I have few json files and after using JSON Path (Collection query) and ungrouping the data, I realized that the data is spread across hundreds of columns with similar names i.e. CodeSystem (#1), CodeSystem (#N). I am filtering those columns using Rule-based Row splitter but I need to provide TRUE condition /statement for all those hundred columns. I am wondering if there is a way that I can use (Regex ?) to tell KNIME to extract data from all those columns which follow a certain naming patterns and have a TRUE condition ? Is there an efficient way ?
the list of your column names points to an array structure. Isn’t the data in JSON file structured in an array? An array could be transformed in columns and rows. Could you provide a sample JSON file?
this is a very unfortunate JSON structure that was produced. Where arrays could be used, for example in the text data, they have not been used. Elsewhere, arrary structures and nonarray structures are mixed, as with the code and translation structures, so the individual data does not extract through the use of JSON Path nodes.
An alternative is to convert the JSON file to an XML file, as this eliminates some of the above problems.
A possible solution can be found here:
I’ve deleted the personal information in the JSON File.
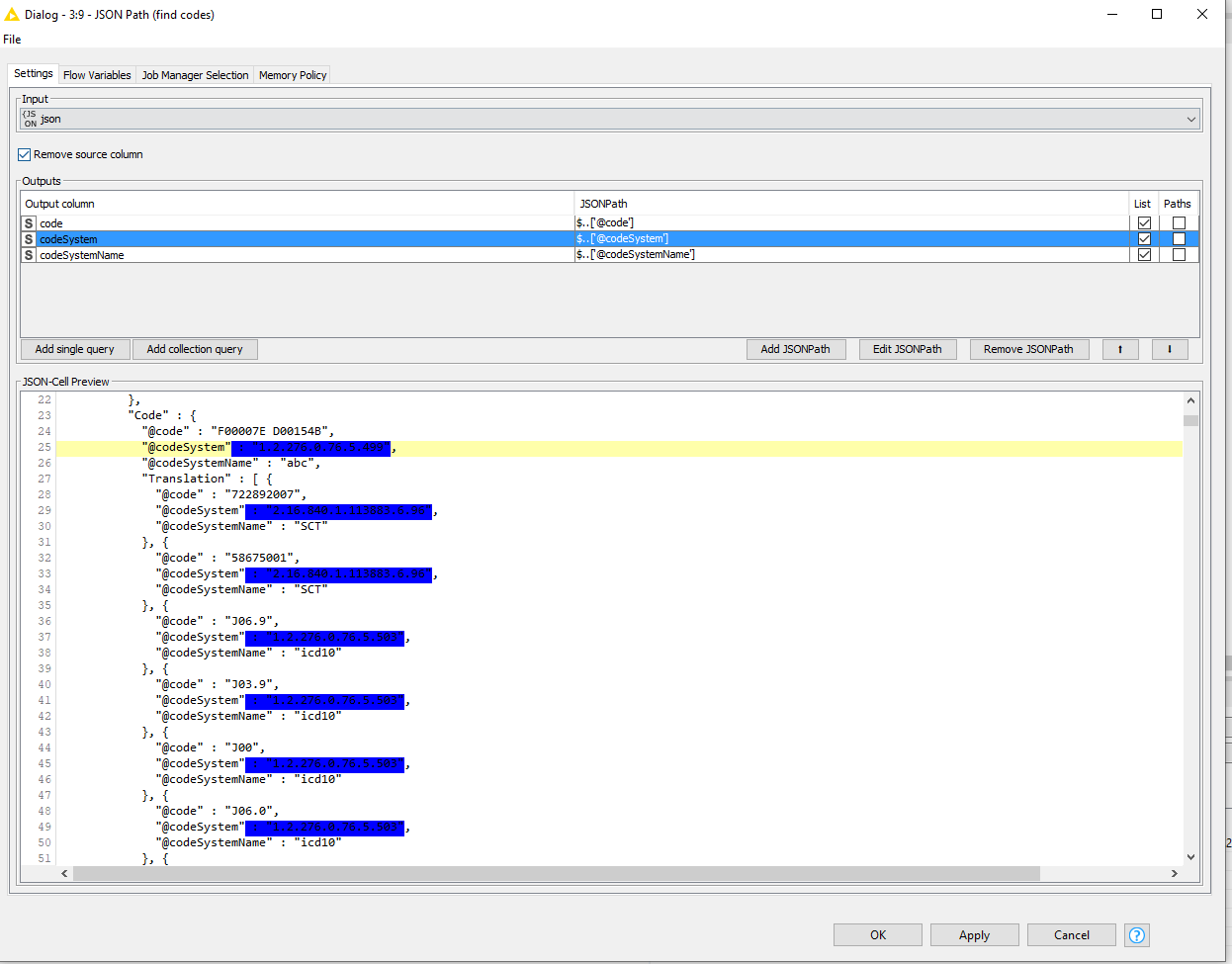
In case @mateenraj just wants to filter on individual codesystemName types like he indicates and does not require the parent codesystemName, it’s possible in this case with JSONPath. But I had the exact same thoughts regarding the file being quite weird and it took some time to figure it out. I approached it with full wildcard in the JSON Path and have them outputted as Lis direct.
With query $..['@code'] the node essentially extracts all data with has @code as name. Similar approach with the other two ($..['@codeSystem'] and $..['@codeSystemName'])
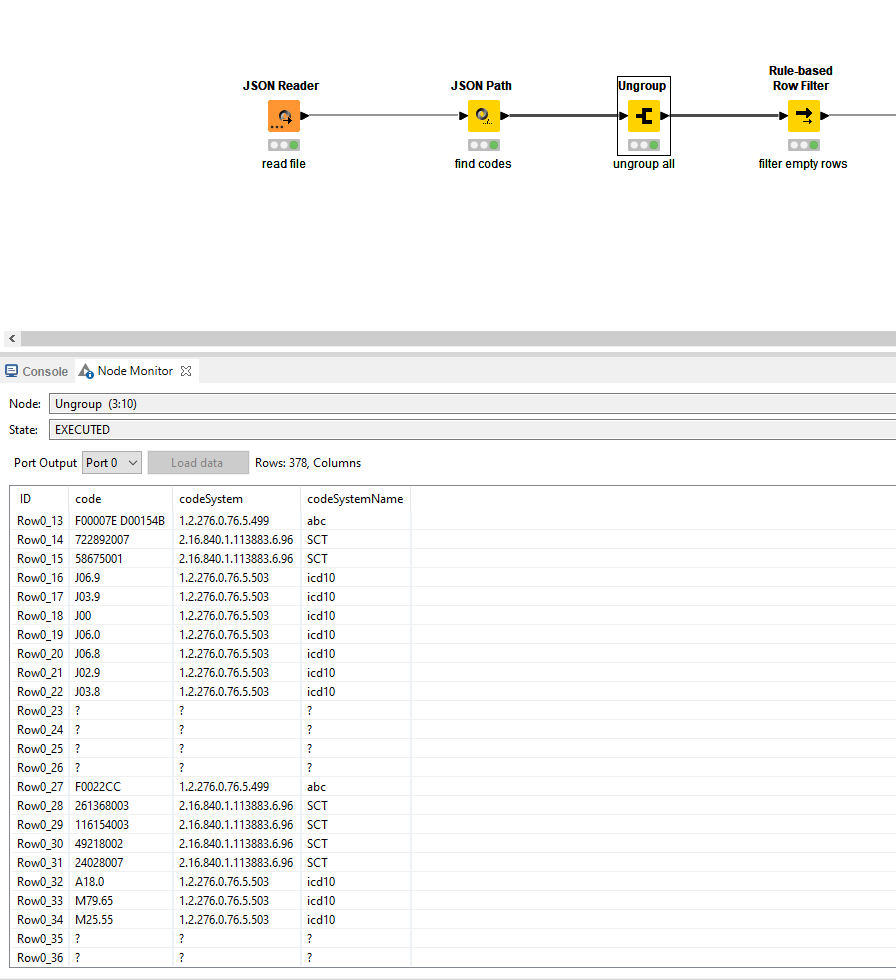
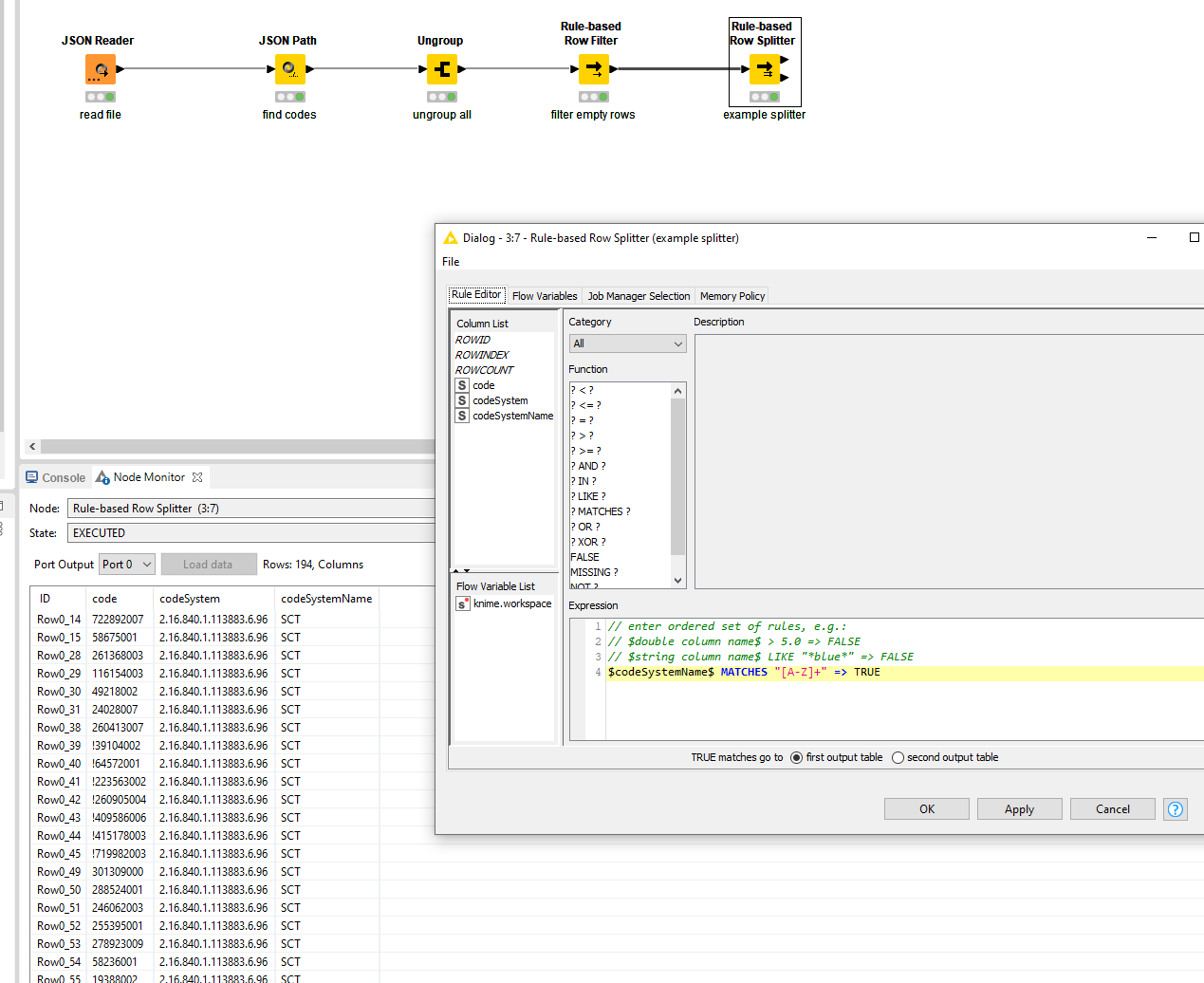
Added an empty row filter to take out the nulls results in a full list. Directly followed by the Rule-Based Row Splitter that @mateenraj intended to use.
Many thanks, had a quick look and it looks good. The output was actually XML but I transformed it into JSON as I found it easy to work with JSON.
The clinical data is publicly available and most likely it’s fake: https://www.imed-komm.eu/node/735