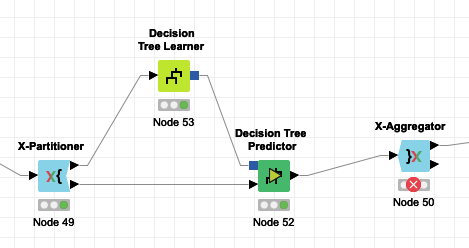
I get this error message when trying to execute my workflow: “Execute failed: Input table’s structure differs from reference (first iteration) table: different column counts”
This only occurs when I tick “Append columns with normalized class distribution” in the Decision Tree Predictor. If I don’t click this option it works perfectly fine. I leave all the other settings unchanged.
How can I solve this and what is the reason behind this error?
I am really looking forward to your help!
The error message tells you what’s wrong. Your input table contains a different number of columns compared to the result of the first iteration.
As you say in your post, when you tell the decision tree predictor node to add a column, then error appears. When you disable this option, the error goes away.
It’s all consistent.
If you’re doing cross-partitioning, why do you need to add the class distributions?