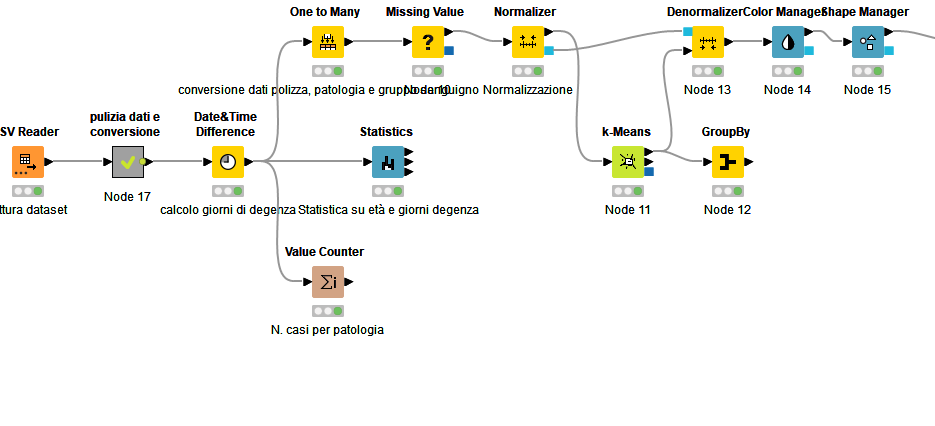
Buongiorno a tutti. sono alle prime armi con Knime e sto cercando di creare un workflow partendo da un dataset che riguarda i ricoveri ospedalieri (genere, patologia, gruppo sanguigno, dati di ricovero e dimissione) e con k-means vorrei individuare i cluster al fine di riportare graficamente alcuni risultati (es. relazione tra patologia con giorni di degenza o patologia rapportata all’età).
Qualcuno potrebbe aiutarmi?
Non so se riesco ad allegare il mio worflow per capire se sto procedendo bene…
Ciao, benvenuta nella community.
Dal workflow che condividi, non avendo idea di cosa contenga il dataset, l’approccio mi pare corretto.
Ho qualche dubbio sull’utilizzo del nodo One to Many, non avendo visto il dataset (probabilmente sarebbe più appropriato l’utilizzo di un nodo Category to number).
Valuta se tutte le features sono importanti tramite il nodo linear correlation o con il nodo Scatter Plot matrix.
Hai già in mente un numero di cluster in cui suddividere le osservazioni? Se la risposta è no, puoi provare ad utilizzare il nodo DB Scan che riesce a separare meglio e non ha bisogno di un numero di cluster iniziale. Se invece vuoi utilizzare k-means, ti consiglio di utilizzare il component Silhouette (lo trovi su hub.knime.com) che serve a capire qual è il numero di cluster ottimale. Contattami pure per ogni altra necessità.
Grazie mille. Ora proverò a migliorare il workflow anche perché non riesco ad interpretare i cluster.(il dataset riguarda i dati dei ricoveri ospedalieri con patologia, data di ricovero e dimissione, farmaco utilizzato, età e sesso polizza assicurativa, ospedalee medico curante)
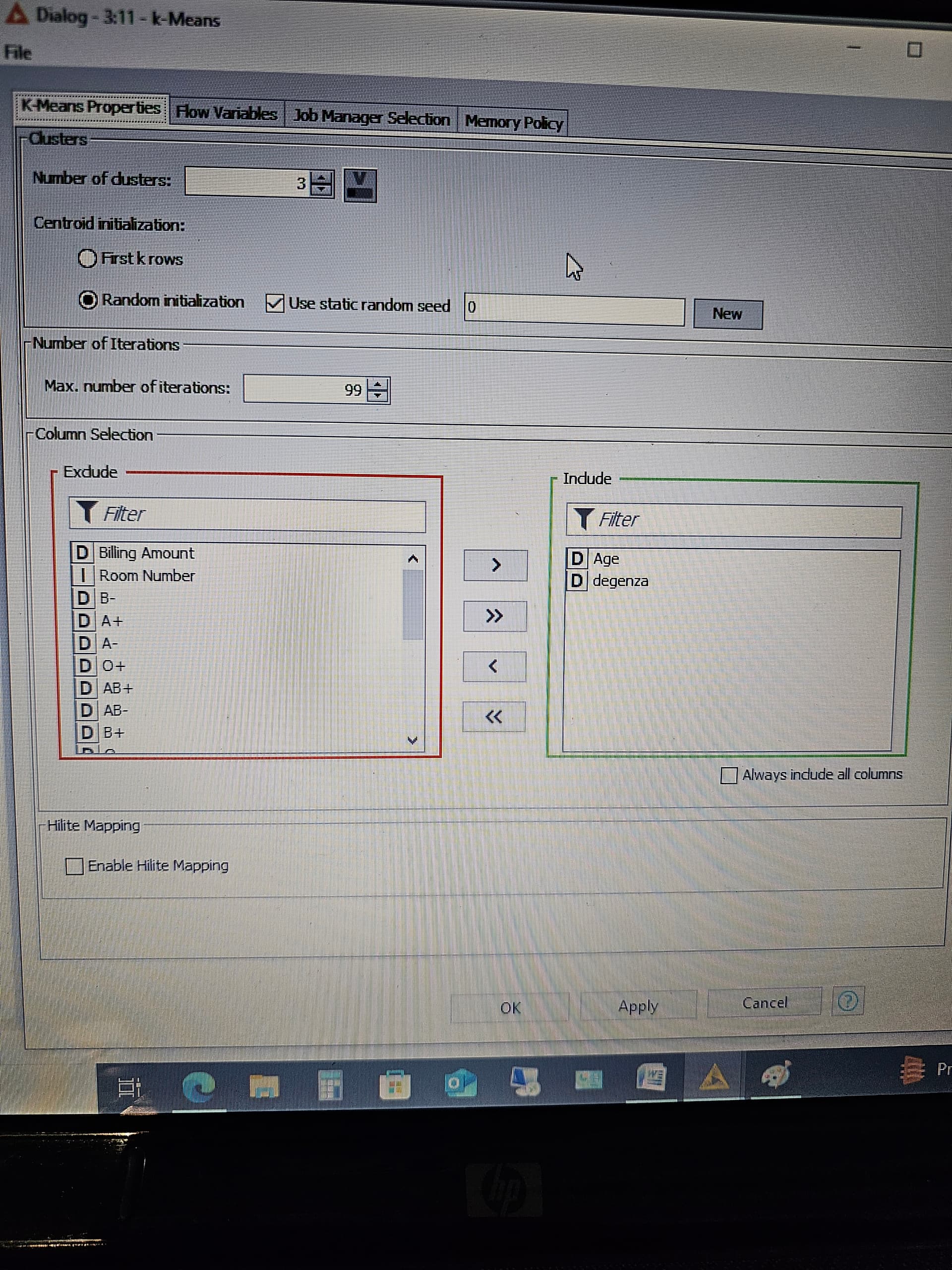
Eseguendo k means vedo che i miei cluster sono abbastanza equilibrati.
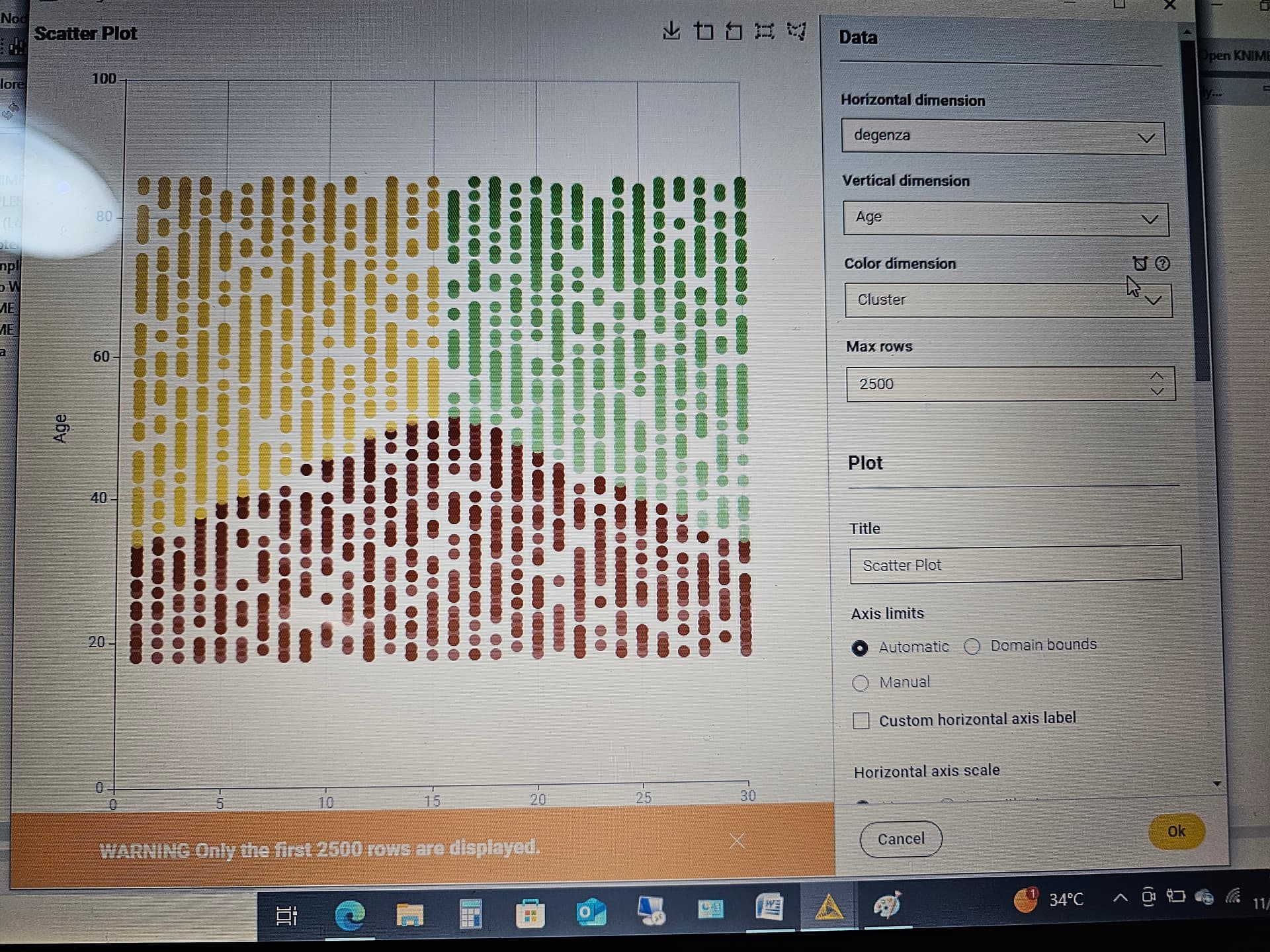
Però quando vado a rappresentare lo scatter plot e decido di rappresentare graficamente le caratteristiche durata della degenza ed età mi viene fuori il grafico sottostante e non capisco se è corretto/coerente con i cluster o meno.
Sì, mi pare coerente, anche perché stai utilizzando solo due features. Ci sono altre features numeriche, o che possono diventare tali utilizzando il nodo category to number? Proverei ad aggiungerle. Ad esempio, utilizzando il genere potrebbe uscire fuori una clusterizzazione differente. In questo caso potresti adoperare, per la rappresentazione, il nodo scatter plot 3D.
Posso chiederti qual è l’obiettivo dell’analisi? Che inferenza, pensi, possa venire fuori dall’analisi dei dati a tua disposizione?
si tratta di un progetto scolastico e l’obiettivo dell’analisi riguarda in particolare capire l’analisi dei dati in particolare la clusterizzazione (eseguirla e trarre le considerazioni) ma ancora non ho molta dimestichezza con knime…anzi sono alle prime armi
ho scaricato da kaggle il dataset healthcare per poter provare tale analisi e questo è il risultato che ho ottenuto.
come sarebbe opportuno chiudere il workflow?
ah, ok. Rispondendo alla tua domanda, non c’è un modo particolare di chiudere l’analisi, perché dipende dagli obiettivi. Prova a dare un’occhiata a questo workflow che è costruito con lo stesso intento Determinazione del numero di cluster ottimale col punteggio Silhouette. Nota l’utilizzo di silhouette, per determinare il numero di cluster ottimale e del nodo PCA per rappresentare graficamente i dati nello spazio (permette di capire come e se sono separati). Nota anche il nodo Cluster assigner che permette di associare una osservazione ai cluster che hai determinato, dalle caratteristiche, tramite k-means.
Ti chiedevo degli obiettivi perché, a mio parere, sono quelli che permettono di impostare l’analisi (e non il contrario).
Fammi sapere.
Ciao
Francesco