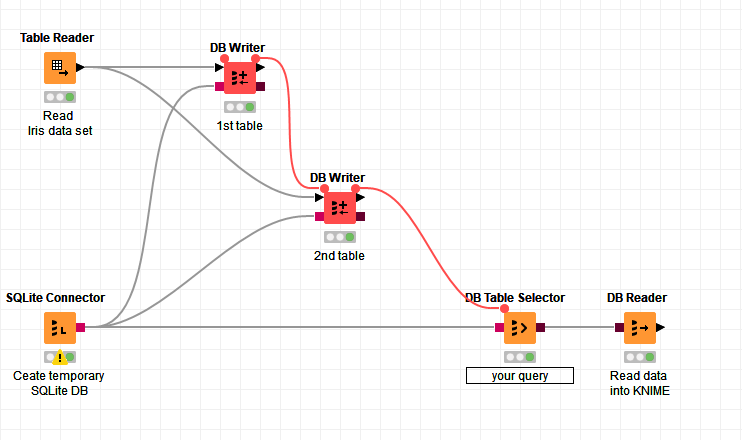
This workflow shows how to use workflow variable connections to control the execution order of nodes.
Note that the first top most meta node is used to define the location of the data base file depending on the current system. This is not necessary when writing to a "real" data base.
I’ve got the following question about this :
Imagine you have TWO Database writers, that have been executed in parallel, both filling up their own table.
They are followed by Database Executor, that joins those two tables from the preceding DB writers.
So
=> DB Wr1
=> DB Wr2 => DB Extr. : Obviously, I want this Executor to wait for BOTH Writers to finish.
Now I can only create a WfV connection from ONE of the two DB writers towards the DB Extr.
If I make a connection from Wr1 to the DB Extr., and then try to put a second one as well from Wr2, the
first one is dropped.
So if I have a connection between Wr1 and DB Extr., I don’t know how to force DBExtr to wait for Wr2 as well.
I tried to fix this by putting Wr1 and Wr2 together in a metanode, but that didn’t work as well.
Thx for the info. However, this blocks working in parallel.
Imagine fiirst en second table both take about an hour. If you can run them side by side, running both of them takes one hour. That was the reason for my question in the first place. Here, you’ll need two hours.
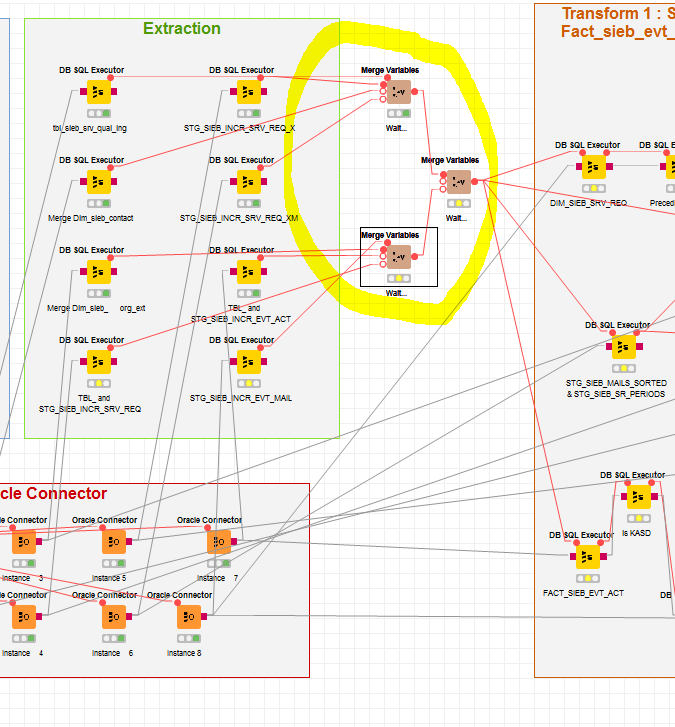
However, recently I have learned that for example the “Merge Variables” node can be used for that :