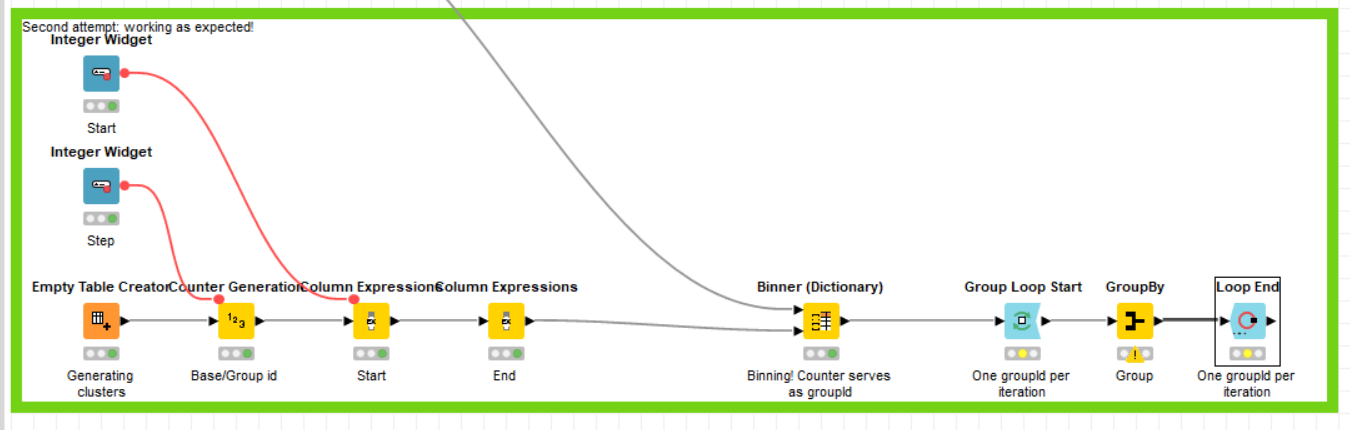
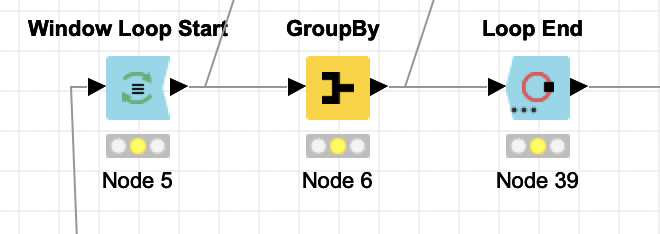
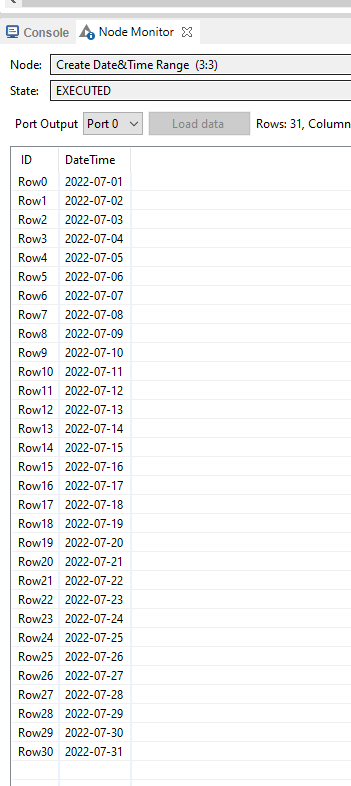
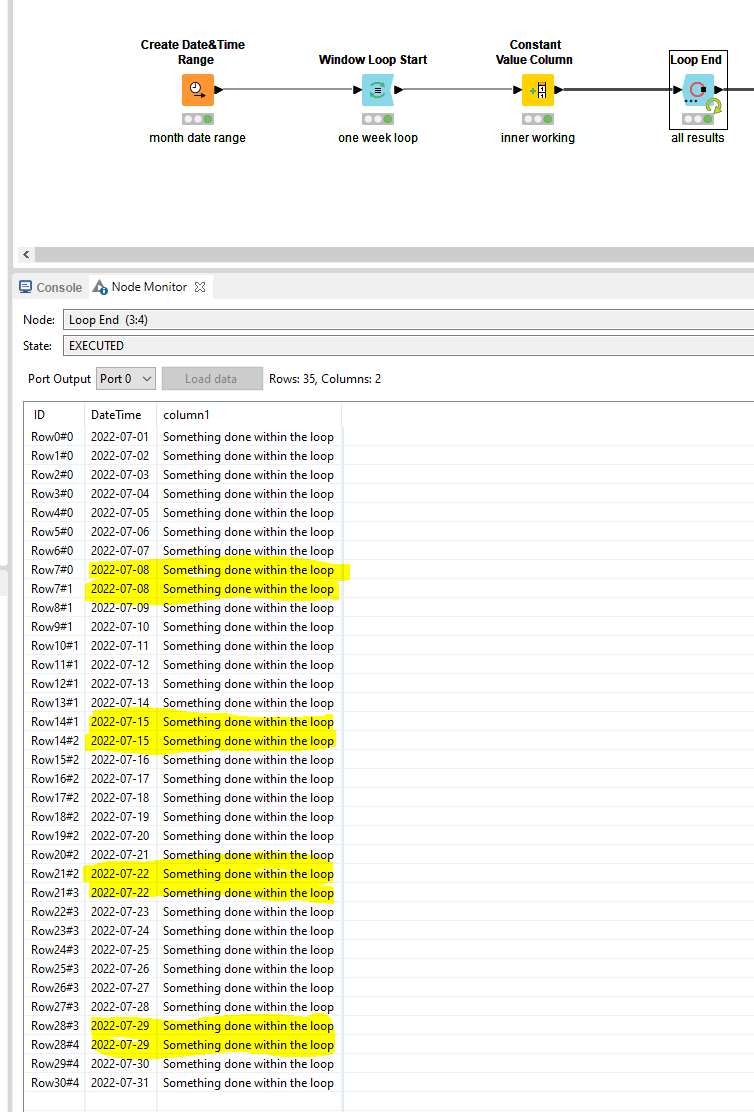
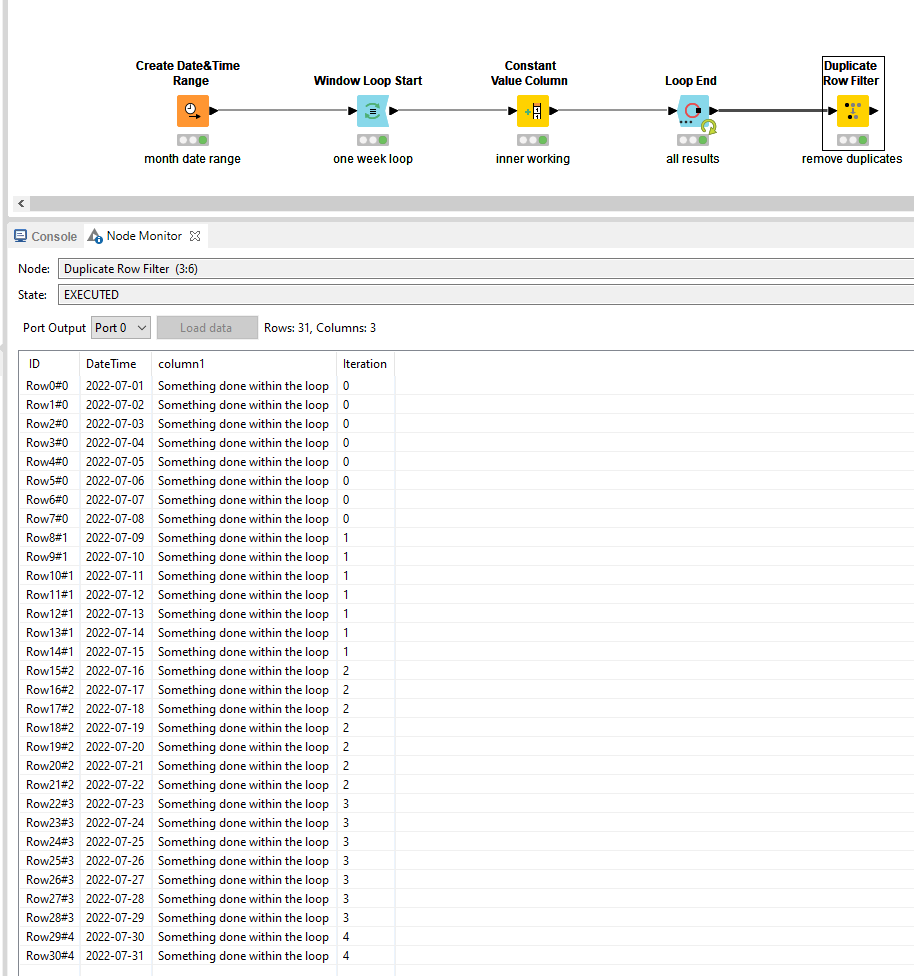
I’m trying to cluster my data in 5 year chunks. While debugging through the Window-Loop-Start – GroupBy – Loop End workflow, I realised that some dates are accounted double. Which means they appear in two iterations.
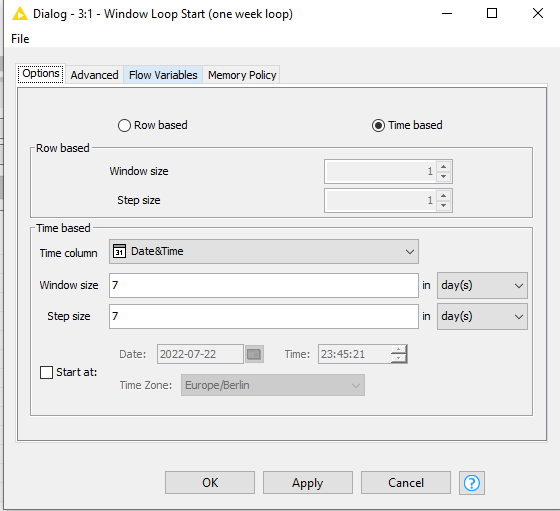
My configuration of the node is:
Time column: Product Launch Date (Table is sorted according this column)
Window size: 5 years
Step size: 5 years
Start at: 1982-01-01
So the resulting date windows of the window loop node are:
Iteration 3 : 1997-01-01 up to and including (!) 2002-01-01.
Iteration 4 : 2002-01-01 up to and including (!) 2007-01-01
My expectations would be:
Iteration 3: 1997-01-01 up to and including 2001-12-31
iteration 4: 2002-01-01 up to and including 2006-12-31
How do I need to reconfigure this node to achieve this?
Do I need to chose a different node and if yes which one and how is the proper configuration?
Deleting data is not an option as it would falsify the result.
I resolved it by moving the data from e.g. 2002-01-01 to 2002-01-02, as it doesn’t matter this time for the evaluation. But it needs two nodes (rule node to modify the date and then another node to convert the resulting string back into a date) which makes the resulting scheme convoluted. And most annoyingly a lot of manual typing in the rule node (for each year, I need to enter the rule on a separate line).
I now think that this is a bug in the window loop node.
If the data is exactly the same in both iterations, why not add a duplicate row filter afterwards as a workaround? (excluding the iteration number if you opted for that)
@lelloba - It took me a while to understand, but it looks to me like you rebuilt the window loop node. Brilliant work around which does not involve a lot of typing (just the generation of the binning table with the start/end years.
I still have to transfer your solution to my workflow and give it a try.
I still think though that this is a bug and should get fixed by the KNIME team.
Within the loop, some sort of transaction takes place. I see a GroupBy in your case which I, for this illustration purpose, replaced with a constant. As some rows are being used twice as input, those overlapping dates will also have exactly the same output at the end of the loop, like you described. Which is also the case here making the number of rows increase to 35.
Whenever I replace a Duplicate Row filter after the End Loop, these are filtered out and the final result is again the 31 rows that I put in the loop including the processing that has been performed within the loop.
If you include the iteration number in the End Loop node, you could consider this as your “cleaned-up time period” for which you can also apply the GroupBy subsequently based on this. In my case, consider it as a week number.
Now whether this is a bug is for someone from the KNIME Team, it sure is pretty inconvenient, but to me it looks like this can be “solved” with just adding one or two additional nodes. But maybe I’m completely misunderstanding your problem description after all.
@lelloba - if you know how to tag someone from Knime - thanks for doing that and giving this more attention.
@ArjenEX - my input per iteration is 500 rows and my output only 5 rows per iteration (“Group By”), so no chance do apply a filter after the loop in my case.
In my opinion, to achieve what the linked thread is describing, the window loop start node would need to be configured as (with the row setting, not the date/time setting):