I have read two columns for excel. Applied create collection column, then in Java snipplet , I am reading the collection column as String array,
String ds = $first$;
String result = “”;
for (int i=0; i < ds.length; i++) {
result = “NOK”;
String d = ds[i].toUpperCase();
if (d.equals(“INCIDENT”)) {
result = ds[i+1];
}
}
return result;
There is no result that is returning.
Basically if value of one particular row = “xxx” i want to return next row back.
as far as i understand you are combining two columns and aggregate them into a collection column. The problem with your Snippet is that your index variable “i” does not represent the current row number but instead the index of the column position within the array.
I think you could use the Lag Column Node on the column or collection in question. Use Lag/Lag Interval = 1.
Then filter the row (using the JavaScript RowFilter or the RuleEngine RowFilter) on the lagged column, whenever you encounter the “INCIDENT” value. This way you should keep the succeeding rows.
Let me know if my explanation is not clear to you.
Hello, working on an array solution myself and noticed this thread here, your question sounds like you may want to check out a different node (row split) and not the lag column node.
Skipping rows is an interesting thing that can be done many ways.
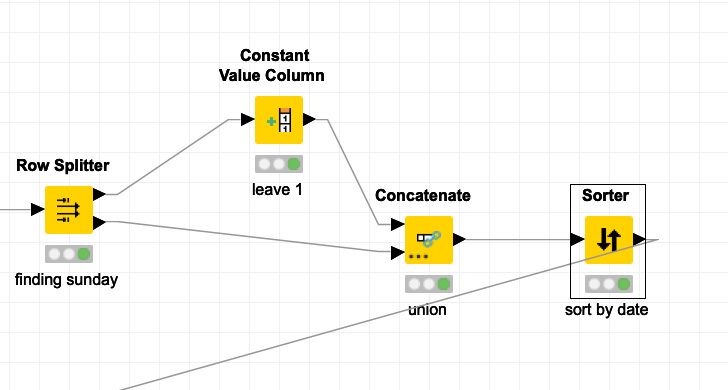
If you want to skip incident, I recommend learning about the row splitter tool. It allows you to split out anything where incident is found, now you have an opportunity to label this row with say… a constant value, to then be used to easily filter out this value if needed. and you can union it back together and consider this a classification of the incident row, or rows.
In other words, filtering out incident will allow you to skip it. I like row splitter because it lets me do interesting things.
Sort helps if you need to keep similar stack of data as sometimes your process may need a certain order of things depending on how you’re running your process, which is why ive left a little more color into why i use row splitter.
 as sometimes your process may need a certain order of things depending on how you’re running your process, which is why ive left a little more color into why i use row splitter.
as sometimes your process may need a certain order of things depending on how you’re running your process, which is why ive left a little more color into why i use row splitter.