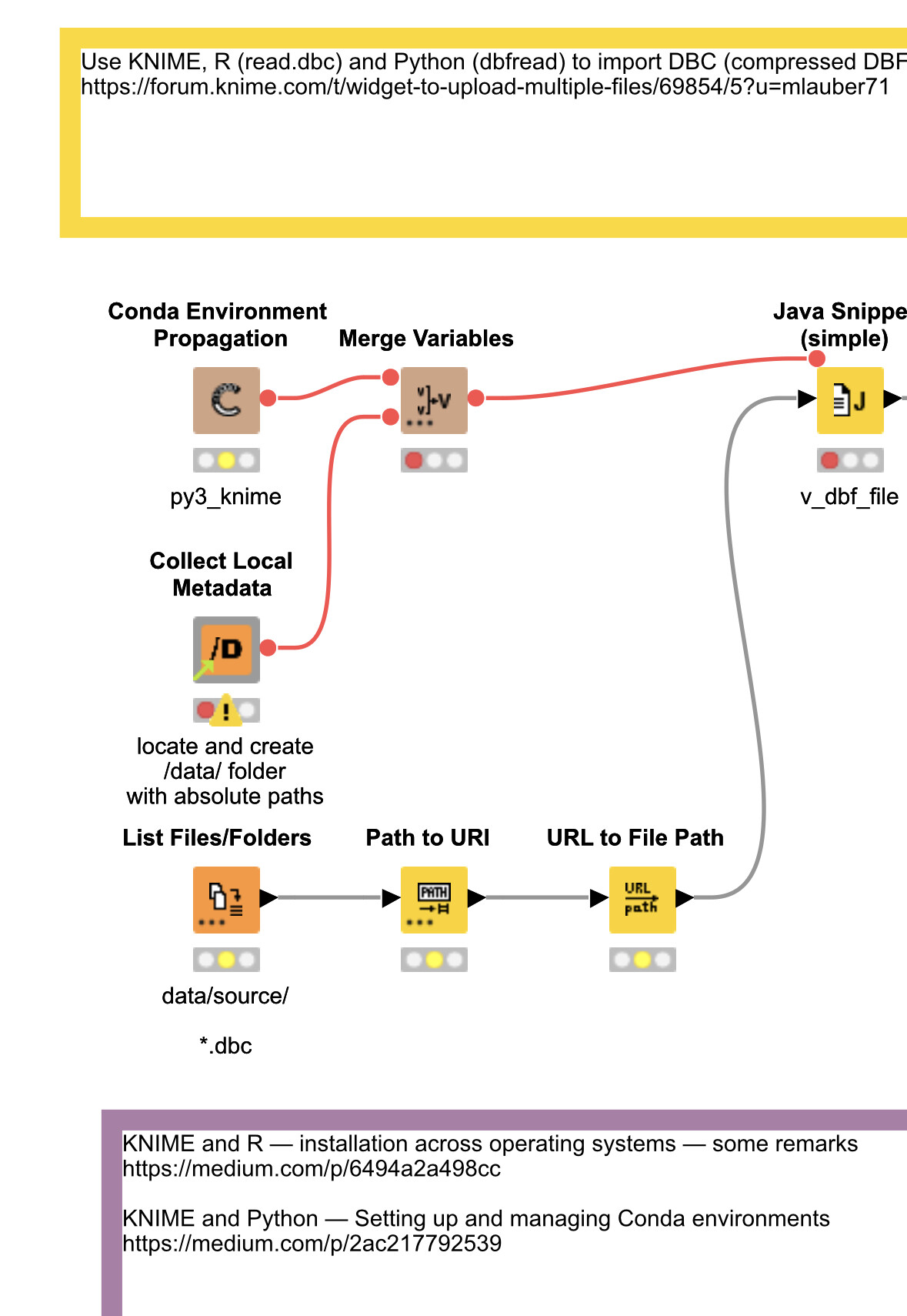
Then you would have to remove the 1000 line limit.
My sincere recommendation would be to try and get some basic knowledge about R and Python which would open a whole new world ![]() . The Python/yaml file is in the sub folder also.
. The Python/yaml file is in the sub folder also.
Although sKNIME and LLM models are incoming - right now it is easy to let something like ChatGPT write code so you could also do it yourself - but there is always the KNIME community to help.
Another option would be if someone could process the data for you and provide them. That might depend on how large the datasets are - can you upload them to a Google drive?
2 Likes
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.
Internal ticket ID: UIEXT-2349
Summary: Multiple file upload widget
Fix version(s): 5.4.0
Other related topic(s):
Internal ticket ID: UIEXT-81
Summary: File Upload Widget should support upload of multiple files
Fix version(s): 5.4.0
Other related topic(s):