I’m now searching nodes to do the following data operations.
Not sure whether it can be done and how it can be done in KNIME.
Maybe it’s a little special, so I describe it in detail
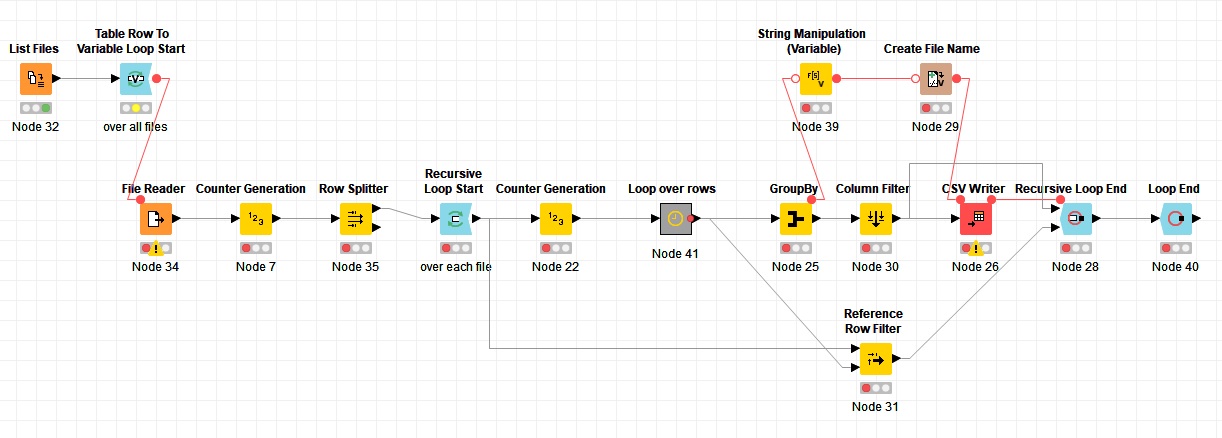
Firstly, read multiple CSV files into a loop.
These CSV are time-series data, containing a column “Data” whose value are from 0 to 1000.
Operations in the loop, which is the important part,
read the 1st. CSV file.
Write the data row by row to 3 different CSV files, based on the following rule.
if “Data” exceed the value 200 for the first time, start to write the row to CSV file1.
if “Data” underrun the value 200 for the first time, end to write the row to CSV file1.
if “Data” exceed the value 200 for the second time, start to write the row to CSV file2.
if “Data” underrun the value 200 for the second time, end to write the row to CSV file2.
if “Data” exceed the value 200 for the third time, start to write the row to CSV file3.
if “Data” underrun the value 200 for the third time, end to write the row to CSV file3.
Go to the next loop (next CSV) if all the rows have been operated.
I think I need to create anther loop inside the CSV read loop, in order to handle the row operation for each csv, but don’t know how to do this.
I’m also confusing how to separate the CSV writer based on a paticular value-based rule.
How to end the loop after the loop been seperated to three branch.
Could anyone provide any advice as to how to create this kind of workflow?
Do you want to have the output of all the your CSV files be divided into 3 files or each one of the CSV files should be divided into 3 files separately?
I need to have the output of each one of the CSV be divided into 3 files.
So I think it’s not necessary to merge all the CSV files.
Read the CSV file one by one in the 1st. loop, and in this loop operate row by row?
Actually each CSV file contains three part of the data. This workflow is created to separate the three part to three file groups, while how to separate them is depending by the column value because they are time-series data.
Really glad to know KNIME can do this, and seemed not very complex.
But the workflow still has many advanced stuff (for me) , I’m going to learn it by running it with my really data.
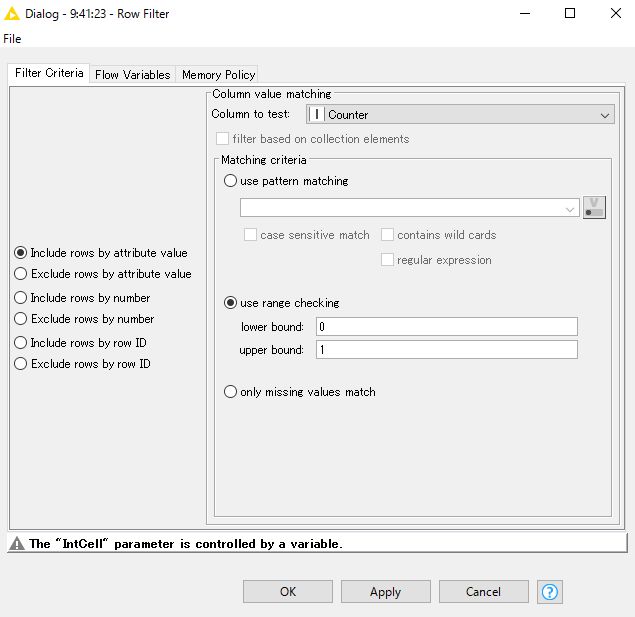
I disabled the first Counter-Generation node to use my data column, and then the Row Filter inside the “loop over rows” metanode throw out a error “Column range filter: Input table doesn’t contain specified column name”.
Just click OK on the configuration window after you have open it and the problem is solved.
That error is because of the changed configurations and as soon as you open and and save the new config the problem is solved.
Right! just one click, now it’s worked!
That was stupid to click Cancel every time like a habit…
There are many nodes I never used before. They are new to me, and to learn their function seems so exciting!
I will try to make some change after I understand how all the nodes are working.
Thanks again!
BTW, I just downloaded and installed KNIME 3.7.2 to my laptop yesterday. Then I found KNIME 4.0 released this morning. The update comes so quickly
I’m not sure about how to use the Rule-based Row Filter in the metal node…
In this workflow, I consider the “counter” variable (from the 1st. Counter Generation) should be set as my target data.
So I tried to change the expression of Math Formula (Variable) before the Rule-based Row Filter node from:
$${ICounter}$$ + 1
to:
$${DPV_3}$$) + 0.1
“PV_3” is my actual data column name and it’s double (real) value, increasing pitch is 0.1.
Then in the Rule-based Row Filter, I changed the expression from:
$Counter$ = $${ICounter}$$ OR $Counter$ = $${Dcounter+1}$$ => TRUE
to:
$PV_3$ = $${DPV_3}$$ OR $PV_3$ = $${DPV_3+0.1}$$ => TRUE
This change seems not successful.
The loop ended at the 1st. row since the Rule-based Row Filter outputted one row table.
Could you imagine where is my mistake?
Please let me know if you need further information, thanks!
Check outputs and you will find out where the problem is.
Check the variables after the Math Formula (Variable) and the data table after Row filter in each loop iteration. Run the Rule-based Row Filter node and check the outputs I mentioned.
Regarding the information you have provided here, there shouldn’t be any problem and if the loop in the Metanode ends at the first row, I guess that the first row in your table is the only group member in the first group which has the conditions. If it’s not, then check the outputs as I said and if you cannot find the problem, upload a sample data and your workflow here and I’ll check it.
The file reader throws out an error after I normalized some part of the data. I use CSV reader instead of it…
You can find PV_3 at the final data column. They are real data. The threshold is 191 (instead of 200).
BTW, is it possble to write the result file to three different folders?,
I thought I could do this in the next workflow but it will need more running time. ( too many files to be operated…), maybe it’s simple to be done at this workflow?
The PV_3 column is not an appropriate alternative to replace the counter column I used. Using the counter column, I had integers with the same interval increasing row by row. The PV_3 column has values in different intervals between rows and also negative and positive intervals (sometimes increases and sometimes decreases).
Follow my first original workflow and do not replace the Counter Generators.
Yes, it’s possible. You can create different location addresses (based on file name or loop iteration number) using flow variables and use them in Create File Name node as “Selected Directory”.
I made a mistake. PV_3 is my actual target data, from 190 ~ 220, real type, sometimes increases and sometimes decreases. It should replace the “Data” in this workflow, not the Counter.
Will continue to look into the running of this workflow ~








 ), maybe it’s simple to be done at this workflow?
), maybe it’s simple to be done at this workflow?


