Hello,
I’m looking for some clarifications as I’m super confused as how parameters are passed between workflows…
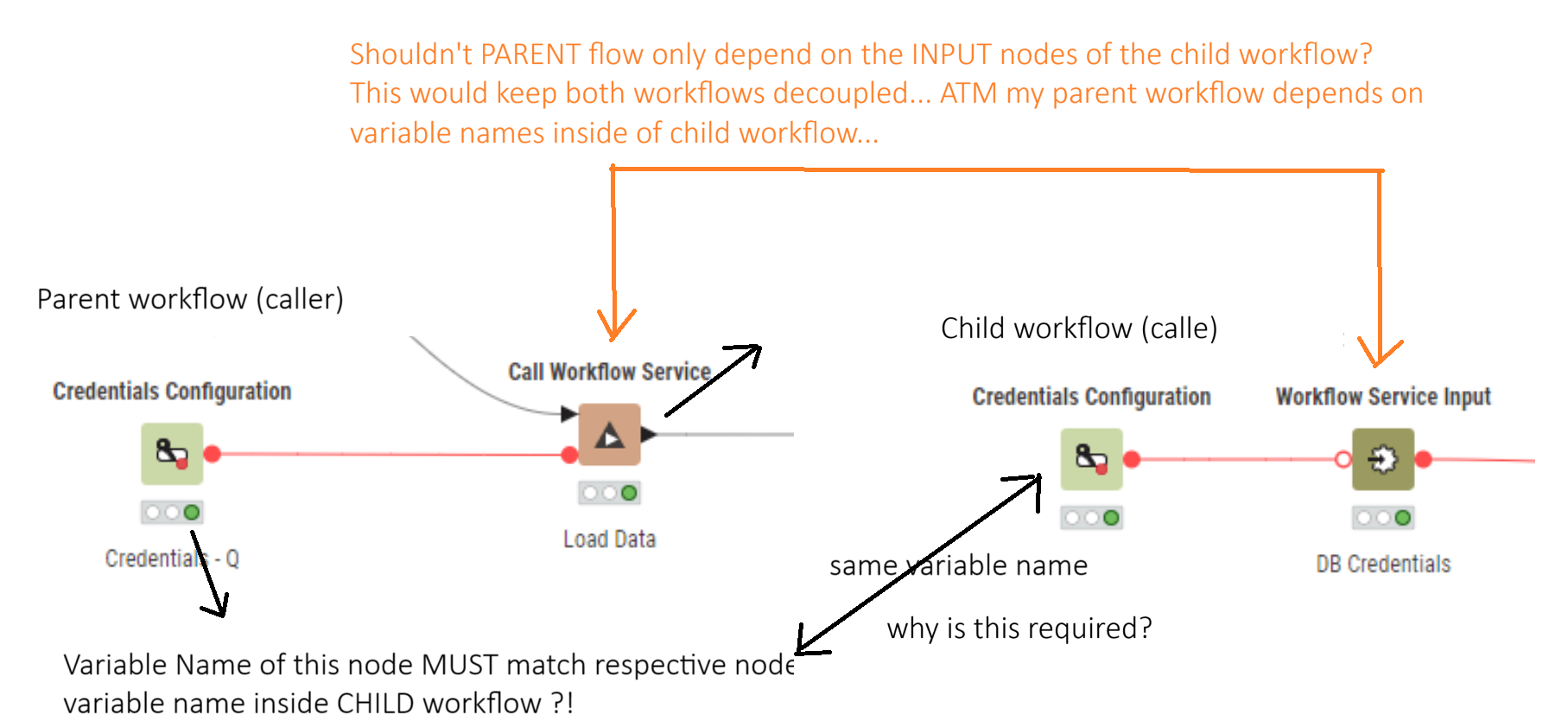
I was able to build a working Parent-Child workflow setup where I pass db credentials from parent workflow to child workflow. This looks like following:
My understanding was that the ‘Workflow Service Input’ nodes serves as boundary nodes keeping child workflow decoupled form parent AND also encapsulating child workflow so that Parent workflow only operates on the input nodes. However this does not seem to be the case. I’ve discovered that my workflows only work if parent workflows variable names match child’s workflow internal node’s variable names… Am I missing something here?
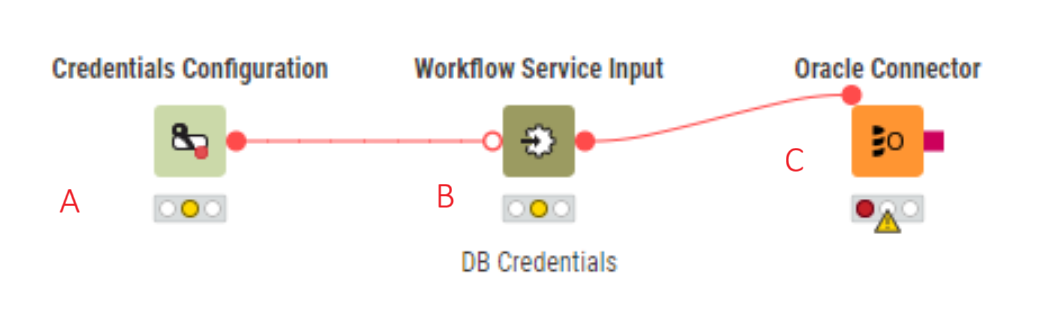
Additionally, I’m confused about the following setup:
In this example, when it comes to configuration of ‘Oracle Connector’ (C) I’m not able to select ‘Workflow Service Input’ (B) node as credential. I can only select the ‘Credentials Configuration’ (A). I would make a lot more sense if I was able to select the input node as credential source for db connector… Can someone help me understand it? (I guess the input node (B) overrides node (A) when called by parent workflow… this does seem to be the case but ONLY because the variables name (A) matches parent workflow input variable…
Anyway, it seems to me that now I have two way dependency between the two workflows (which makes it opposite of modular)…
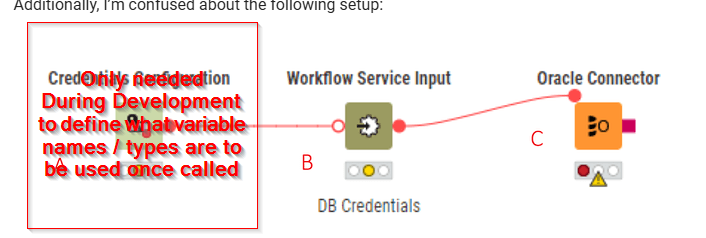
Inside your callable workflow, the only reason why you connect that Credentials Configuration (as per your example) or a table to Workflow Service Input is so that you can develop the workflow with the variable names you are passing into Call Workflow Service later and test it w/o having to actually call it. That’s also why after you have finished building your callable workflow, you can get rid of the input:
I get that you’ll now say that the difference is that you can pass into user and pwd whatever strings you like and you don’t have to create params user and pwd in your outside script, set them to whatever values and then pass these in (i.e. no matching is required), but I think with the general way that KNIME is designed the current way makes sense.
When you inspect a callable workflow you can check which variable names are required and same for tables and then you can make sure that they are passed through… I think especially on the table side it makes a lot of sense this way - on the variables side I think it makes somewhat sense to be consistent with how it works for tables…
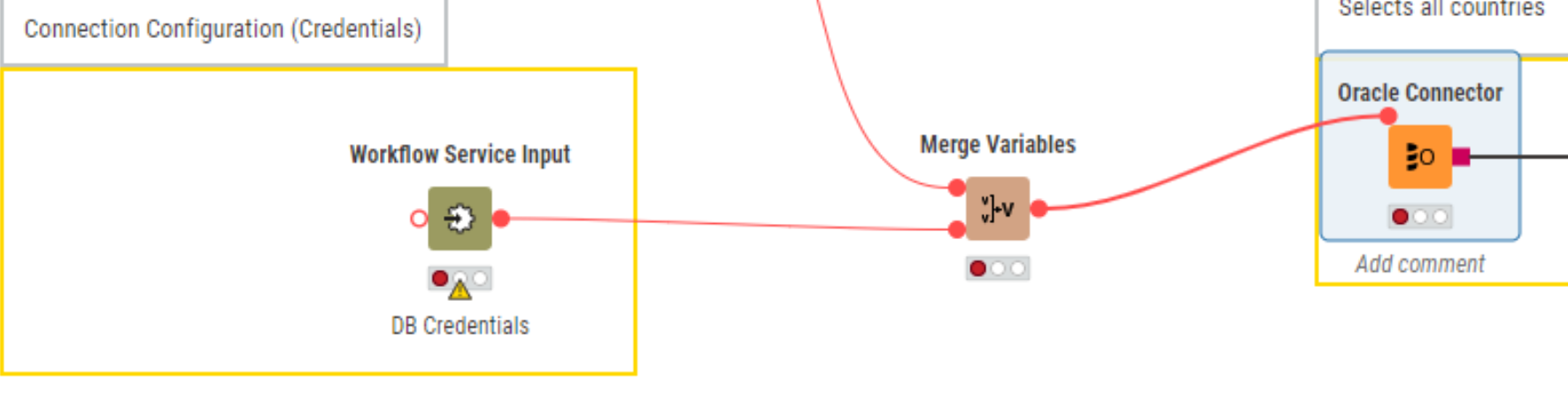
One further question - so let’s say the workflow (calle) is now complete and I delete this ‘Credentials Configuration’ node. My workflow now looks like this: