Hi @ChrMavrom , when I read your post, I was thinking that you are trying to write from a data source outside of Snowflake, into Snowflake, in which case you would have to use a DB Reader to bring the data into KNIME from where it could then be passed to Snowflake.
However, in looking at your workflow, I believe that all of your data resides in a single Snowflake database, and you are using KNIME to perform the required transformations. Is that correct?
If that is the case, then you can remove the DB Reader and perform the bulk of the data operations within Snowflake, without the data having to be returned to KNIME.
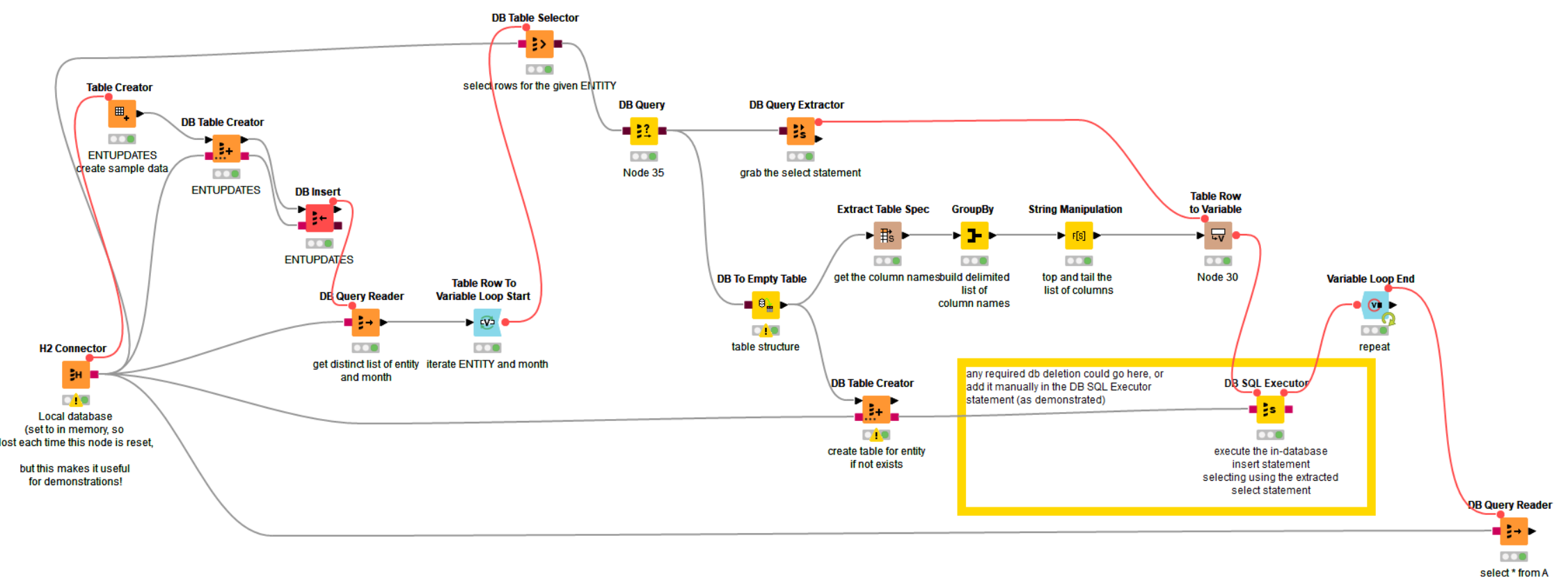
I cannot view the config of your workflow, because I cannot execute it (it relies on your snowflake connection). If you’d been able to upload a working example using an alternative database such as the built in H2 database, then it would have been simpler to assist but instead I’ve made up a workflow to demonstrate the principle.
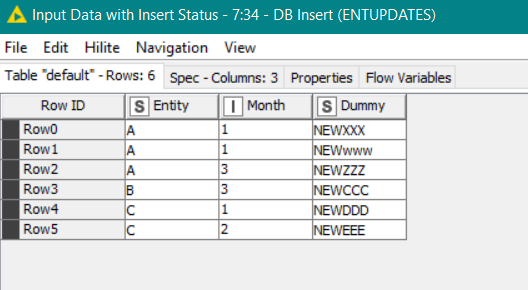
In this workflow, a sample database table “ENTUPDATES” is accessed.
From this table, a query returns the distinct set of Entity and Month and then this is iterated on with the loop.
The DB Query node is used to supply the query for the database
SELECT "Entity", "Month","Dummy"FROM #table#
But this is not directly used in a DB Reader. Instead, it is used to provide the required table structure to the DB to Empty Table node, and the query itself is extracted by the DB Query Extractor node.
In my workflow, I am creating a table (if it doesn’t exist) with the name of the entity. So at the end I’ll have additional tables A,B,C.
The table structure from the DB to Empty Table node is used as the basis for the DB Table Creator in the same way that the DB Reader in you workflow operated.
There is a word of caution here. By default the DB Table Creator defines string columns as varchar(255), so somebody using this technique could hit problems unless they take steps to change the Type defaults. However, for Snowflake this is should be irrelevant, since Snowflake creates every varchar column as 16MB in size regardless of what you tell it 
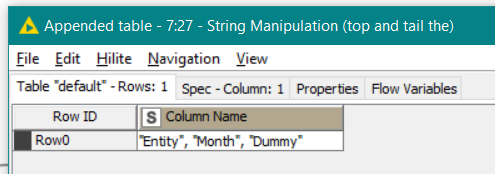
Meanwhile the list of columns is extracted from the DB to Empty Table node, by the the Extract Table Spec node. This is then turned into a delimited list, so in this case the columns
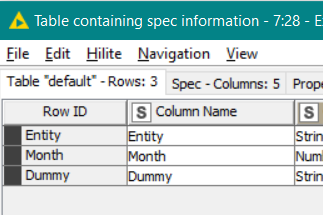
become the list:
On a given iteration, the DB Query Extractor extracts the sql for the query:
SELECT "Entity", "Month","Dummy"FROM (SELECT * FROM "PUBLIC"."ENTUPDATES"
where "Entity" = 'C'
and "Month" = 2
)
This is then combined along with the delimited string of columns into an Insert statement in the DB SQL Executor:
delete from $${SEntity}$$
where "Entity" = '$${SEntity}$$' and "Month" = $${IMonth}$$;
insert into $${SEntity}$$ ($${SColumn Name}$$)
$${Ssql}$$
Here I’ve demonstrated including the delete statement inside the Executor, but you could put it outside in the DB Delete (Filter) node as you had in your workflow.
The important thing here is the insert statement. This will get transformed at run time into the following:
insert into "A" ("Entity", "Month", "Dummy")
SELECT "Entity", "Month","Dummy"FROM (SELECT * FROM "PUBLIC"."ENTUPDATES"
where "Entity" = 'C'
and "Month" = 2
)
so the whole insert will take place in-database, rather than returning the data to KNIME and then writing back out.
DB demo 20240120.knwf (51.6 KB)