Hi,
I’ve been getting 403 errors when scraping certain websites using the HTTP Retriever. Any known workarounds for these?
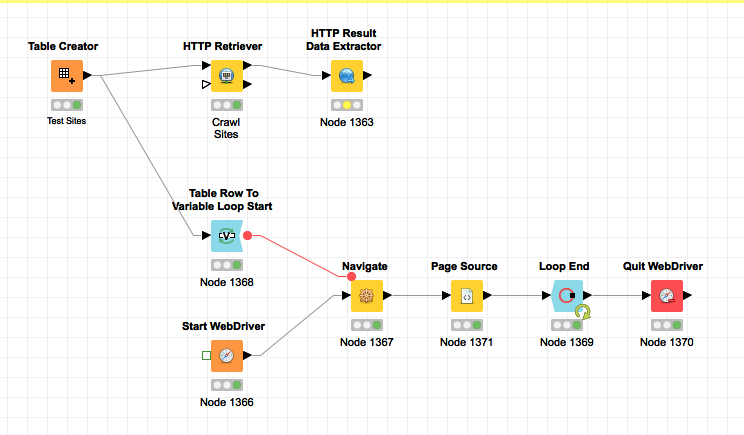
I’m attaching a sample workflow that shows a few sample pages that give me a 403 error.
403 sites.knwf (7.7 KB)
Hi,
I’ve been getting 403 errors when scraping certain websites using the HTTP Retriever. Any known workarounds for these?
I’m attaching a sample workflow that shows a few sample pages that give me a 403 error.
403 sites.knwf (7.7 KB)
Hi stevelp,
Unfortunately, these sites use some measures to prevent automated crawling (the last URL uses mechanisms from Cloudflare, the other do not state). It’s a little ridiculous, as these measures are obviously not triggered by high-volume requests, but simply how your user agent behaves. E.g. it wouldn’t be possible to open those pages with browsers such a lynx either.
You could play with different user agent strings. E.g. try the following:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko
This helps in some cases but definitely not all, and at the end it’ll be a trial and error.
If you’re willing to give the Selenium Nodes a try, I was able to retrieve all three test URLs using them. Keep in mind, that those site use some aggressive blocking, so eventually you will likely run into limits as well!
Updated example workflow:
Thanks Phillipp, I’m trying both of the suggestions!
The first method I attempted was to use different user agents. It seems some sites like one agent over another, but no agent is better in all cases. I was able to reduce the number of 403 responses by running two HTTP Retrievers in a chain (using the Chrome user agent first, and for those that had an error, I tried using the Google Bot agent).
I am also trying the Selenium nodes, and I’ve gotten them to mostly work. I’m attaching my workflow - 403 sites using Selenium.knwf (36.8 KB)
I have a few questions:
On the same topic of speed, is it possible to open multiple browser tabs at once and run them in parallel using the Selenium nodes?
Hi Stevelp,
You could probably optimize this further by having a list of User Agent strings and then using loop nodes and some flow variables, where you keep trying until you receive a non-403 response (this will probably increase the complexity of your workflow considerably, not sure if it’s worth it).
First: In general, the Selenium Nodes will always be a ~ magnitude slower than doing a simple HTTP GET, e.g. with the HTTP Retriever. The latter will simply request a file, while the Selenium Nodes act exactly like a browser (this means: downloading all referenced images, scripts, parsing a DOM, rendering it visually, etc.)
However, there are several measures for speeding up things:
Start the browser outside the loop – i.e. move the Start WebDriver before the loop start (as far as I see, you’ve already done this).
Once you’re finished with the “design phase” of your workflow, switch to a headless browser. Last time I tested, this was faster than a UI browser, even though your personal mileage may vary.
Disable image loading. There’s an existing “Snippet” in the configuration. Just select it and click the “Merge” button:
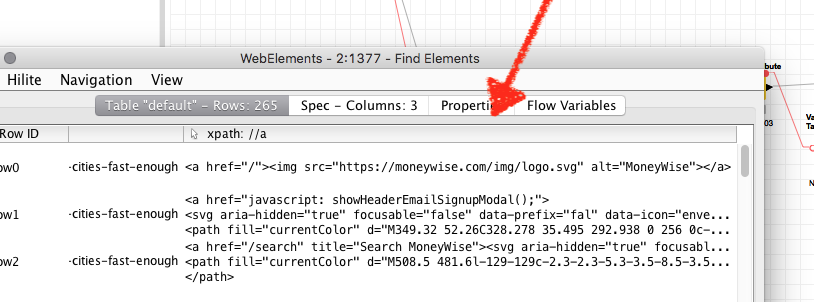
Regarding your specific workflow: You’re currently extracting all <a> elements from the pages by first running a Find Elements node and then the Extract Attribute. As webpages usually contain many, many links, there’s quite some overhead involved – e.g. the Selenium Nodes produce a user-friendly cell preview of all the extracted elements (the <a> in your case), and this takes some time.
There’s two things you can do
Go to the Preferences → Selenium and disable the option Save source snapshots in cells. With this settings, the source previews will no longer be created, which should speed up the workflow processing.
As a further optimization you can replace the Find Elements and Extract Attribute nodes with a single Execute JavaScript node. In the JS node you can perform the XPath query and extract the href attributes in one step, and then simply return a JSON array with the hrefs:
// find all <a> elements via XPath and return an iterator
const iterator = document.evaluate(
'//a', // XPath
document, // context
null, // namespace resolver (not needed here)
XPathResult.ORDERED_NODE_ITERATOR_TYPE, // result type
null // result reuse (not applicable here)
);
const hrefs = [];
// iterate the results and extract the `href`
let node;
while (node = iterator.iterateNext()) {
hrefs.push(node.href);
}
// create a JSON string for the result
// (you can parse this using KNIME’s JSON nodes)
return JSON.stringify(hrefs);
The workflow would look like this and should be considerably faster:
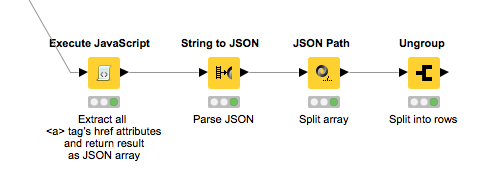
Find it on my NodePit Space: 403-sites-using-selenium-23919 — NodePit
Would you be able to share a reproducible workflow somehow? I’d like to investigate this. Otherwise, a detailed log output and/or any further details would also be very helpful.
Unfortunately there’s currently no real workaround. The Selenium API just does not give any HTTP status back. I have some ideas how to implement this in the backlog, but at the moment this is still an open todo.
I’ll have a look at this later!
– Philipp
Thanks @qqilihq for all the tips! This definitely helps speed things up a lot. I sent the log files and workflow to mail@seleniumnodes.com so you can take a look at some of the issues I was facing.
There’s one more question that I have regarding speed improvements. Is it possible to open multiple browser tabs at once and run them in parallel using the Selenium nodes?
Hey @stevelp,
Thanks for that, I’ll get back about these separately. This might take a bit – apologies in advance!
Not really, unfortunately. The Selenium/WebDriver API does not allow parallelization. Quite contrary: When building the Selenium KNIME Nodes we had to add quite some synchronization magic to prevent potential concurrency issues.
What might work for you:
You could try to parallelize your workflow using the Parallel Chunk Start and Parallel Chunk End nodes and make sure to use a separate browser instance in each chunk (use the Get Pooled WebDriver to start the browser in this case – it’ll keep a pool of active browsers and thus avoids launching a new one in each iteration).
What I once did for a client’s large crawling project: Split up the workload in advance and then run n KNIME command line instances in parallel where each controlled one browser.
Note, that both of these solutions will require plenty of memory – so I suggest to start with a medium number of parallel chunks, observe resources consumption, and then scale up if needed.
– Philipp
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.