Hi everyone, I’m struggling to get the encoding right in my web text scraping task. I want to make sure UTF-8 is being used throughout the whole workflow.
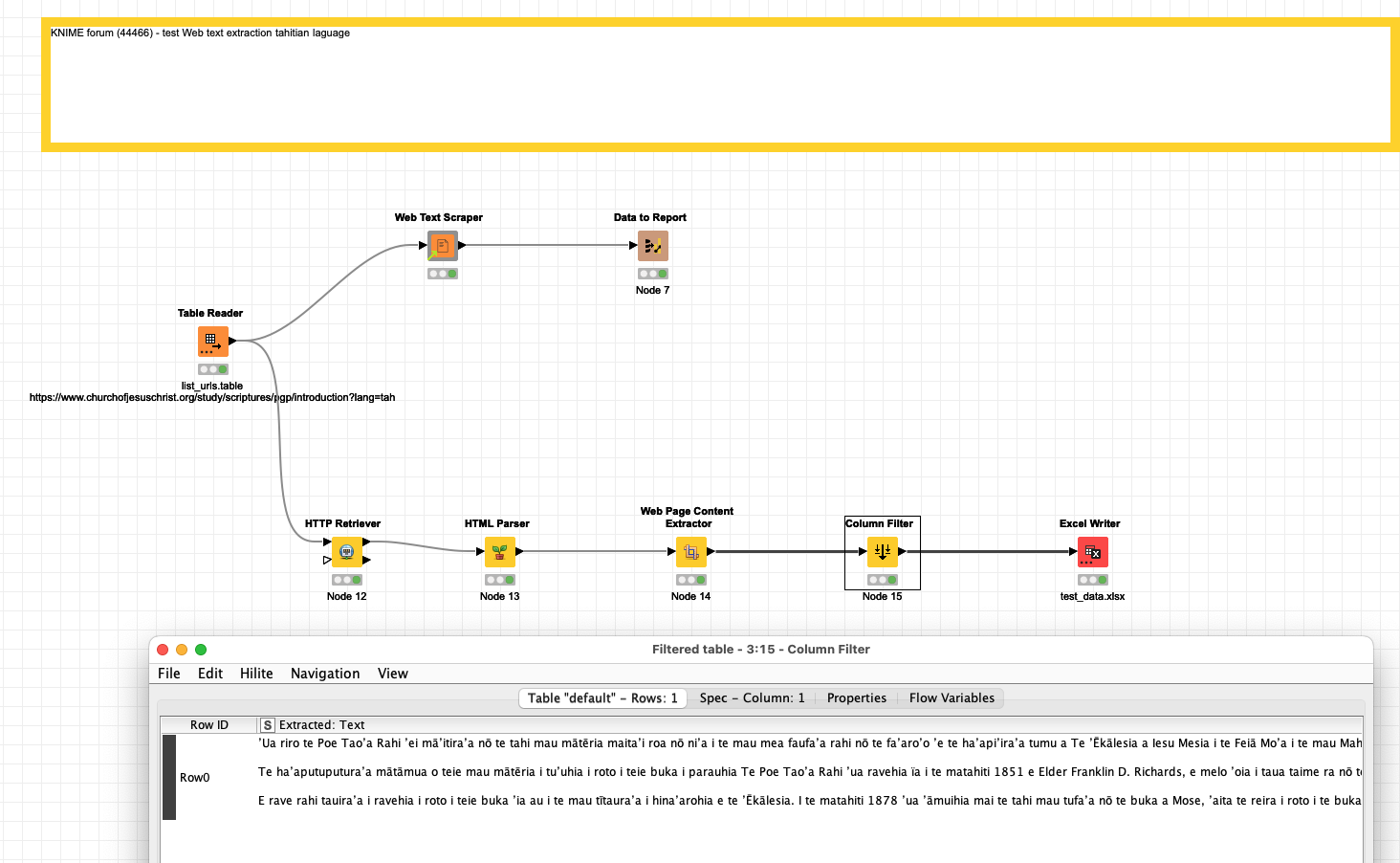
I’m using component Web Text Scraper which uses a Java based library called BoilerPipe and the output text is fine when the language is in English. However, the same task with a different language will result in characters not displayed properly.
You’ll typically need to detect the encoding based on the input data (i.e. specified by the website). For example Asian language websites will often not use UTF-8 encoding.
Therefore, in the Palladian nodes, we have quite some “magic” to detect the encoding (based on explicitly given tags and headers and some heuristics of these do not exist) of a website and then to decode it properly. So, as an alternative solution, you might want to look at the following combo:
@HURIMOZ this UTF-8 seems to be a variable. I don’t think this is the point where you can set something. You could try and let the variable thru by disconnecting the component from the source but I doubt it will make a difference.
Could you provide some sample file or workflow where this happens so one might investigate.
@HURIMOZ I think with the suggested Palladian nodes you might be able to extract the data with a good encoding. The Java package you are using seems to be focussed on english language content. There are some discussions about using other languages also, but the settings were not immediately obvious.